 原理素材参考.docx
原理素材参考.docx
- 文档编号:9091633
- 上传时间:2023-02-03
- 格式:DOCX
- 页数:22
- 大小:1.05MB
原理素材参考.docx
《原理素材参考.docx》由会员分享,可在线阅读,更多相关《原理素材参考.docx(22页珍藏版)》请在冰豆网上搜索。
原理素材参考
>什么是信道?
>信道是传送信息的载体——信号所通过的通道。
>信息是抽象的,信道则是具体的。
比如:
二人对话,二人间的空气就是信道;打电话,电话线就是信道;看电视,听收音机,收、发间的空间就是信道。
>
>3840000/16=240000=240kbps240×4/4(编码效率)×4(16QAM调制)×15(多码)=14.4Mbps
>M是调制信号的比特数目,QPSK=2,16QAM=4每个时隙160个symbol,160×M个比特
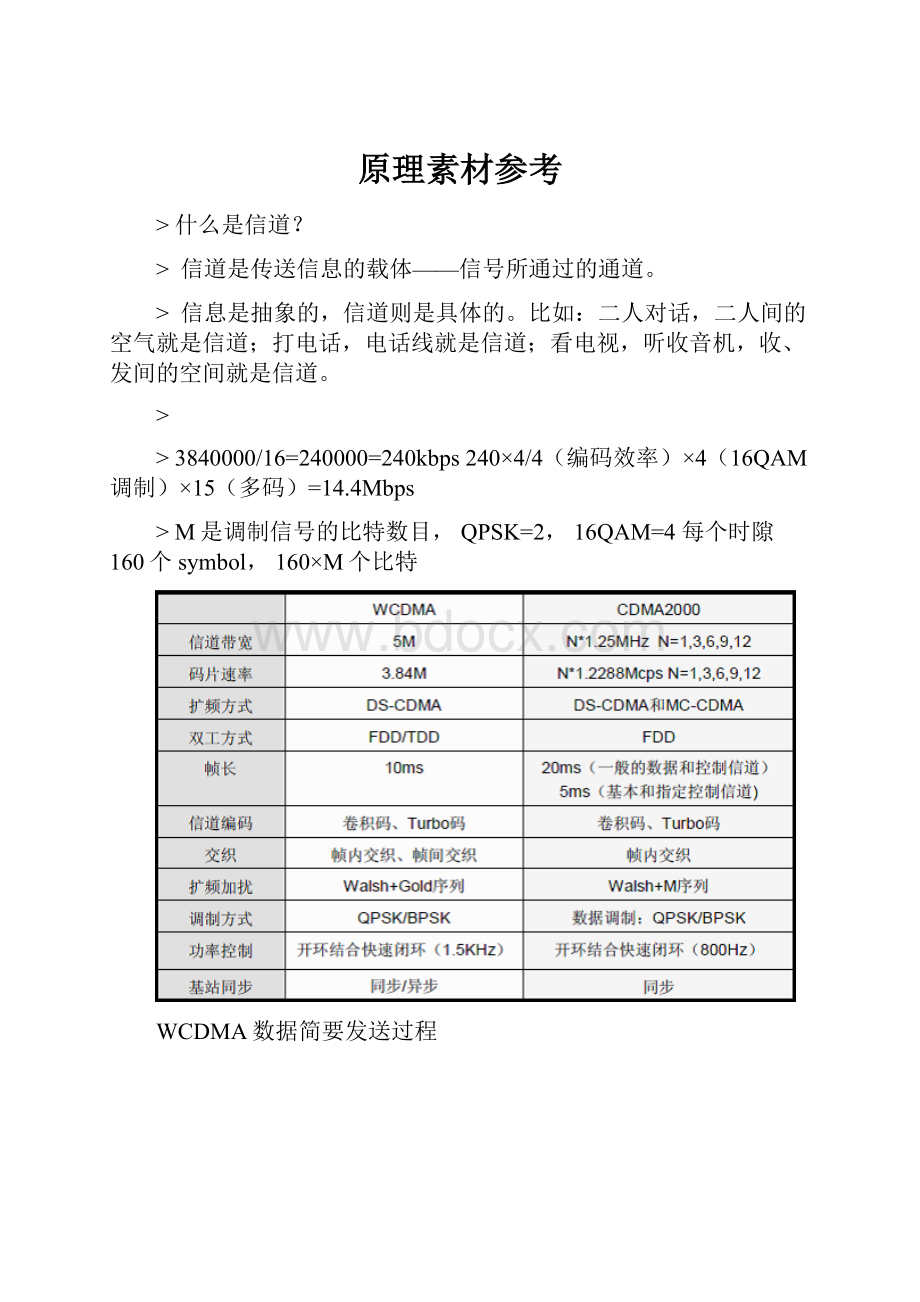
WCDMA数据简要发送过程
扩频技术
WCDMA系统的扩频
扩频与解扩
扩频与解扩
•扩频定义与处理增益
•PG=Wc/R
–Wc是码片速率
–R是信息速率
•用dB表示为PG=10log(Wc/R)
•接收端进行相关解扩即可恢复原始信号
•扩展倍数越多,处理增益越高,抗干扰能力越强
扩频通信的特点
•抗多径干扰能力强
•抗突发脉冲干扰
•保密性高
•低发射功率
•易于实现大容量多址通信
•占用频带宽
信道编码
信道编码的原理
交织技术
信道编码和交织技术的使用
三种功率控制
•开环
–从信道中测量干扰条件,并调整发射功率
•闭环-内环
–测量信噪比和目标信躁比比较,发送指令调整发射功率
–WCDMA闭环功率控制频率为1500Hz
•若测定SIR>目标SIR,降低移动台发射功率
•若测定SIR<目标SIR,增加移动台发射功率
•闭环-外环
–测量误帧率(误块率),调整目标信噪比
开环功率控制
闭环功率控制
功率控制效果
WCDMA切换基本过程
•软切换
–同一NodeB下的小区软切换(更软切换)
–不同NodeB间的小区软切换
–不同RNC间的小区软切换(涉及Iur口)
•硬切换
–不同载频间的硬切换
–同一载频下的硬切换(强制性硬切换)
–系统间硬切换(如与GSM之间)
–不同模式间硬切换(如FDD与TDD之间)
•测量控制
–UTRAN通过MeasurementControl命令要求UE进行
测量。
•判决算法
–由各厂家自行确定。
也是对系统的性能影响较大的
部分。
•执行切换
–执行不同的切换,采用不同的切换命令。
–切换过程流程图
–
与切换相关的概念
•激活集(activeset):
指与某个移动台建立连接的小区的
集合。
用户信息从这些小区发送。
•监测集(monitorset):
不在激活集中,但是根据UTRAN
分配的相邻节点列表而被监测的小区,属于监测集。
•检测集(detectedset):
既不在有效集中,也不在监测集
中的小区。
硬切换
•硬切换的测量对移动台设备的要求更复杂
•如果是不同频率的硬切换,需要测量其他频点的信号
•WCDMA采用压缩模式的方式来实现频间小区信号的
测量
启动压缩模式的目的
•为了完成频间切换和系统间切换,UE必须能够周期性
地对异频系统进行测量
•普通情况下WCDMA系统中正在进行业务(特别是话
音业务)的只有一个收发器的UE将在所有时间进行接
收和发送,也就是说在普通情况下UE将没有机会进行
异频测量
•压缩模式为处于DCH状态的UE提供了对异频系统进行
测量的窗口
压缩模式
码资源管理
•码资源规划的目的:
–在WCDMA系统中,用到两种码,OVSF码和扰码。
在WCDMA
移动通信系统中用主扰码来区分小区,下行用信道化码区分物
理信道,上行采用扰码来区分用户。
但由于正交可变扩频因子
码(OrthogonalVariableSpreadingFactor-OVSF)是宝贵的稀有
资源,一个小区对应一张码表,为了使得系统既能接入尽量多
的用户,提高系统的容量,就必须考虑码资源的合理使用问题,
所以对于下行信道化码资源的规化和管理就非常重要。
–尽管上行扰码数量非常多,但为了避免在不同的RNC之间的小
区不同用户使用相同的扰码,则也需对RNC的扰码进行规划。
•码资源规划模块在系统中的位置:
–位于CRNC的RRC中。
处理增益
•处理增益=码片速率/比特率(PG=W/R)
•不同业务的处理增益不同,因此业务覆盖半径也不相同
•12.2k的语音业务:
PG=10log(3840/12.2)=25dB
dBdBmdBidBuv
•dB:
仅仅是个相对值,dB=10log(P1/P2),比如A基站的
发射功率是600mw,B基站是300mw,那么A基站比B基站
发射功率高10lg(600/300)=3dB,从公式中可以看出dB
是表征两个功率的相对值,是没有单位的。
dB是一个无单
位的量纲。
•dBm:
是一个考证功率绝对值的值,公式为dBm=10lg(功率
/1mW),如我们常用的基站是500mw,换算成dBm就是
10lg(500mW/1mW)=27dBm(意思是27dB毫瓦)。
还有一
个单位dBW是将公式中的1mW改成1W,其他都一样。
1W=30dbm;1mw=0dbm,1W=0dbW
•dBi:
前面已解释过,表征相对值,dBi是天线增益的概念,
不是具体单位,i是isotropic(各向同性)简写。
实际上就是
dB。
•dBuV:
和dBm相同的概念。
我们在场强仪和手机测试模式上
看到的基站场强单位都是它,和dBm的关系是:
dBm:
10lg(功率/1mW)。
•dBuV:
20lg(电压/1uV),功率=电压的平方/50欧姆(如果端
口阻抗是50欧姆,一般系统都是)
•所以:
dBuv=dBm+107dB
基本概念1
需要明确的几个概念是Bit、Symbol(码符号)和Chip(码片)。
Bit对应的是有用信息(Information),是进入物理层进行基带信号处理前的信息位,它的速率称为比特速率;Symbol是在空中接口发送之前,对信息进行基带信号处理(信道编码)如交织、循环冗余校验位的添加、速率适配等之后,在进入扩频调制之前的信号,所以Symbol对应的是基带信号处理之后的信号,它的速率称为Symbol速率;Chip是空中接口上经过扩频调制之后的信息单位,用于体现能量(energy)的承载。
由此,公式BitRatexSF=ChipRate将被修正为SymbolRatexSF=ChipRate。
下表所示为UMTS服务类型常见的速率对应关系,其中的BearerDataRate应是SymbolRate:
UMTS服务类型常见的速率对应关系,其中的BearerDataRate应是SymbolRate:
Service
BitRate
(kbps)
BearerDataRate
(kbps)
SF
ModulationRate
(Mchip/s)
Speech
12.2
30
128
3.84
Packet64kbps
64
120
32
3.84
Packet384kbps
384
960
4
3.84
基带信号处理的整个过程与GSM基本一样,原始信息比特流进入传输信道作处理时,首先会添加CRC冗余校验位,称为CRCAttachment过程,这一过程的选择,取决于传输信道的特性;CRC保护之后,对信息进行编码,可以选择各种信道编码方式,如卷积、Turbe码等,效率可以是1/2、1/3各不一样,取决于服务类别;信道编码之后,要进行速率适配,称为Punctch或Repetation过程,原始比特速率可以各不相同,而后面进行扩频时,SF的取值是有固定的如4、16、32、64、128等,所以原始速率为中间值时,需要对速率进行适配,以满足SF的取值;速率适配之后,要完成一次交织和二次交织过程,交织过程中速率不会发生变化,只是打乱发送顺序,目的还是为了抵抗空中接口的干扰;交织完成之后,要做时间帧的适配,即将空中接口上的信息块适配到空中接口10ms的帧上。
过程结束之后,对于上下链路,在区分I路和Q路时,处理方法各不一样,下行链路要先进行串并转换分成I路和Q路,每个I路和Q路上的速率即为SymbolRate。
同样,对于上行链路,采用并行的BPSK方式,I路和Q路不是串并转换而来,而是各是一个分支分别进行扩频和加扰调制过程。
进行扩频之后的速率为ChipRate。
再进行加扰处理和每码字功率增益的调整过程。
整个基带信号处理过程结束之后,再进行中频转换和射频调制过程,将Chip关系调制到相位关系上,即所谓的相调。
值得注意的是,对于同一类业务,系统根据不同的Qos要求,在传输信道上可能会选择不同的速率,则信号处理过程会有所区别,实行动态的处理过程,这也是与GSM系统的区别。
但从规范的角度来看,不同Qos的业务选择的处理过程是一定的,只是提供了多样的处理方式,由RNC动态分配。
3.84Mchip/s的速率值是人为确定的。
从上述的时间频率二元性上可知,频率越宽系统的抗干扰性能越好,但频率的使用率却越低。
所以3.84Mchip/s的速率值只是人为的一个折中。
WCDMA本身定义的速率值是4.096Mchip/s,为了欧洲与北美不同制式的协调,才最终选择了3.84Mchip/s的速率。
在UMTS中,码字一共有二种类型的应用,第一种称为信道化码(Channelizationcode,简写为CH),第二种称为扰码(Scramblingcode,简写为SC)。
由于在上下行链路中处理方式的不同,导致二种类型码字的作用各不一样。
在下行链路(基站→移动台方向)上,基站向本小区发送信息时,基站首先将各种用户信息分别与各自的CH进行相乘运算,之后将信号叠加,再与扰码进行相乘运算,之后在空中接口上发射。
移动台侧先做解扰,然后再解出自己的有用信息。
用户信息和CH进行相乘运算时,CH就是扩频序列,通过选择CH的正交性,来区分用户信息。
所以CH无论在上行还是下行链路上,它最基本的作用就是直接扩频(Spreading),所以CH就是扩频码。
经过扩频后的速率都是3.84Mchip/s,再进行扰码加密过程,扰码的速率也是恒定的3.84Mchip/s。
CH除了作为扩频码外,还可以作为物理信道的ID。
在UMTS中,单个用户的业务类型,可以根据需要分配多个物理信道,理论上2M速率的实现是通过同时占用多个物理信道来实现的,而用户正是通过识别不同的CH来获得物理信道的服务,所以CH是用来区分在下行链路上的多个物理信道的。
空中接口资源在分配时,相当于分配给用户的就是多个CH。
而这种分配是由RNC来完成的动态分配。
作为扰码,移动台必须首先进行解扰,然后才能获得自己的有用信息,所以扰码的作用相当于小区的ID。
对移动台来说,由于工作在相同频率,所以可以收到来自不同小区的无线信号,是一个自干扰系统,但通过扰码,移动台只需要对驻扎小区进行解码,因为有用信息只有在本小区的专用信道上发送。
在下行链路上,移动台首先要区分本小区和非本小区的信号,这个区分过程就是通过解本小区扰码来实现的。
所以系统中每小区对应一个扰码。
需要强调的是cell、sector和BTS概念的不同。
对于BTS来说,可以是全向站、三扇区或六扇区定向站等,如果基站在发射方向是全向发射,从逻辑角度来说,基站的管理是一个小区(cell),1BTS=1cell,基站分配一个扰码;如果基站在发射方向是三扇区定向发射,每个扇区(sector)就是一个小区(cell),故一个BTS需要3个扰码。
所以cell的概念是OMCR上的概念,逻辑上是执行相关算法的最小单位。
而sector的构成是从射频角度上讲的。
在UMTS中,一个全向的BTS,可以理解为在下行链路上是全向发射,而上行方向则是3扇区定向接受的,采用3付天线,在发射方向三扇区发射相同的信号,相当于全向发射,而接受端是定向接受。
对于相邻小区的扰码在分配时码字的互相关性要低,正交性要好。
但从网络角度来说,如果二个基站处于同时发射,到达移动台后,由于所处位置不同,在接受来自二个小区的信号时,由于传播时延,信号的相位会有所偏差,形成干扰。
也就是在同步条件下,完全正交的特性,由于传播时延而遭到破坏。
在上行链路(移动台→基站方向)上,每个移动台向基站发射自己的信息,信息由每个移动台自己处理,首先经过CH进行扩频,然后再增加各自的扰码进行加扰。
对于不同用户,如果是相同的服务类型,则可以选择相同的CH,而通过扰码来加以区分。
从扰码角度来看,在上行方向上是移动台(UE)的ID,对于每一个移动台,会有一个扰码来对应,不同UE之间的扰码应该是完全正交。
对于高速业务,UE同样可以分配多个物理信道同时进行工作,只是现阶段不作讨论。
所以在UL方向,CH的作用只是扩频。
在不同方向上码字的作用归纳如下:
DownLink
UpLink
信道化码(CH)
扩频(spreading)
物理信道标识(phychannelID)
扩频(spreading)
扰码(SC)
小区标识(cellID)
移动台标识(UEID)
值得注意的是,码字作为空中接口的资源是按序分配的。
在DL方向,CH是由RNC根据业务类型进行动态分配,对于相同业务类型则分配正交的码字;SC是在OMC上确定的,相当于GSM中频率规划,在UMTS中需要做码字规划(512个主扰码),一旦确定,则是由OMC静态管理。
在UL方向,现阶段的CH是由RNC以半静态方式分配的,对于相同业务速率,CH是唯一的,规范中规定在将来可以是动态分配;SC的分配,首先要区分二个ID,一个是RNC所分配的临时识别符(UEID),另一个是完成位置登记时由核心网分配的临时识别符(UIA)。
这里的UEID仍然是由RNC动态分配的,如果是属于同一个RNC,UE的ID是不会出现重复的,由UEID来触发上行链路上扰码的产生,所以上行链路上的扰码是RNC根据用户的每一次RRC连接建立请求动态分配的,上行SC是针对每用户分配,而不是针对每业务类型。
所谓的RNC无线资源的管理功能,就是RNC对码字的管理。
(注上述码字均为用户专用信道上的码字,非公共信道上的码字)
对于WCDMA来说,选择的扩频码称为正交可变扩频因子(OrthogonalVariableSpresdingFactor,简称OVSF)。
该码字的产生机制与Walsh码的产生机制没有太大区别,Walsh码用矩阵结构而OVSF采用树形结构来描述。
最初的根赋值是Cch,1,0=1,由SF=1升至SF=2时,第1个子树的第一比特位保留,第二比特位进行复制,Cch,2,0=11,第2个子树的第一比特位保留,第二比特位进行相位偏转,Cch,2,1=1-1,依此类推,SF=4时子树的产生机制与SF=2时相同,码树结构如图:
SF=1SF=2SF=4……
在OVSF码树结构中,每一阶对应一个SF值,如SF=2时,位于同阶的可用码字是2个,SF=4时,可用码字是4个,依此类推,SF=8时,有8个可用码字。
码字的标识是Cch,SF,no
其中,SF为扩频因子,No从上至下按序编号。
SF值代表原来的一个比特用SF个码片来表示,如SF=4,一个比特位用4个码片来表示。
每个码字的长度与SF值相关,SF=4表示码字长度为4。
码字的取值范围,在上行方向,SF=4、8、16、32、64、128、256;在下行方向,SF=4、8、16、32、64、128、256、512。
使用位于同一阶的码字,表示原始用户的业务速率是一致的,才会选择到相同的SF值。
同一阶码字之间是完全正交的。
当位于不同阶的码字间存在父子关系时,码字之间具有相关性,在DL方向也就不能被同时分配使用。
当位于不同阶的码字间不存在父子关系时,码字之间仍是正交关系。
由于父子关系的码字具有相关性,所以在选择码序列时数量会受限。
在DL方向不考虑公共信道和功率受限,假设所有码字都可以被分配用来通信,在最大情况下允许同时使用的用户数应当是512个。
在DL方向所能支持的最大速率,SF越小,速率越高,所以在SF=4时,速率是最大。
但在SF=4是,只能用Cch,4,1、Cch,4,2、、Cch,4,3三个码字,这是因为Cch,4,0产生的子码字序列要被分配给公共信道使用。
所以Cch,4,0树不能使用,用户的2M速率就是同时占用SF=4的三个码字获得的。
SF=4时单信道的SymbolRate=3.84/4=960ksymbol/s,这只是其中一路(I或Q路)上的速率,两路信号在DL方向是通过串并转换之后获得的,奇偶比特分开,速率减半。
所以在恢复到原始比特时,首先要经过串并转换的逆过程,将I路960k信号和Q路960k信号叠加,成为2x960=1920kbps速率的信号,这才是经过信道编码、交织等基带信号处理过程之后的信号速率。
在1920kbps中有用信息只占768kbps,这是进行基带信号处理前的有效速率,相当于用户单信道上的原始信息速率只有768kbps,只有同时得到DL方向上三个信道的物理链路,BitRate=3x768=2.1Mbps,才能满足最大2M的业务。
所以2M速率指的是用户的比特速率,在规范中被归为2048业务。
OVSF的分配原则:
在DL方向,根据用户的业务请求由RNC动态分配,在同一阶情况下,初始状态时,是按由上到下的原则分配,在使用状态下,对空闲资源,也是从上到下按序分配。
从RNC的动态资源管理来说,假设在SF=8层,已有5个用户分别占用5个码字信道(0、2、6码字未用),在不考虑上行链路的干扰受限和下行链路的功率受限时,有第6个用户(业务速配要求SF=4)申请接入时,RNC允许接入,分配码字时可以采用二种方案,第一种称为Auto-Patching(打补丁)方案,所谓补丁现象,是指由于码字资源的按序分配,个别用户在放弃码字时,会出现不相邻码字被分别占用的现象,如3、7码字占用而2、6码字未占用。
所以当第6个用户申请接入时,可以将占用码字3的用户重新配置,使占用码字6信道,将2、3码字的父码字(SF=4)分配给用户6,这个过程即为Auto-Patching过程;第二种称为Self-Splitting(自我分裂)方案,将申请SF=4的用户分裂,使分别占用2个SF=8的信道来实现。
二种方案优选第二种,因为无线链路重建需要涉及相应的信令过程,同时,二个SF=8的功率和一个SF=4的功率是不等效的。
在速率适配时,RNC会优先选择SF值高的物理信道,以降低功率。
在UL方向的码字分配,现阶段在专用的信令和业务信道上,只能分配每阶中的一个码字,即Cch,SF,SF/4的码字,如Cch,4,1、Cch,8,2等。
该码字是11-1-1的重复,只是根据速率不同SF值的不同而重复的次数不同。
这是针对单业务单信道情况的码字分配方案,将来如果一个移动台支持多个业务,码字分配就会发生变化,该原则不再发生作用。
一般认为在上行链路上所要求的速率不是很高,区分用户是通过扰码来区分的,不同用户之间无需通过扩频码来区分用户,所以可以简化码字的分配方式,现阶段无需通过扩频码来区分物理信道,对相同速率的业务可以分配相同的扩频码字,而只通过扰码来区分用户。
RNC的这种分配方式称为半静态分配方式。
根据上述的分配原则,一个小区在DL方向码字最多只能分配一个2M业务的承载,这称为码字缺陷(Shortage)。
为了弥补缺陷,规范中规定了付扰码(SecondarySC)的概念,对相同的扩频码,为了达到重复使用的目的,以满足多用户的业务需求,可以通过付扰码加以区分。
在同一个扰码下,OVSF码树只能使用一次,对同一个小区来说,最多可以分配1个主扰码和15个付扰码,即OVSF可以重复使用16次,所以码字资源是足够使用,只是现阶段仍暂不使用付扰码。
从码字角度考虑容量是不受限的,受限的是下行链路上的功率和上行链路上的干扰,也就是在下行链路上允许提供多少个2M用户取决于小区最大允许功率数。
码字的正交性在同步前提下完全正交,非同步条件下会发生相位偏转。
信号在下行链路是所有码字叠加后进行发射的,所有码字同步且正交,到达移动台后,移动台接受来自不同小区的信号,码字会发生偏转,可以通过主扰码加以区分和过虑,从而接受本小区的信号。
本小区信号由于多经产生的时延对于移动台来说,无论是有用信号还是干扰信号都是一样的。
所以对于信道化码的码字要求只是完成扩频及基本正交就可以。
在上行链路,每个移动台各自发射独立的信号,传播时延及发射时间不同,基站侧接受仍是所有信号的叠加,上行链路上的信号相关性较差,不可能同步,所以要选择相关性比扩频码要好的扰码来区分不同用户,对扰码的特性要求较高。
对于扰码来说,系统选择的是伪随机序列(PN序列),PN序列的码字与窄代CDMA不同,窄代CDMA是m序列,WCDMA选择的是Gold序列。
序列不同指的是产生的机制不同,从而会有不同的相关特性。
PN序列产生的基本原理如图所示:
以三个移位寄存器为例,每一位的初始赋值称为状态值,假设为001,最后一位的状态值作为PN序列的输出,序列产生如下:
序列
第一位
第二位
第三位
PN输出
0
1
1
1
0
0
0
2
0
1
0
0
3
1
0
1
1
4
1
1
0
0
5
1
1
1
1
6
0
1
1
1
7
0
0
1
1
产生的PN序列为11101001的周期性重复,循环周期称为PN序列的长度=2n-1,其中n为移位寄存器的个数,例中n=3,所以序列长度为7位,每7位之后会重复一次。
由于选择PN序列的长度、寄存器抽头及初始赋值各不一样,将会产生不同的PN序列。
PN序列每偏移一个相位,就可以截取2n-1长的PN序列,也就是对于周期为2n-1的PN序列可以有2n-1个。
在UMTS中,上行链路的PN序列采用25位移位寄存器,I路Q路分开各是25位寄存器,可以看成同一个扰码。
扰码周期(长度)为225-1。
根据扰码产生的机制,首先寄存器的赋值是变化的,对Q路来说,初始赋值为全“1”码,对I路来说,初始赋值的前24位有RNC动态分配,也就是RNC分配给移动台一个24位的识别符,这个识别符将作为PN序列产生的寄存器前24位的初始赋值,再加上第25位的状态值“1”。
在上行链路方向上每个移动台由于所得的状态值不同的,所以产生的码序列是不同的,相当于在该方向上实际可以使用的扰码是224个。
Gold码产生的码序列的自相关性是非常好的,但由于只是初始赋值的不同,所以不同的PN序列不是完全正交,只是近似正交。
但由于码序列长度较长,克服了正交特性的不足,因为码字越长,正交性越好。
所以在UMTS中,系统不需完全同步,只要近似同步就可以。
在上行链路,还可以选择短扰码,该扰码周期是256,该技术在将来会被引入,当在上行链路上使用短扰码时,为克服码间干扰,对Rake接受机会有较高要求,会采用多用户监测技术(MUD)来代替Rake接受机制,目前使用的还是长扰码。
在实际使用中,系统会每10ms截取PN序列中的38400chips,使扰码速率位3.84Mchip/s,所以只使用了PN序列中的一段。
在下行方向上的扰码仍然选择的是长扰码,它的初始赋值及周期是固定的。
采用18位的移位寄存器,周期是218-1=262143,而实际在下行链路上可以使用的扰码规范只定义了8192个,作为CellID,规范只定义了8192个扰码,并分配到512个小区,每个小区可以使用16个扰码,包括1个主扰码和15个付扰码。
15个付扰码完成对OVSF的复用。
相当于可用码字是1


- 配套讲稿:
如PPT文件的首页显示word图标,表示该PPT已包含配套word讲稿。双击word图标可打开word文档。
- 特殊限制:
部分文档作品中含有的国旗、国徽等图片,仅作为作品整体效果示例展示,禁止商用。设计者仅对作品中独创性部分享有著作权。
- 关 键 词:
- 原理 素材 参考
 冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 《城市规划基本知识》深刻复习要点.docx
《城市规划基本知识》深刻复习要点.docx
-
《高电压技术》word版.docx
-
《安全带》gb6095.docx
-
BCP计划应急计划.docx
-
《计算机组成与工作原理》第一章复习题.docx
-
CANON LBP系列激光打印机使用方法指南.docx
-
C语言课程设计火车票系统源代码.docx
-
3热力管道沟槽开挖方法.docx
-
HR岗位职责.docx
-
1 脱硫脱硝cems维护技术规范.docx
-
O2O超市商业项目计划书.docx
-
SCI期刊呼吸胸外.docx
-
18岁生日祝福语短信.docx
-
ITMC物流企业经营沙盘比赛规则.docx
-
XX钢绳成本管理.docx
-
Matlab的第三方工具箱大全强烈推荐.docx
-
安全保卫工作先进个人.docx
-
安全生产工作日记.docx
-
windows 漏洞集合.docx
-
Φ160数控落地镗铣床技术规格.docx
-
安全施工组织设计.docx
-
安全检查和隐患排查治理制度及记录.docx
-
部编版小学二年级语文下册课外阅读专项.docx
-
变电站投运前质量监督检查汇报材料模版.docx
-
版 创新设计 高考总复习 历史 北师大版第一部分 必考内容第十五单元 第38讲.docx
-
本科毕业设计论文.docx
-
北京大学社会心理学串讲笔记1一10章加试题.docx
-
亳州市教坛新星骨干教师学科带头人特级教师年度考核细则知识分享.docx
-
超星尔雅《人生与人心》期末考试满分答案.docx
-
财经法规与会计职业道德案例分析题.docx
-
茶文化会发言稿.docx
-
财务会计核算实习总结.docx
-
国家开放大学金融理论前沿课题试题.docx
-
智能家居系统毕业设计.docx
-
中餐服务流程培训资料.docx
-
中国动脉瘤性蛛网膜下腔出血诊疗指导规范.docx
-
资金时间价值讲义练习.docx
-
自考艺术设计考试科目.docx
-
综合办公室工作计划新编版.docx
-
化工企业安全工作计划.docx
-
化学新课程改革.docx
-
客户关系管理系统论文.docx
-
快换式纯电动整车通讯协议.docx
-
劳动关系协调师二级简答题.docx
-
理正边坡综合治理学习.docx
-
练习项目管理作业.docx
-
临床综合技能训练大纲.docx
-
六级词汇.docx
-
六年级下仁华课本3.docx
-
陆港.docx
-
罗振宇从草根到精英让你看看这个胖子有多牛逼.docx
