 统计学.docx
统计学.docx
- 文档编号:8985803
- 上传时间:2023-02-02
- 格式:DOCX
- 页数:19
- 大小:82.89KB
统计学.docx
《统计学.docx》由会员分享,可在线阅读,更多相关《统计学.docx(19页珍藏版)》请在冰豆网上搜索。
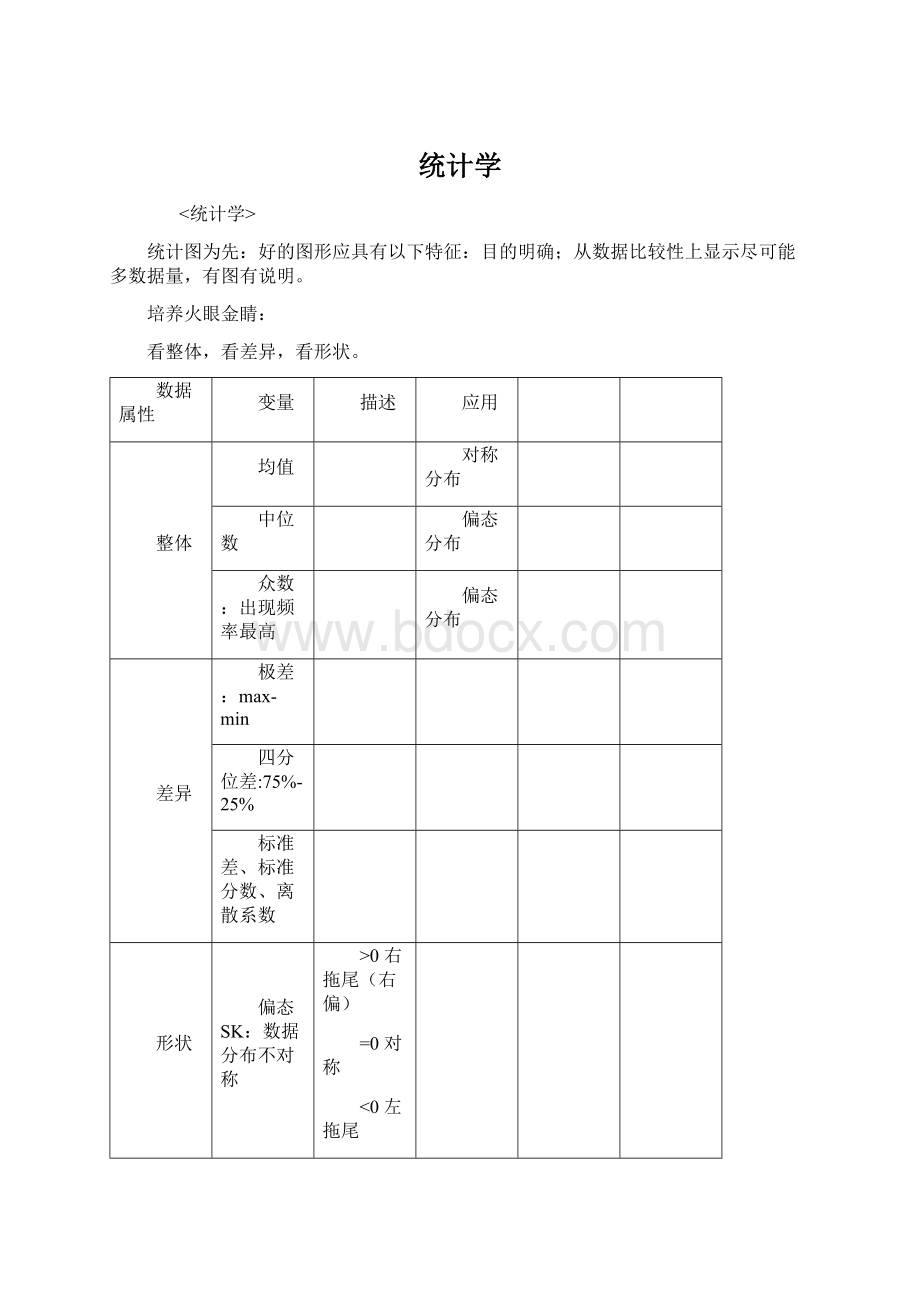
统计学
<统计学>
统计图为先:
好的图形应具有以下特征:
目的明确;从数据比较性上显示尽可能多数据量,有图有说明。
培养火眼金睛:
看整体,看差异,看形状。
数据属性
变量
描述
应用
整体
均值
对称分布
中位数
偏态分布
众数:
出现频率最高
偏态分布
差异
极差:
max-min
四分位差:
75%-25%
标准差、标准分数、离散系数
形状
偏态SK:
数据分布不对称
>0右拖尾(右偏)
=0对称
<0左拖尾
峰态K:
峰值高低
>0尖峰
=0正态
<0扁平
算样本:
先基础:
类别
具体
适用范围
离散
二项
放回抽样
泊松
预先知道单位时空内随机变量的均值
一定时空范围某事件出现次数
超几何
不放回抽样的二项分布
连续
正态
正态期望-样本值成直线
N个正态总体的随机变量的平方和
总体方差的估计与非参数检验
T分布:
若y
类似正态,比正态平坦与分散
正态总体标准差未知,小样本条件下对总体均值的估计与检验
F分布:
类似
比较不同总体的方差是否有显著差异
后样本:
统计量
计算式
适用范围
标准误差
样本均值
任何总体分布时,大样本下服从
大样本
比例p
大样本
样本方差
正态
的样本统计量
取决于总体与样本量
的样本统计量
两大样本下正态
的样本统计量
F=
正态下服从F分布
Ch5参数估计
均值
比例
方差
大样本
小样本
大样本
正态
Z分布
未知用
替代
Z分布
Z分布
t分布
两个总参数估计所使用的分布
均值差
独立大样本
已知
Z
未知
用
表示
Z
独立小样本,且正态总体
已知
Z
未知
T
T
比例差
独立大样本
Z
方差比
-
F分布
样本量的确定:
由置信水平和总体标准差,给定的估计方差共同决定。
Ch6假设检验
6.1原理
怎样提出假设:
原假设是研究者想收集证据予以推翻的假设,备择假设与原假设互斥。
怎样作出决策:
Step1:
原假设正确却拒绝了称为
,原假设错误却未拒绝称为
错误。
犯那类错误的代价高就把那类错误设置低。
一般先控制
错误。
Step2:
依据啥作出决策
双侧假设
>临界值
拒绝原假设
左
统计量的值<临界值
拒绝原假设
右
统计量的值>临界值
拒绝原假设
或者更准确地用P值决策:
依靠统计量的分布函数,代入样本值,计算样本概率值进行决策。
Step3:
如何表述决策结果
假设检验不能证明原假设正确,因为拒绝与不拒绝都是在原假设的条件下进行的,至于原假设正确与否超出了假设之外。
统计显著不等于有实际意义:
P值决策中,样本量越大,检验统计量的值越大,P值越小,越有可能拒绝原假设。
因此只要样本量足够大总能拒绝原假设,即统计上越显著,但不一定有实际意义。
6.2一个参数的假设检验
6.3两总体参数的检验
与一总体参数的检验类似,统计量的表达式复杂些。
Ch7方差分析与实验设计
7.1方差分析的原理:
方差分析的方法:
误差的分解:
总误差=随机误差+处理误差
总平方和=组内平方和+组间平方和
方差分析的前提:
正态性:
正态总体
方差齐性:
各总体的方差相等,检验方法
独立性:
样本数据来自因子各水平的独立样本。
一般来说,方差分析对独立性的要求较高。
定义
前提
方差分析
研究分类自变量对数值因变量的影响,可形象地理解为检验多个总体均值是否相等的统计方法
正态性:
正态总体
通过标准化残差=残差/(残差的标准差(或者残差标准差的估计))
方差齐性:
各总体的方差相等,检验方法
Yi-yei(残差)值均落在一条水平带内均匀分布;
若对于较大x,残差值称增长趋势,则不满足残差相等原则;
若残差曾呈有规律的分布,表示回归模型不合适
独立性:
样本数据来自因子各水平的独立样本。
见ch10
7.2单因子与多因子的方差分析
单因子
求关系的步骤
1.提出假设H0:
u1=u2=u3…;
H1:
u1,u2,u3不全相等
2.构造检验统计量F=组间方差除以组内方差服从F分布
3.P决策值,若P 关系的强度 组间平方和占总平方和的比例 哪些均值有显著差异 1.提出假设: ui 2.构造统计量: xi的均值与xj的均值之差的绝对值 3.Fisher的LSD方法,进行决策 多因子 不考虑交互作用 类似单因子,主因子进行分析 提出假设 构造统计量 决策 考虑交互作用 提出假设: H0: 无交互作用 构造统计量: F(rc)=交互作用均方/残差均方,服从F((k-1)(r-1),kr(m-1)),其中k,r分别为行列因子的水平数,m为重复测量的次数 决策: p(rc) 7.3实验设计基本: 完全随机化设计: 因子的水平被随机地指派给试验单元 随机化区组设计: 先划同质区,再随机化抽取实验单元 因子设计: 因子间的搭配设计 Ch8: 一元线性回归 8.1相关系数r: 度量两变量间线性关系强度的统计量, 前提: 线性关系 自变量服从联合正态分布 剔除了极端值 取值: -1-1,r=0,两变量间不存在线性关系 相关系数的检验 定义 假设 取值范围 度量两变量间线性关系强度的统计量 线性关系 -1-1,r=0,两变量间不存在线性关系 自变量服从联合正态分布 剔除了极端值 8.2一元线性回归的估计与检验 1.回归模型: y=b0+b1*x+epsi,其中epsi满足正态性,方差齐性,独立性 2.估计的回归方程: y=be+b1e*x 3.参数be,b1e的计算法: 最小二乘估计 4.回归直线的拟合优度: 拟合优度 定义 回归直线与观测点的接近程度 评价量 判定系数: 回归平方和SSR(ye(估计值)-ya(均值))占总平方和SST的比例 说明回归直线对观测数据的拟合程度,故值越大说明拟合越好 估计标准误差 Yi-yei平方和SSE的均方根 说明拟合误差 显著性检验 线性关系检验F检验 检验y-x间的线性关系是否显著 1.提出假设: H0: b1=0,H1: b1不为0 2.构造检验统计量: F=(SSR/K)/(SSE/(n-k-1))服从F(1,n-2) 3.P 回归系数的检验与推断t检验 检验自变量对因变量的影响是否显著 1.提出假设: 一元时回归系数检验与线性关系检验等价: H0: B1=0 2.构造检验统计量: T=回归系数b1的估计值b1e/b1e的标准差 3.P 8.3预测: 平均值的置信区间: 给定x=x0,求出的y的平均值的估计区间 个别值的置信区间: 给定x=x0,求出的y的一个个别值的估计区间 平均值的置信区间宽度<个别值的置信区间宽度 Ch9多元线性回归 重点介绍不同处: 拟合优度与显著性检验 拟合优度 定义 回归直线与观测点的接近程度 评价量 多重判定系数: 回归平方和SSR(ye(估计值)-ya(均值))占总平方和SST的比例 由于增加自变量会减少残差平方和,故常采用减去自变量个数的调整的多重判定系数 Ra平方=1-(1-R平方)*(n-1)/(n-k-1) 说明回归直线对观测数据的拟合程度,故值越大说明拟合越好 估计标准误差: Yi-yei平方和SSE的均方根 说明拟合误差 显著性检验 线性关系检验F检验 检验y-x间的线性关系是否显著 1.提出假设: H0: b1=0,H1: b1不为0 2.构造检验统计量: F=(SSR/K)/(SSE/(n-k-1))服从F(1,n-2) 3.P 回归系数的检验与推断t检验 检验自变量对因变量的影响是否显著 1.提出假设: H0: Bi=0 2.构造检验统计量: T=回归系数bi的估计值bie/bie的标准差服从t(n-k-1) 3.P 多重共线: 识别: 模型F检验显著,几乎所有回归系数的t检验不显著;回归系数的正负号与期望相反 处理: 前向选择;向后剔除;逐步回归(可不断+,-变量均可) 虚拟变量: 数值化定性自变量,k个定性水平,k-1个虚拟变量 Ch10时间序列预测 时间序列的组成要素: 趋势、季节变动、循环变动、不规则波动 时间序列变化的组成要素 特点 检验法 预测法 预测步骤 单成分 趋势 持续 线性、非线性、平滑 季节 一年固定周期 自回归 循环 非固定周期 自回归: 先进行D-W检验: 判断残差是否存在自相关,d属于[0,4], 若d 若d>du,不拒绝 Dl 其次对于自回归的阶数,可先选择一个高阶,通过高阶系数是否显著(是否为0)进行检验后将不显著的参数去掉。 不规则 不规则震荡 平滑法 趋势 多成分 季节性回归法 引入季节性虚拟变量(季度引入3个,月份引入11个),注意此时回归方程中的t的单位也相应是季度或月,且逐年递增 分解预测 Step1: 分理出季节成分,step1.1: 计算移动平均值(按季度顺序排列,下一年第一季t=5,…); Step1.2将观察值除以移动平均值,得各季度的比值,再按1,2,3,4季度对比值分组,计算各组平均值,即得各季度的季节指数 Step2: 分离季节成分: 原始值除以季节指数 Step3: 建立预测模型并预测step4: 预测值乘以季节指数得最终的预测值 预测流程图: Ch11主成分分析与因子分析 方法名 原理 模型 步骤 主成分 找主成分代表原变量 Y=AX,其中X为原始变量 Step1: 标准化原变量 Step2: 计算相关系数矩阵 Step3: 找出相关系数矩阵的特征根和单位特征向量 Step4: 确定主成分,并给出合理解释 说明: 一般统计会给出主成分的方差贡献率和累计方差贡献率,它反映了主成分对原始变量的影响程度,引入该主成分后可以解释原始变量的信息。 因子分析 将原始变量综合称少数几个因子 X=AF,X为原始变量,F为综合因子 Step1: 数据检验,相关系数矩阵中的大部分数,<0.3就不适宜做因子分析,还可作KMO,Bartlett球度检验;样本至少是变量数的5倍,且》100 Step2: 因子提取: 主成分法、不加权最小平方法、加权最小平方法、最大似然法主轴因子法,一般累计贡献率达到80%即可,特征根>1 Step3: 因子命名与解释,若因子对每个变量载荷因子,即aij对每个i取值都较大,此时需要进行因子旋转,提高因子的解释度。 Step4: 由f=bx,求出因子在每个x上的值即为因子得分,有必要的化可进一步计算加权因子总分 Ch12聚类分析 名称 原理 分类 说明 聚类分析 事先不知道类别 主要依靠相似度的度量: 样本点间距离,变量间相似系数来进行分类 层次: 事先不知道分几类 明确目的; 选择变量; 方法选择 K-均值: 事先确定K类,不断迭代至预设条件 Ch13非参数检验: 总体概率分布未知或无法假定 分参数检验 用途 参数检验 单样本 二项分布 总体是否服从p二项分布 无 K-S检验 是否服从某一理论分布 无 符号检验 总体位置参数是否=假定值 总体均值的z或t检验 Wilcoxon检验 总体位置参数是否=假定值 总体均值的z或t检验 两样本检验 两配对Wilcoxon符号秩检验 配对数据的总体位置参数是否相同 总体均值差的z或t检验(配对样本) 两独立样本的Mann-Whitney 两总体位置参数是否相同 总体均值差的z或t检验(独立样本) 多样本检验 K个独立样本的Kruskal-Wallis 检验多总体是否相同 单因子方差分析 顺序样本检验 秩相关及其检验 检验两变量的相关性 线性相关系数及其检验 核心思想: 排序计算秩(序号),若原假设成立(参数相同),则秩应该等于期望值


- 配套讲稿:
如PPT文件的首页显示word图标,表示该PPT已包含配套word讲稿。双击word图标可打开word文档。
- 特殊限制:
部分文档作品中含有的国旗、国徽等图片,仅作为作品整体效果示例展示,禁止商用。设计者仅对作品中独创性部分享有著作权。
- 关 键 词:
- 统计学
 冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 对中国城市家庭的教育投资行为的理论和实证研究.docx
对中国城市家庭的教育投资行为的理论和实证研究.docx
-
二年级下册数学练习题大全.docx
-
二十年后回故乡的优秀作文.docx
-
软基换填施工方案.docx
-
《黑白装饰画》教案.docx
-
课堂教学改革实施方案5篇.docx
-
返璞归真简约致美解读《给予树》教学设计语文.docx
-
离职证明范本精选多篇.docx
-
《天局》全文.docx
-
我害怕作文集合15篇.docx
-
伏魔战记39详细攻略.docx
-
幼儿园学期计划.docx
-
雅思分类打印版Word格式文档下载.docx
-
年产1万吨竹子纤维加工项目可行性研究报告文档格式.docx
-
电商产业化项目投资经营商业计划书Word文件下载.docx
-
医学多媒体课件的设计与制作Word文档格式.docx
-
中学生中秋节想象作文Word格式.docx
-
等保20之漏洞扫描系统技术方案建议书Word文档格式.docx
-
培训学校个人工作计划模板5篇Word格式.docx
-
北京各区二模试题分类汇编文言文阅读Word文档下载推荐.docx
-
不同职业病危害因素的防护常识Word格式文档下载.docx
-
一年级上册同音形近字练习汇总Word文档格式.docx
-
班级家长会上班主任教师讲话稿Word下载.docx
-
科斯塔环载波恢复Word文件下载.docx
-
浙教义务版六年级语文下册教案 花潮Word文件下载.docx
-
集成电路设计与集成系统专业Word格式文档下载.docx
-
开工第一课专题讲座观后感文档格式.docx
-
东城区学年第一学期高三期末化学试题及答案Word格式文档下载.docx
-
苏教版六年级语文下册第七单元测试题Word格式文档下载.docx
-
学长征精神做红色传人活动方案文档格式.docx
-
读书笔记150字30篇文档格式.docx
-
中级经济法考前必背法条精华版备考资料Word格式.docx
-
麦当劳实习日记Word文件下载.docx
-
班主任家长会发言稿六年级文档格式.docx
-
七年级数学下直方图课时练习新人教版附答案Word格式.docx
-
电视台记者编辑笔试题文档格式.docx
-
酒店客房清扫标准Word下载.doc
-
煤矿秋冬季安全生产大检查工作方案Word文档格式.docx
-
安全演讲稿7篇Word文档格式.docx
-
敦煌古城观后感优秀word范文 16页Word文件下载.docx
-
其它考试A类教育心理学和教育学题11年复习文档格式.docx
-
酒店客房质检表Word文件下载.doc
-
采购设备进口业务流程管理文档格式.doc
-
评优个人工作总结Word文件下载.docx
-
企业的营销管理问题本科毕设论文Word格式.docx
-
普通物理学工科教学大纲Word下载.docx
-
李清照百家讲坛Word文档下载推荐.docx
-
鹰潭信江饮用水水源保护条例Word文件下载.docx
-
小学语文必读书目练习题Word格式.docx
-
实用的乡镇年终工作总结模板合集五篇Word格式文档下载.docx
-
领导在财务工作会上的讲话精选多篇Word文档格式.docx
