 数据库体系结构.docx
数据库体系结构.docx
- 文档编号:8807753
- 上传时间:2023-02-01
- 格式:DOCX
- 页数:16
- 大小:235.46KB
数据库体系结构.docx
《数据库体系结构.docx》由会员分享,可在线阅读,更多相关《数据库体系结构.docx(16页珍藏版)》请在冰豆网上搜索。
数据库体系结构
数据库体系结构
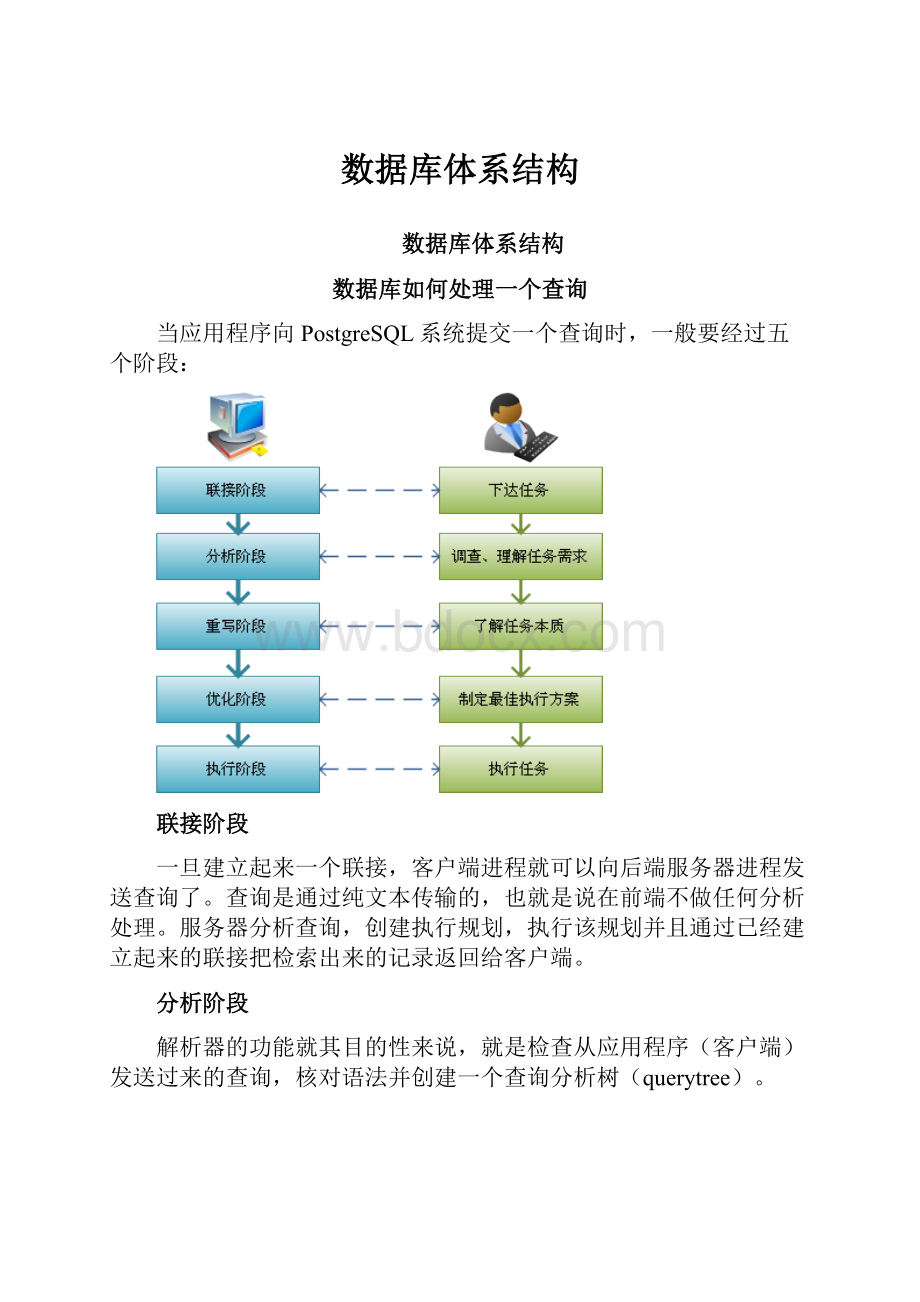
数据库如何处理一个查询
当应用程序向PostgreSQL系统提交一个查询时,一般要经过五个阶段:
联接阶段
一旦建立起来一个联接,客户端进程就可以向后端服务器进程发送查询了。
查询是通过纯文本传输的,也就是说在前端不做任何分析处理。
服务器分析查询,创建执行规划,执行该规划并且通过已经建立起来的联接把检索出来的记录返回给客户端。
分析阶段
解析器的功能就其目的性来说,就是检查从应用程序(客户端)发送过来的查询,核对语法并创建一个查询分析树(querytree)。
重写阶段
重写系统是一个位于分析器阶段和规划器/优化器之间的模块。
它接收分析阶段来的查询树且搜索任何应用到查询树上的规则,(规则存储在系统表里)并根据给出的规则体进行转换。
重写系统的一个应用就是实现视图。
当一个查询访问一个视图时(也就是说,一个虚拟表),重写系统改写用户的查询,使之成为一个访问在视图定义里给出的基本表的查询。
优化阶段
规划器/优化器的任务是创建一个优化了的执行规划。
它首先合并对出现在查询里的关系进行扫描和连接所有可能的方法。
这样创建的所有路径都导致相同结果,而优化器的任务就是计算每个路径的开销并且找出开销最小的那条路径。
执行阶段
接受规划器/优化器传过来地查询规划然后递归地处理它,抽取所需要的行集合。
执行器就是对应于上面所提到的查询引擎中的执行处理客户端发来的请求(Executor),它是查询引擎的核心模块。
执行器实际上是一个需求-拉动地流水线机制。
每次调用一个规划节点地时候,它都必须给出更多的一个行,或者汇报它已经完成行的传递。
针对不同的SQL查询类型,执行器会有不同的执行方案,而这些方案的选择是按照执行器机制进行的。
数据库总体架构图
PostgreSQL的总体架构图
●Postmaster:
它主要负责在客户端第一次发送请求给服务器的时候建立一个服务器端进程。
也就是上图中的Listener。
●Listener:
也就是每个客户端对应的服务器端进程,它的主要作用是和客户端进行通信,获取客户端的sql语句,并把查询结果返回给客户端。
●Optimizer:
查询优化器,主要功能是分析客户端提交的sql语句,给出所有的执行路径,并从中找出一个最优的方案,最后把这个执行方案交给执行器。
●BufferManager:
缓冲管理器,主要功能是对共享缓冲区和本地缓存区进行管理。
服务器体系结构图
●SQL客户端接口负责在客户端和服务器端通信,对应服务器体系结构图中的libpq。
●系统控制管理器负责初始化和控制整个PostgreSQL系统,对应服务器体系结构图中的Postmaster和Postgres。
●查询引擎是最主要的子系统,负责解析、优化和执行处理客户端发来的请求,对应服务器体系结构图中由Parser、TrafficCop、Rewrite、ChoosePath&GeneratePlan、Executor和UtilityCommands组成的部分。
●数据字典存储在系统关系中,存储着系统运行必要的信息和对象的定义信息,并提供处理创建删除对象的接口,对应服务器体系结构图的Catalog。
●存储管理器负责管理内存和磁盘,提供存取数据库的数据的功能,对应服务器体系结构图的StorageManagers。
●存取方法和事务管理器控制着逻辑的数据存取和数据库的ACID特性实现,对应服务器体系结构图的AccessMethods。
●库和实用工具程序为其他子系统提供功能上的支持对应服务器体系结构图的Utilities和Nodes/Lists。
完整的数据库查询原理
第一步:
应用程序把查询SQL语句发给服务器端执行
我们在数据层执行SQL语句时,应用程序会连接到相应的数据库服务器,把SQL语句发送给服务器处理。
第二步:
服务器解析请求的SQL语句
1、SQL计划缓存,经常用查询分析器的朋友大概都知道这样一个事实,往往一个查询语句在第一次运行的时候需要执行特别长的时间,但是如果你马上或者在一定时间内运行同样的语句,会在很短的时间内返回查询结果。
原因:
●服务器在接收到查询请求后,并不会马上去数据库查询,而是在数据库中的计划缓存中找是否有相对应的执行计划,如果存在,就直接调用已经编译好的执行计划,节省了执行计划的编译时间。
●如果所查询的行已经存在于数据缓冲存储区中,就不用查询物理文件了,而是从缓存中取数据,这样从内存中取数据就会比从硬盘上读取数据快很多,提高了查询效率.数据缓冲存储区会在后面提到。
2、如果在SQL计划缓存中没有对应的执行计划,服务器首先会对用户请求的SQL语句进行语法效验,如果有语法错误,服务器会结束查询操作,并用返回相应的错误信息给调用它的应用程序。
注意:
此时返回的错误信息中,只会包含基本的语法错误信息,例如select写成selec等,错误信息中如果包含一列表中本没有的列,此时服务器是不会检查出来的,因为只是语法验证,语义是否正确放在下一步进行。
3、语法符合后,就开始验证它的语义是否正确,例如,表名,列名,存储过程等等数据库对象是否真正存在,如果发现有不存在的,就会报错给应用程序,同时结束查询。
4、接下来就是获得对象的解析锁,我们在查询一个表时,首先服务器会对这个对象加锁,这是为了保证数据的统一性,如果不加锁,此时有数据插入,但因为没有加锁的原因,查询已经将这条记录读入,而有的插入会因为事务的失败会回滚,就会形成脏读的现象。
5、接下来就是对数据库用户权限的验证,SQL语句语法,语义都正确,此时并不一定能够得到查询结果,如果数据库用户没有相应的访问权限,服务器会报出权限不足的错误给应用程序,在稍大的项目中,往往一个项目里面会包含好几个数据库连接串,这些数据库用户具有不同的权限,有的是只读权限,有的是只写权限,有的是可读可写,根据不同的操作选取不同的用户来执行,稍微不注意,无论你的SQL语句写的多么完善,完美无缺都没用。
6、解析的最后一步,就是确定最终的执行计划。
当语法,语义,权限都验证后,服务器并不会马上给你返回结果,而是会针对你的SQL进行优化,选择不同的查询算法以最高效的形式返回给应用程序。
例如在做表联合查询时,服务器会根据开销成本来最终决定采用hashjoin,mergejoin,还是loopjoin,采用哪一个索引会更高效等等,不过它的自动化优化是有限的,要想写出高效的查询SQL还是要优化自己的SQL查询语句。
当确定好执行计划后,就会把这个执行计划保存到SQL计划缓存中,下次在有相同的执行请求时,就直接从计划缓存中取,避免重新编译执行计划。
第三步:
语句执行
服务器对SQL语句解析完成后,服务器才会知道这条语句到底代表了什么意思,接下来才会真正的执行SQL语句。
些时分两种情况:
●如果查询语句所包含的数据行已经读取到数据缓冲存储区的话,服务器会直接从数据缓冲存储区中读取数据返回给应用程序,避免了从物理文件中读取,提高查询速度。
●如果数据行没有在数据缓冲存储区中,则会从物理文件中读取记录返回给应用程序,同时把数据行写入数据缓冲存储区中,供下次使用。
说明:
SQL缓存分好几种,这里有兴趣的朋友可以去搜索一下,有时因为缓存的存在,使得我们很难马上看出优化的结果,因为第二次执行因为有缓存的存在,会特别快速,所以一般都是先消除缓存,然后比较优化前后的性能表现,这里有几个常用的方法:
●DBCCDROPCLEANBUFFERS——从缓冲池中删除所有清除缓冲区。
●DBCCFREEPROCCACHE——从过程缓存中删除所有元素。
●DBCCFREESYSTEMCACHE——从所有缓存中释放所有未使用的缓存条目。
SQLServer2005数据库引擎会事先在后台清理未使用的缓存条目,以使内存可用于当前条目。
但是,可以使用此命令从所有缓存中手动删除未使用的条目。
语法分析
SQL语法
Transact-SQL引用中的语法关系图使用下列规则。
规范
用于
大写
Transact-SQL关键字。
斜体
Transact-SQL语法中用户提供的参数。
|(竖线)
分隔括号或大括号内的语法项目。
只能选择一个项目。
[](方括号)
可选语法项目。
不必键入方括号。
{}(大括号)
必选语法项。
不要键入大括号。
[,...n]
表示前面的项可重复n次。
每一项由逗号分隔。
[...n]
表示前面的项可重复n次。
每一项由空格分隔。
加粗
数据库名、表名、列名、索引名、存储过程、实用工具、数据类型名以及必须按所显示的原样键入的文本。
<标签>:
:
=
语法块的名称。
此规则用于对可在语句中的多个位置使用的过长语法或语法单元部分进行分组和标记。
适合使用语法块的每个位置由括在尖括号内的标签表示:
<标签>。
SELECT语句的完整语法为:
SELECT[ALL|DISTINCT|DISTINCTROW|TOP]
{*|talbe.*|[table.]field1[ASalias1][,[table.]field2[ASalias2][,…]]}
FROMtableexpression[,…][INexternaldatabase]
[WHERE…]
[GROUPBY…]
[HAVING…]
[ORDERBY…]
[WITHOWNERACCESSOPTION]
Sql的语法树
SQL输入由一系列命令组成。
一条命令是由一系列记号构成,词法结构包括以下几个元素:
标识符和关键字、常量、操作符、特殊字符、注释、词法优先级。
●标识符和关键字:
SELECT,UPDATE,或VALUES这样的记号都是关键字;
●常量:
字符串常量、数值常量;
●操作符:
+-*/<>=~!
;
●特殊字符:
有些非字母数字字符有一些特殊含义,因此不能用做操作符;
●注释:
注释是任意以双划线开头并延伸到行尾的任意字符序列;
●词法优先级:
大多数操作符都有相同的优先级并且都是左关联的.这种情况可能会有不那么直观的行为;比如,布尔操作符<和>和布尔操作符<=和>=之间有着不同的优先级;
给定一个语言,定义它的文法的一种表示,并定义一个解释器,这个解释器使用该表示来解释语言中的句子。
通过实现解释器模式,把要执行的Sql语句解释为Sql的语法树。
例如一个Select语句的结构如下
数据库中索引原理
什么是索引
索引类似于书的目录,主要用于提高查询效率,也就是按条件查询的时候,先查询索引,再通过索引找到相关的数据,索引相当于记录了对某个关键词,指定到不同的文件,或者文件里的不同位置,当然索引自身也是通过文件来保存的。
索引的类型
有两种基本的索引结构,也就是索引文件的保存方式,一个是顺序索引,就是根据值的顺序排序的(这个文件里面的值,也就是为其建索引的字段值,是顺序的放在索引文件里面),另外一个是散列索引,就是将值平均分配到若干散列桶中,通过散列函数定位的。
顺序索引
顺序索引下面又有很多概念。
如果被索引的字段本身按照一定的顺序排序,那么这种索引叫做聚集索引。
否则叫做非聚集索引。
其实,我们的汉语字典的正文本身就是一个聚集索引。
比如,我们要查“安”字,就会很自然地翻开字典的前几页,因为“安”的拼音是“an”,而按照拼音排序汉字的字典是以英文字母“a”开头并以“z”结尾的,那么“安”字就自然地排在字典的前部。
如果您翻完了所有以“a”开头的部分仍然找不到这个字,那么就说明您的字典中没有这个字;同样的,如果查“张”字,那您也会将您的字典翻到最后部分,因为“张”的拼音是“zhang”。
也就是说,字典的正文部分本身就是一个目录,您不需要再去查其他目录来找到您需要找的内容。
我们把这种正文内容本身就是一种按照一定规则排列的目录称为“聚集索引”。
如果您认识某个字,您可以快速地从自动中查到这个字。
但您也可能会遇到您不认识的字,不知道它的发音,这时候,您就不能按照刚才的方法找到您要查的字,而需要去根据“偏旁部首”查到您要找的字,然后根据这个字后的页码直接翻到某页来找到您要找的字。
但您结合“部首目录”和“检字表”而查到的字的排序并不是真正的正文的排序方法,比如您查“张”字,我们可以看到在查部首之后的检字表中“张”的页码是672页,检字表中“张”的上面是“驰”字,但页码却是63页,“张”的下面是“弩”字,页面是390页。
很显然,这些字并不是真正的分别位于“张”字的上下方,现在您看到的连续的“驰、张、弩”三字实际上就是他们在非聚集索引中的排序,是字典正文中的字在非聚集索引中的映射。
我们可以通过这种方式来找到您所需要的字,但它需要两个过程,先找到目录中的结果,然后再翻到您所需要的页码。
我们把这种目录纯粹是目录,正文纯粹是正文的排序方式称为“非聚集索引”。
通过以上例子,我们可以理解到什么是“聚集索引”和“非聚集索引”。
进一步引申一下,我们可以很容易的理解:
每个表只能有一个聚集索引,因为目录只能按照一种方法进行排序。
何时使用聚集索引或非聚集索引
使用聚集索引
使用非聚集索引
列经常被分组排序
应
应
返回某范围内的数据
应
不应
一个或极少不同值
不应
不应
小数目的不同值
应
不应
大数目的不同值
不应
应
频繁更新的列
不应
应
外键列
应
应
主键列
应
应
频繁修改索引列
不应
应
如果被索引的字段的每个值都有一个索引与其对应(没有重复的值),那么这种索引叫做稠密索引,否则叫做稀疏索引。
从索引本身的数据结构来说,顺序索引分为两类,单级索引(不怎么用)和多级索引(通常是B+树,大量使用)。
●单级索引就是把所有的索引字段以及对应的文件位置按顺序一个个的排列出来,这种索引查找起来比较慢,因为是顺序存储的,可以使用二分查找法,但是总体来说效率不高,这种索引是最基础的索引,一般不用,ORACLE里面好像不支持这种索引。
●多级索引实际上就是在单级索引之上再加索引(稀疏索引),也就是指向索引的索引,二级索引上面还可以再加三级索引,可以不停的加,加到最后最上层只剩下一个节点(根节点),就成了一个树状结构了。
我们经常听到B+树就是这个概念,用这个树的目的和红黑树差不多,也是为了尽量保持树的平衡,当然红黑树是二叉树,但B+树就不是二叉树了,节点下面可以有多个子节点,数据库开发商会设置子节点数的一个最大值,这个值不会太小,所以B+树一般来说比较矮胖,而红黑树就比较瘦高了。
关于B+树的插入,删除,会涉及到一些算法以保持树的平衡,这里就不详述了。
ORACLE的默认索引就是这种结构的。
从索引关联的字段来说,顺序索引又可以分为单独索引和复合索引。
●单独索引是指在一个字段之上建的索引(对这一个字段作为条件查询时会比较快)。
●复合索引是指在多个字段之上建的索引(对这些字段同时作为条件查询时会比较快)。
如果经常需要同时对两个字段进行AND查询,那么使用两个单独索引不如建立一个复合索引,因为两个单独索引通常数据库只能使用其中一个,而使用复合索引因为索引本身就对应到两个字段上的,效率会有很大提高。
散列索引
第二种索引叫做散列索引,就是通过散列函数来定位的一种索引,不过很少有单独使用散列索引的,反而是散列文件组织用的比较多。
散列文件组织就是根据一个键通过散列计算把对应的记录都放到同一个槽中,这样的话相同的键值对应的记录就一定是放在同一个文件里了,也就减少了文件读取的次数,提高了效率。
散列索引呢就是根据对应键的散列码来找到最终的索引项的技术,其实和B树就差不多了,也就是一种索引之上的二级辅助索引,我理解散列索引都是二级或更高级的稀疏索引,否则桶就太多了,效率也不会很高。
位图索引
位图索引是一种针对多个字段的简单查询设计一种特殊的索引,适用范围比较小,只适用于字段值固定并且值的种类很少的情况,比如性别,只能有男和女,或者级别,状态等等,并且只有在同时对多个这样的字段查询时才能体现出位图的优势。
位图的基本思想就是对每一个条件都用0或者1来表示,如有5条记录,性别分别是男,女,男,男,女,那么如果使用位图索引就会建立两个位图,对应男的10110和对应女的01001,这样做有什么好处呢,就是如果同时对多个这种类型的字段进行and或or查询时,可以使用按位与和按位或来直接得到结果了。
文本数据库需实现的模块
查询引擎
查询引擎有语法解析器和执行器两个部分组成,语法解析器根据用户输入的SQL,检查是否有语法错误,如无语法错误则在数据字典中对表、列定义进行参照,确定用户请求的表、列信息是否存在于物理存储中。
一旦语法解析器测试用户输入的SQL成立,则驱动执行器对物理存储进行查询。
执行器参照列定义及索引定义,以确定是否要使用索引,每一列在表中所处的顺序序列、所占的大小各是多少,以决定所使用的查询方案。
并根据确定的查询方案进行查询。
数据字典
通过预定义格式保存每个表的列定义、索引定义,在表创建或者发生变化是修改列定义及索引定义。
存储管理器
参照数据字典,根据预定义格式存储数据,并根据要求生成索引。
在数据需要发生变化时更新表中的数据及相关索引。


- 配套讲稿:
如PPT文件的首页显示word图标,表示该PPT已包含配套word讲稿。双击word图标可打开word文档。
- 特殊限制:
部分文档作品中含有的国旗、国徽等图片,仅作为作品整体效果示例展示,禁止商用。设计者仅对作品中独创性部分享有著作权。
- 关 键 词:
- 数据库 体系结构
 冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 1212中级汽车维修工考试试题三.docx
1212中级汽车维修工考试试题三.docx
-
333教育综合.docx
-
204届毕业生基础知识考试试题 混凝土结构设计 试题.docx
-
100以内加减运算练习题.docx
-
101软件开发工程师JAVA初级考试样卷课件word版本.docx
-
CNN代码理解.docx
-
CPA审计第4章审计抽样下载版讲解.docx
-
hr培训管理系统.docx
-
318安通科科长岗位责任制.docx
-
2044施工现场环境污染的防治措施.docx
-
12371党务平台操作手册.docx
-
Catia百格线生成宏复习过程.docx
-
725kV及以上电压等级支柱瓷绝缘子运行规范.docx
-
1144甑底链板机说明书.docx
-
100个著名初等数学问题.docx
-
201X中学寒假工作计划范文.docx
-
111 生物的特征 练习 人教版七年级上册生物.docx
-
110KV变电所设计变压器翻译.docx
-
9920第二学期学校工作总结.docx
-
0911二级技能解答.docx
-
33415设计说明书正文.docx
-
311教育学基础综合大纲.docx
-
201浙江普通高校招生选考科目考试地理试题和答案解析.docx
-
C语言程序的设计实验实验指导书及答案.docx
-
272相似三角形的性质和判定.docx
-
ACCAHA不稳定型心绞痛和非ST段抬高心肌梗死治疗指南修订版摘要.docx
-
baosteel标准对照 外标含量.docx
-
M1模拟练习题.docx
-
ARM体系课程设计实验报告.docx
-
Android面试题整理.docx
-
gaoer.docx
-
CPⅢ测设方案.docx
-
上海市小升初20篇完形填空精品资料含详细答案解析详细答案2Word下载.docx
-
初中物理电学练习题附答案Word下载.docx
-
社会心理学学习心得体会共33页Word格式文档下载.docx
-
生物质纤维项目可行性研究报告Word格式文档下载.docx
-
深圳市福田区产业发展资金支持金融业和企业上市实施细则Word下载.docx
-
精选完整培训机构微信公众号平台规划运营可行性方案Word文档下载推荐.docx
-
高中语文要求掌握的120个文言实词答案Word文档下载推荐.docx
-
施工电梯方案Word文档格式.docx
-
供电系统采用三相五线制精Word文件下载.docx
-
多菌种酿造酱油项目投资计划书Word下载.docx
-
led灯销售工作总结工作范文文档格式.docx
-
时间序列分析基于R习题答案Word文件下载.docx
-
高二下学期期末考试政治试题Word格式文档下载.docx
-
休闲体育专业培养方案含教学计划文档格式.docx
-
购房合同变更名字文档格式.docx
-
学年浙江省嘉兴市高一上学期期末考试历史试题扫描版 含答案Word下载.docx
-
无公害蔬菜可行性研究报告Word格式文档下载.docx
-
广场园林铺装砖项目投资计划书文档格式.docx
-
施工便道施工方案(1)Word文档下载推荐.docx
