 支持向量机及Python代码实现.docx
支持向量机及Python代码实现.docx
- 文档编号:9614638
- 上传时间:2023-02-05
- 格式:DOCX
- 页数:28
- 大小:474.06KB
支持向量机及Python代码实现.docx
《支持向量机及Python代码实现.docx》由会员分享,可在线阅读,更多相关《支持向量机及Python代码实现.docx(28页珍藏版)》请在冰豆网上搜索。
支持向量机及Python代码实现
支持向量机及Python代码实现
做机器学习的一定对支持向量机(supportvectormachine-SVM)颇为熟悉,因为在深度学习出现之前,SVM一直霸占着机器学习老大哥的位子。
他的理论很优美,各种变种改进版本也很多,比如latent-SVM,structural-SVM等。
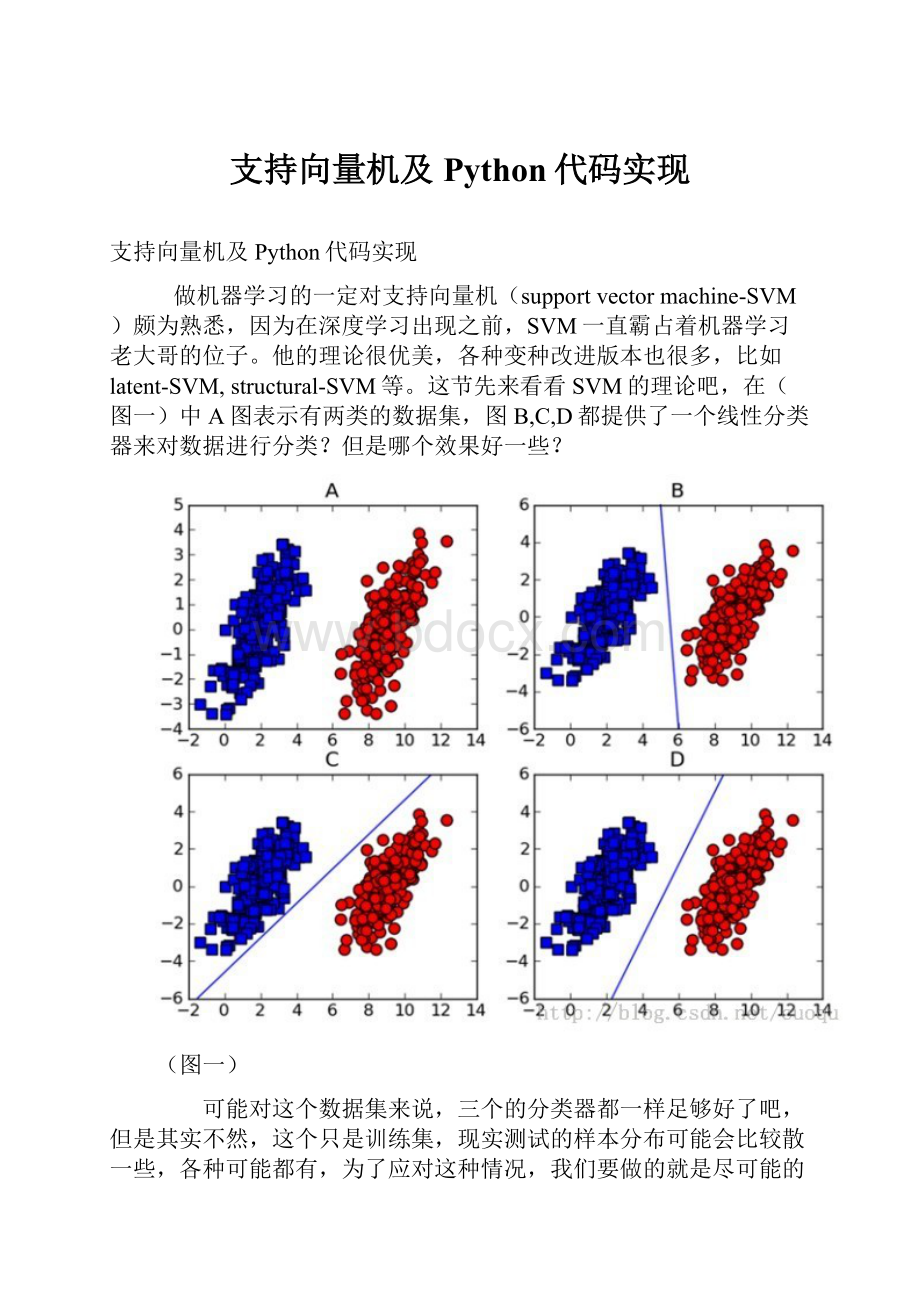
这节先来看看SVM的理论吧,在(图一)中A图表示有两类的数据集,图B,C,D都提供了一个线性分类器来对数据进行分类?
但是哪个效果好一些?
(图一)
可能对这个数据集来说,三个的分类器都一样足够好了吧,但是其实不然,这个只是训练集,现实测试的样本分布可能会比较散一些,各种可能都有,为了应对这种情况,我们要做的就是尽可能的使得线性分类器离两个数据集都尽可能的远,因为这样就会减少现实测试样本越过分类器的风险,提高检测精度。
这种使得数据集到分类器之间的间距(margin)最大化的思想就是支持向量机的核心思想,而离分类器距离最近的样本成为支持向量。
既然知道了我们的目标就是为了寻找最大边距,怎么寻找支持向量?
如何实现?
下面以(图二)来说明如何完成这些工作。
(图二)
假设(图二)中的直线表示一个超面,为了方面观看显示成一维直线,特征都是超面维度加一维度的,图中也可以看出,特征是二维,而分类器是一维的。
如果特征是三维的,分类器就是一个平面。
假设超面的解析式为
,那么点A到超面的距离为
下面给出这个距离证明:
(图三)
在(图三)中,青色菱形表示超面,Xn为数据集中一点,W是超面权重,而且W是垂直于超面的。
证明垂直很简单,假设X’和X’’都是超面上的一点,
因此W垂直于超面。
知道了W垂直于超面,那么Xn到超面的距离其实就是Xn和超面上任意一点x的连线在W上的投影,如(图四)所示:
(图四)
而(Xn-X)在W上的投影
可通过(公式一)来计算,另外(公式一)也一并完成距离计算:
(公式一)
注意最后使用了配项法并且用了超面解析式
才得出了距离计算。
有了距离就可以来推导我们刚开始的想法:
使得分类器距所有样本距离最远,即最大化边距,但是最大化边距的前提是我们要找到支持向量,也就是离分类器最近的样本点,此时我们就要完成两个优化任务,找到离分类器最近的点(支持向量),然后最大化边距。
如(公式二)所示:
(公式二)
大括号里面表示找到距离分类超面最近的支持向量,大括号外面则是使得超面离支持向量的距离最远,要优化这个函数相当困难,目前没有太有效的优化方法。
但是我们可以把问题转换一下,如果我们把大括号里面的优化问题固定住,然后来优化外面的就很容易了,可以用现在的优化方法来求解,因此我们做一个假设,假设大括号里的分子
等于1,那么我们只剩下优化W咯,整个优化公式就可以写成(公式三)的形式:
(公式三)
这下就简单了,有等式约束的优化,约束式子为
,这个约束等式背后还有个小窍门,假设我们把样本Xn的标签设为1或者-1,当Xn在超面上面(或者右边)时,带入超面解析式得到大于0的值,乘上标签1仍然为本身,可以表示离超面的距离;当Xn在超面下面(或者左边)时,带入超面解析式得到小于0的值,乘上标签-1也是正值,仍然可以表示距离,因此我们把通常两类的标签0和1转换成-1和1就可以把标签信息完美的融进等式约束中,(公式三)最后一行也体现出来咯。
下面继续说优化求解(公式四)的方法,在最优化中,通常我们需要求解的最优化问题有如下几类:
(i)无约束优化问题,可以写为:
minf(x);
(ii)有等式约束的优化问题,可以写为:
minf(x),
s.t.h_i(x)=0;i=1,...,n
(iii)有不等式约束的优化问题,可以写为:
minf(x),
s.t.g_i(x)<=0;i=1,...,n
h_j(x)=0;j=1,...,m
对于第(i)类的优化问题,常常使用的方法就是Fermat定理,即使用求取f(x)的导数,然后令其为零,可以求得候选最优值,再在这些候选值中验证;如果是凸函数,可以保证是最优解。
对于第(ii)类的优化问题,常常使用的方法就是拉格朗日乘子法(LagrangeMultiplier),即把等式约束h_i(x)用一个系数与f(x)写为一个式子,称为拉格朗日函数,而系数称为拉格朗日乘子。
通过拉格朗日函数对各个变量求导,令其为零,可以求得候选值集合,然后验证求得最优值。
对于第(iii)类的优化问题,常常使用的方法就是KKT条件。
同样地,我们把所有的等式、不等式约束与f(x)写为一个式子,也叫拉格朗日函数,系数也称拉格朗日乘子,通过一些条件,可以求出最优值的必要条件,这个条件称为KKT条件。
而(公式三)很明显符合第二类优化方法,因此可以使用拉格朗日乘子法来对其求解,在求解之前,我们先对(公式四)做个简单的变换。
最大化||W||的导数可以最小化||W||或者W’W,如(公式四)所示:
(公式四)
套进拉格朗日乘子法公式得到如(公式五)所示的样子:
(公式五)
在(公式五)中通过拉格朗日乘子法函数分别对W和b求导,为了得到极值点,令导数为0,得到
,然后把他们代入拉格朗日乘子法公式里得到(公式六)的形式:
(公式六)
(公式六)后两行是目前我们要求解的优化函数,现在只需要做个二次规划即可求出alpha,二次规划优化求解如(公式七)所示:
(公式七)
通过(公式七)求出alpha后,就可以用(公式六)中的第一行求出W。
到此为止,SVM的公式推导基本完成了,可以看出数学理论很严密,很优美,尽管有些同行们认为看起枯燥,但是最好沉下心来从头看完,也不难,难的是优化。
二次规划求解计算量很大,在实际应用中常用SMO(Sequentialminimaloptimization)算法,SMO算法打算放在下节结合代码来说。
参考文献:
[1]machinelearninginaction.PeterHarrington
[2]LearningFromData.YaserS.Abu-Mostafa
上节基本完成了SVM的理论推倒,寻找最大化间隔的目标最终转换成求解拉格朗日乘子变量alpha的求解问题,求出了alpha即可求解出SVM的权重W,有了权重也就有了最大间隔距离,但是其实上节我们有个假设:
就是训练集是线性可分的,这样求出的alpha在[0,infinite]。
但是如果数据不是线性可分的呢?
此时我们就要允许部分的样本可以越过分类器,这样优化的目标函数就可以不变,只要引入松弛变量
即可,它表示错分类样本点的代价,分类正确时它等于0,当分类错误时
,其中Tn表示样本的真实标签-1或者1,回顾上节中,我们把支持向量到分类器的距离固定为1,因此两类的支持向量间的距离肯定大于1的,当分类错误时
肯定也大于1,如(图五)所示(这里公式和图标序号都接上一节)。
(图五)
这样有了错分类的代价,我们把上节(公式四)的目标函数上添加上这一项错分类代价,得到如(公式八)的形式:
(公式八)
重复上节的拉格朗日乘子法步骤,得到(公式九):
(公式九)
多了一个Un乘子,当然我们的工作就是继续求解此目标函数,继续重复上节的步骤,求导得到(公式十):
(公式十)
又因为alpha大于0,而且Un大于0,所以0 推导到现在,优化函数的形式基本没变,只是多了一项错分类的价值,但是多了一个条件,0 接下来的步骤貌似大家都应该知道了,多了一个C常量的限制条件,然后继续用SMO算法优化求解二次规划,但是我想继续把核函数也一次说了,如果样本线性不可分,引入核函数后,把样本映射到高维空间就可以线性可分,如(图六)所示的线性不可分的样本: (图六) 在(图六)中,现有的样本是很明显线性不可分,但是加入我们利用现有的样本X之间作些不同的运算,如(图六)右边所示的样子,而让f作为新的样本(或者说新的特征)是不是更好些? 现在把X已经投射到高维度上去了,但是f我们不知道,此时核函数就该上场了,以高斯核函数为例,在(图七)中选几个样本点作为基准点,来利用核函数计算f,如(图七)所示: (图七) 这样就有了f,而核函数此时相当于对样本的X和基准点一个度量,做权重衰减,形成依赖于x的新的特征f,把f放在上面说的SVM中继续求解alpha,然后得出权重就行了,原理很简单吧,为了显得有点学术味道,把核函数也做个样子加入目标函数中去吧,如(公式十一)所示: (公式十一) 其中K(Xn,Xm)是核函数,和上面目标函数比没有多大的变化,用SMO优化求解就行了,代码如下: [python] viewplaincopy 1.def smoPK(dataMatIn, classLabels, C, toler, maxIter): #full Platt SMO 2. oS = optStruct(mat(dataMatIn),mat(classLabels).transpose(),C,toler) 3. iter = 0 4. entireSet = True; alphaPairsChanged = 0 5. while (iter < maxIter) and ((alphaPairsChanged > 0) or (entireSet)): 6. alphaPairsChanged = 0 7. if entireSet: #go over all 8. for i in range(oS.m): 9. alphaPairsChanged += innerL(i,oS) 10. print "fullSet, iter: %d i: %d, pairs changed %d" % (iter,i,alphaPairsChanged) 11. iter += 1 12. else: #go over non-bound (railed) alphas 13. nonBoundIs = nonzero((oS.alphas.A > 0) * (oS.alphas.A < C))[0] 14. for i in nonBoundIs: 15. alphaPairsChanged += innerL(i,oS) 16. print "non-bound, iter: %d i: %d, pairs changed %d" % (iter,i,alphaPairsChanged) 17. iter += 1 18. if entireSet: entireSet = False #toggle entire set loop 19. elif (alphaPairsChanged == 0): entireSet = True 20. print "iteration number: %d" % iter 21. return oS.b,oS.alphas 下面演示一个小例子,手写识别。 (1)收集数据: 提供文本文件 (2)准备数据: 基于二值图像构造向量 (3)分析数据: 对图像向量进行目测 (4)训练算法: 采用两种不同的核函数,并对径向基函数采用不同的设置来运行SMO算法。 (5)测试算法: 编写一个函数来测试不同的核函数,并计算错误率 (6)使用算法: 一个图像识别的完整应用还需要一些图像处理的只是,此demo略。 完整代码如下: [python] viewplaincopy 1.from numpy import * 2.from time import sleep 3. 4.def loadDataSet(fileName): 5. dataMat = []; labelMat = [] 6. fr = open(fileName) 7. for line in fr.readlines(): 8. lineArr = line.strip().split('\t') 9. dataMat.append([float(lineArr[0]), float(lineArr[1])]) 10. labelMat.append(float(lineArr[2])) 11. return dataMat,labelMat 12. 13.def selectJrand(i,m): 14. j=i #we want to select any J not equal to i 15. while (j==i): 16. j = int(random.uniform(0,m)) 17. return j 18. 19.def clipAlpha(aj,H,L): 20. if aj > H: 21. aj = H 22. if L > aj: 23. aj = L 24. return aj 25. 26.def smoSimple(dataMatIn, classLabels, C, toler, maxIter): 27. dataMatrix = mat(dataMatIn); labelMat = mat(classLabels).transpose() 28. b = 0; m,n = shape(dataMatrix) 29. alphas = mat(zeros((m,1))) 30. iter = 0 31. while (iter < maxIter): 32. alphaPairsChanged = 0 33. for i in range(m): 34. fXi = float(multiply(alphas,labelMat).T*(dataMatrix*dataMatrix[i,: ].T)) + b 35. Ei = fXi - float(labelMat[i])#if checks if an example violates KKT conditions 36. if ((labelMat[i]*Ei < -toler) and (alphas[i] < C)) or ((labelMat[i]*Ei > toler) and (alphas[i] > 0)): 37. j = selectJrand(i,m) 38. fXj = float(multiply(alphas,labelMat).T*(dataMatrix*dataMatrix[j,: ].T)) + b 39. Ej = fXj - float(labelMat[j]) 40. alphaIold = alphas[i].copy(); alphaJold = alphas[j].copy(); 41. if (labelMat[i] ! = labelMat[j]): 42. L = max(0, alphas[j] - alphas[i]) 43. H = min(C, C + alphas[j] - alphas[i]) 44. else: 45. L = max(0, alphas[j] + alphas[i] - C) 46. H = min(C, alphas[j] + alphas[i]) 47. if L==H: print "L==H"; continue 48. eta = 2.0 * dataMatrix[i,: ]*dataMatrix[j,: ].T - dataMatrix[i,: ]*dataMatrix[i,: ].T - dataMatrix[j,: ]*dataMatrix[j,: ].T 49. if eta >= 0: print "eta>=0"; continue 50. alphas[j] -= labelMat[j]*(Ei - Ej)/eta 51. alphas[j] = clipAlpha(alphas[j],H,L) 52. if (abs(alphas[j] - alphaJold) < 0.00001): print "j not moving enough"; continue 53. alphas[i] += labelMat[j]*labelMat[i]*(alphaJold - alphas[j])#update i by the same amount as j 54. #the update is in the oppostie direction 55. b1 = b - Ei- labelMat[i]*(alphas[i]-alphaIold)*dataMatrix[i,: ]*dataMatrix[i,: ].T - labelMat[j]*(alphas[j]-alphaJold)*dataMatrix[i,: ]*dataMatrix[j,: ].T 56. b2 = b - Ej- labelMat[i]*(alphas[i]-alphaIold)*dataMatrix[i,: ]*dataMatrix[j,: ].T - labelMat[j]*(alphas[j]-alphaJold)*dataMatrix[j,: ]*dataMatrix[j,: ].T 57. if (0 < alphas[i]) and (C > alphas[i]): b = b1 58. elif (0 < alphas[j]) and (C > alphas[j]): b = b2 59. else: b = (b1 + b2)/2.0 60. alphaPairsChanged += 1 61. print "iter: %d i: %d, pairs changed %d" % (iter,i,alphaPairsChanged) 62. if (alphaPairsChanged == 0): iter += 1 63. else: iter = 0 64. print "iteration number: %d" % iter 65. return b,alphas 66. 67.def kernelTrans(X, A, kTup): #calc the kernel or transform data to a higher dimensional space 68. m,n = shape(X) 69. K = mat(zeros((m,1))) 70. if kTup[0]=='lin': K = X * A.T #linear kernel 71. elif kTup[0]=='rbf': 72. for j in range(m): 73. deltaRow = X[j,: ] - A 74. K[j] = deltaRow*deltaRow.T 75. K = exp(K/(-1*kTup[1]**2)) #divide in NumPy is element-wise not matrix like Matlab 76. else: raise NameError('Houston We Have a Problem -- \ 77. That Kernel is not recognized') 78. return K 79. 80.class optStruct: 81. def __init__(self,dataMatIn, classLabels, C, toler, kTup): # Initialize the structure with the parameters 82. self.X = dataMatIn 83. self.labelMat = classLabels 84. self.C


- 配套讲稿:
如PPT文件的首页显示word图标,表示该PPT已包含配套word讲稿。双击word图标可打开word文档。
- 特殊限制:
部分文档作品中含有的国旗、国徽等图片,仅作为作品整体效果示例展示,禁止商用。设计者仅对作品中独创性部分享有著作权。
- 关 键 词:
- 支持 向量 Python 代码 实现
 冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 《JAVA编程基础》课程标准软件16级.docx
《JAVA编程基础》课程标准软件16级.docx
-
《分数的初步认识》.docx
-
《金属钠的性质与应用》教学设计.docx
-
《蚕妇》.docx
-
《会计》教材Word版第14章非货币性资产交换.docx
-
《与朱元思书》教学案例及反思.docx
-
《小壁虎借尾巴 》教案.docx
-
1第一部分 辅导员岗位基本知识.docx
-
09年CFO复习题.docx
-
2G1计算书.docx
-
17 古诗五首夜雨寄北一等奖教案.docx
-
240T15mw机组整体启动方案解析.docx
-
485总线设计方案加上位机扩展.docx
-
Aspose Word模板使用总结.docx
-
CDMA掉话分析.docx
-
C++新闻信息管理系统.docx
-
《HSE管理体系的策划与运行》.docx
-
c语言改错题及答案.docx
-
CMS7000使用说明资料.docx
-
《财经法规与会计职业道德》模拟卷考试试题及答案资料.docx
-
《大众传播媒介的更新》教案2.docx
-
《教育知识与能力》中学版全国教师资格考试复习资料教学教材.docx
-
EPC施工组织设计1.docx
-
ERP在服装行业的信息化应用可行性研究报告.docx
-
《项羽之死》教案人教版高二选修教学设计.docx
-
《公共关系实务》总复习资料.docx
-
FLUKE744过程校准仪经典实例免费给大家会让你未来的道路更通达.docx
-
《护士条例》试题.docx
-
2F男鞋统装规范84.docx
-
4测试用例修复方法与工具.docx
-
MC尼龙轮项目可行性研究报告.docx
-
Weblogic Server系统管理手册.docx
-
卓越绩效模式.docx
-
销售个人下半年工作计划范文5篇.docx
-
人力资源实习心得.docx
-
英语试题.docx
-
大数据驱动的管理与决策研究重大研究计划度项目的指南.docx
-
数据结构课程设计插队买票.docx
-
生产车间员工绩效考核表95917.docx
-
中国内地电视剧的全媒体营销策略深析.docx
-
牛津译林版七年级英语第二学期期末模拟卷含答案.docx
-
缠中说禅动力学.docx
-
幼儿园消防安全教育课教案很详细2.docx
-
中式面点师培训教学大纲.docx
-
最新推荐微贷系统案例word范文模板 22页.docx
-
XX医药集团电子商务平台建设建设项目可行性研究方案.docx
-
初中地理天气与气候练习题附答案50.docx
-
旅游服务类职业技能考试日常交往礼仪语言表达才艺展示.docx
-
文言文宾语前置类型.docx
-
一步一步教你拟写议论文论点与分论点1.docx
-
初中数学八年级下册几何易错题集锦含答案.docx
