 access疑难问题.docx
access疑难问题.docx
- 文档编号:7365108
- 上传时间:2023-01-23
- 格式:DOCX
- 页数:19
- 大小:137.75KB
access疑难问题.docx
《access疑难问题.docx》由会员分享,可在线阅读,更多相关《access疑难问题.docx(19页珍藏版)》请在冰豆网上搜索。
access疑难问题
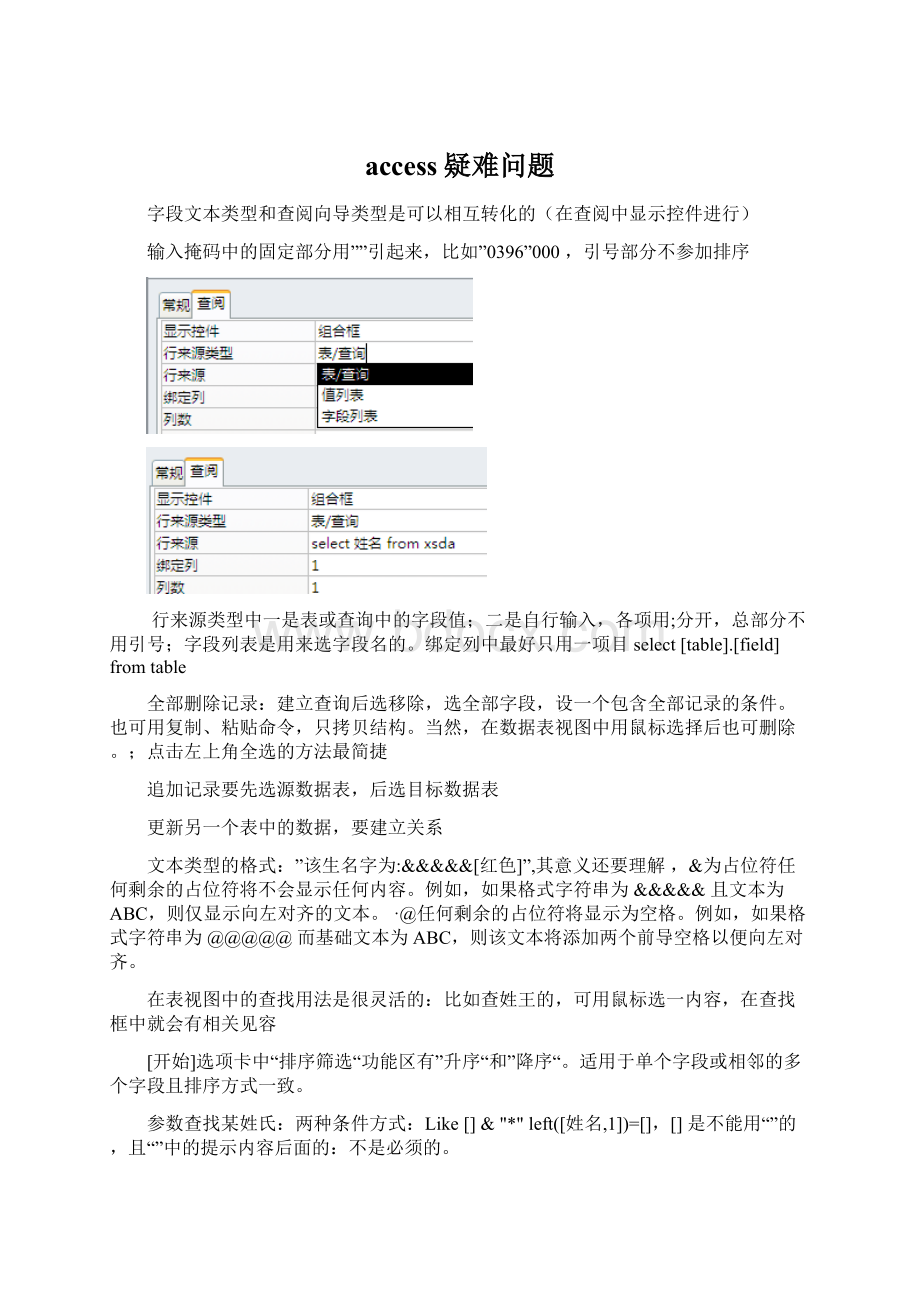
字段文本类型和查阅向导类型是可以相互转化的(在查阅中显示控件进行)
输入掩码中的固定部分用””引起来,比如”0396”000,引号部分不参加排序
行来源类型中一是表或查询中的字段值;二是自行输入,各项用;分开,总部分不用引号;字段列表是用来选字段名的。
绑定列中最好只用一项目select[table].[field]fromtable
全部删除记录:
建立查询后选移除,选全部字段,设一个包含全部记录的条件。
也可用复制、粘贴命令,只拷贝结构。
当然,在数据表视图中用鼠标选择后也可删除。
;点击左上角全选的方法最简捷
追加记录要先选源数据表,后选目标数据表
更新另一个表中的数据,要建立关系
文本类型的格式:
”该生名字为:
&&&&&[红色]”,其意义还要理解,&为占位符任何剩余的占位符将不会显示任何内容。
例如,如果格式字符串为&&&&&且文本为ABC,则仅显示向左对齐的文本。
·@任何剩余的占位符将显示为空格。
例如,如果格式字符串为@@@@@而基础文本为ABC,则该文本将添加两个前导空格以便向左对齐。
在表视图中的查找用法是很灵活的:
比如查姓王的,可用鼠标选一内容,在查找框中就会有相关见容
[开始]选项卡中“排序筛选“功能区有”升序“和”降序“。
适用于单个字段或相邻的多个字段且排序方式一致。
参数查找某姓氏:
两种条件方式:
Like[]&"*"left([姓名,1])=[],[]是不能用“”的,且“”中的提示内容后面的:
不是必须的。
在查询中构造:
总分:
[语文]+[数学]字段是可以的 SELECT姓名,语文+数学as总分fromxscj
取入学分数最低的3条记录,且分数由高到低
SELECTtop3*from(selecttop3*fromxscjorderby合计asc)orderby合计desc
在查询字段中,不能出现聚合计算
在查询中可用delele*from表名droptable表名等select语句,在vba中DoCmd.RunSQL"delete*fromzggz",DoCmd.RunSQL"droptablexk1”,docmd.runsql可运行操作查询。
如果录入为文本型的字符,用双引号””;如果录入为日期型的字符,用井号#;如果录入为数字型字符不需要加任何符号。
在单独写的时候可以不录入符号,主要在录入表达式时需要录入符号。
有效性规则只是对新录入的数据进行限制,对已有数据没有影响。
Msgbox()中可用字符串提示,也可用来输出值?
msgbox(a)msgboxamsgbox”a”也行,就是说msgbox()msgbox””即可以输出字符串,出可以输出变——也就是提示信息即可以是字符串常量,也可以是变量。
A=Inputbox(“JHLKJ”)可以输入字符,也可以是数字,VBA编程时inputbox有两种用法,一个是inputobx函数,一个是application.inputbox方法,两者用法差不多,差别在后者多了输入类型,导致返回值也有很大不同。
1、inputobx函数在输入字符串后点击“确认”按钮返回字符串,如果需要数值,可以用val函数转换,点击“取消”则返回空字符串。
其用法如下:
InputBox(prompt[,title][,default][,xpos][,ypos][,helpfile,context])
该函数必须具有的参数是prompt,其它都是可选函数。
2、application.inputbox在输入字符串后点击“确认”按钮根据type类型返回不同类型的值,点击“取消”则返回逻辑值false,其用法如下:
application.inputobx(prompt,title,default,left,top,helpfile,helpcontextid,type)
同样也是prompt是必选参数,其它是可选参数。
其中type为0返回文本,type为1返回数字type为2返回公式 ,4逻辑值8单元格引用16错误值 64数值数组。
type不指定时,系统根据输入智能判断数据类型。
2、信息输出函数
在VBA中,经常使用MsgBox函数,来显示用户定义的提示信息,该函数基本格式为:
MsgBox(提示[,按钮]),标题])
其中,“提示”表示要在对话框中显示的字符;‘“按钮”是整型表达式,用于指定对话框中显示的按钮、图标、和默认按钮;“标题”用于指定显示在对话框标题栏中的字符。
窗体的引用[Forms]!
[ct].Caption="kjjkjk",(方括号可省略),如果引用自身可用me.caption.自定义对象引用“!
”,系统定义的对象引用用“。
”Me!
Command0.Caption="qqq"。
Me是指窗体级。
在查询中求平均数时的小数位设置:
右点击该项,选属性,格式选固定,小数位数自定。
若用round(),形式如图:
(对基本运算处理,才可用expression?
)
查询汇总Expression是“表达式”,就是说这个显示结果不是表里固有的字段,而是其他字段通过函数计算得出来的结果。
空值参与运算用nz(),在查询中才能使用nz()函数
在窗体中可使用条件格式须在属性表中对窗体格式---默认视图改为数据表,在数据表选项中设定。
(创建-其它窗体-数据表-条件格式)
给普通变量赋值使用set,只是set可以省略。
'给对象变量赋值使用SET,SET不能省略。
delete*fromxsda1where出生日期<(selectmax([出生日期])fromxsda1)
delete*fromb2where姓名notin(SELECT姓名fromb1)用select子句作条件删除记录,在查询中执行
searchforrecord的用法DoCmd.SearchForRecordacDataForm,"ct1",acFirst,"姓名='"&Me.Text3&"'"
关于在ACCESS中对变量引用时的引号处理,很多前辈都有论述
大致的情况如下:
数字型变量:
"&变量&"
文本型变量:
'"&变量&"'
日期型变量:
#"&变量&"#
创建子窗体的三个方法:
1,同时。
2,先创主窗体,后在主窗体中用向导建子窗体。
3,向主窗体中添加子窗体(拖曳)。
让子窗体2中的数据随主窗体的数据变化(即使它们有同一数据源)
PrivateSubForm_Load()
SetMe.窗体2.Form.Recordset=Me.Recordset
EndSub
自动编号型也可用”js”000格式
@ 该位置可显示任意可用的字,没有字符则显示空格
& 同上,没有字符则不显示
<英文小写
> 英文大写
!
左对齐
.右对齐
[颜色]显示括号内的颜色
UNIONALL这个指令的目的也是要将两个SQL语句的结果合并在一起。
UNIONALL和UNION不同之处在于UNIONALL会将每一笔符合条件的资料都列出来,无论资料值有无重复。
UNIONALL的语法如下
[SQL语句1]
UNIONALL
[SQL语句2];
Union因为要进行重复值扫描,所以效率低。
如果合并没有刻意要删除重复行,那么就使用UnionAll。
重复是指记录数据中各字段都相同,单独使用union会按写在前面的字段排序。
两个要联合的SQL语句字段个数必须一样,而且字段类型要“相容”(一致);使用union(all)是新生成一个查询。
和追加不一样。
在窗体的数据表视图中可设置条件格式及每列颜色、前景色。
Docmd.openquery“cx1”不须要引用“…….”
Like"[01]"注意一定要带上””
access中的窗体的记录源可以是多个吗?
要怎么操作?
可用查询作为数据源
或者,如果只能是一个的话,我要怎样实现将来自不同表或查询中的数据在一个窗体中显示?
同时只能有一个,但可在事件中用VBA更换:
me.RecordSource="另一表名"
或
me.RecordSource="另一查询名"
或
me.RecordSource="SELECTSQL语句
在表的设计视图中更改货币类型为$,需要更改区域和语言中把,默认的中国,改成英语(美国),然后¥就变成$
主要区别就在于作用范围不一样:
private在窗体里面定义,就在窗体里面有用;
dim只在一段程序里面有用;
public是在整个acess数据库这个文件里面定义有用。
Public用于定义全局变量。
Private用于定义模块级变量。
Dim用于定义过程级变量,(同时还可以用于定义模块级变量,但为了更容易理解,一般定义模块级变量时建议只用Private不用Dim)
新建一模块或打开已有的一个模块,在OptionCompareDatabase这一语句之下定义公共变量,如:
PublicUname,Pword,UTypeAsVariant
则变量Uname,Pword,UType在整个Access数据库中都可以使用,成为全局变量。
全局变量不是在窗体中定义的。
运算符"&"与"+"的比较&能把数字转化为串,+、-、*、/能把串转化为数字进行运算。
字符的大小顺序:
汉字字符>字母(按字母顺序且大小写相同)>数字>空格
文本框在设计时显示的是数据来源,不是value的值,value是默认值
禁止关联标签的自动添加
引用另一个窗体的控件属性Label11.Caption=Forms!
ct2!
Label0.Captionct2为保存的窗体名,既导航窗格中的名字,引用的窗体要打开。
组合框绑定列是指列数与指定的数据源字段绑定
空字符串:
已经分配了存储空间,但是没有存储东西
NULL:
没有分配存储空间
在格式中输入@@[红色];”“空数据””[蓝色],则有数据项红色显示,无数据项蓝色显示。
只读方式打开:
采用这种方式打开数据库,只能查看而无法编辑数据库,可以防止数据修改。
以独占只读方式打开:
一个用户采用这种方式打开数据库,该用户只能查看而无法编辑数据库,其他用户只能以只读方式打开此数据库。
Text0=Text0&"中华人民共和国"&Chr(13)&Chr(10)可换行,顺序不能错
access索引是什么?
无、有(无重复)、有(有重复)的区别
最好举例说明,比如为什么在学生成绩管理中,姓名的索引项为无,学号的索引项为有(无重复)
假如一个字段的索引被设置为“有”,那么会显著加快查询的速度,尤其数据量相当大时。
当然我们一般并不需要了解程序是如何加快查询速度的。
对于经常需要进行查询检出的字段我们可以将该字段的索引设置为“有”。
比如你的例子中的“学号”,显然学号不会重复,所以可以将其设置为有(无重复);我们也会经常查询姓名,所有“姓名”也要将其索引设置为有,但姓名会重复,所以应该设置为有(有重复);比如还有一个字段“学生情况简介”,我们一般不会对这样的字段内容进行查询,所以可将其索引设置为“无”。
另外,有些字段虽然经常被查询,但其内容简单,这种情况下索引不一定要设置为“有”,设置过多的索引会占用程序过多的资源,反而速度下降。
比如“性别”字段,只有男女,这就设置为“无”即可;再比如“班级”字段,如果班级不是特别多,索引也不要设置为“有”。
【原创】Access组合框使用技巧
在Access中,主表常用用数字ID代表一些值,附表中储存ID和其所代表的值,例如主表中使用1、2、3……,附表中存储1:
汉族;2:
彝族;3:
傣族……,那么在输入数据或打印数据时,如何从附表中查询出ID所代表的值,从而显示或打印出具体的值,而非看不懂的ID数字呢?
其实就是使用组合框来实现,但首先让我们来再认识一下组合框这个控件。
组合框的数据有两个分支,一个是“控件来源”,即数据源;一个是“行来源”,即下拉列表的来源。
组合框总是显示行来源的第一列,而实际的数据可以认为设定绑定第几列。
一般来讲,窗体上的所有数据控件都只能有一个数据源,而组合框的“行来源”却可以相对独立,是一个国中之国,也为我们带来了方便。
“数据源”链接到主表的数字ID,行来源指向附表或查询附表的ID及值两个字段,组合框应绑定ID所在列,因为组合框总是显示第一列,如果第一列就是ID(一般都如此),则可以将列数设为2,第一列的宽度设置为“0cm”,呵呵,使它消失,自然就只能显示第二列的值了。
控件来源:
窗体/报表中的绑定控件,一般来说都是用来显示某个表中某条记录中某字段的值,控件来源指的就是这个字段的名称,根据这个名称才能把对应字段的值显示出来
也有用公式做控件来源的,本质上和字段是一样的
行来源:
只有组合框和列表框控件才有这个属性,这个属性决定的是组合框/列表框的可供选择的选项列表
nz函数,如果表达式是数字类型,表达式为null时会转化为数值0,非null则仍为原数值;如果表达式是文本类型,表达式为null时会转化为""(既空字符串),非null则仍为原文本。
比如有如下字段及值:
姓名语文数学英语
张三607080
李四80null90
……
假设我们要计算总成绩,设置:
总成绩=[语文]+[数学]+[英语]那么张三的总成绩=60+70+80,=210;由于包含任何null值的计算仍为null值,李四的总成绩=80+null+90,=null,而不会得到我们认为的170。
为了避免这种情况,可以用nz函数,以达到正确的计算值,如上例子,设置:
总成绩=nz([语文])+nz([数学])+nz([英语]),这样不管有没有null值(空值转化为了0,能正确计算),都能得到正确的结果。
计算字段不能使用nz
字段选择框中的一种写法:
住址:
"家庭住址:
"+[籍贯]
表现评价:
Replace([评价],"良好","好"),只查询,不改变表中的值。
Update表SET字段=replace(字段,"原字符","替换字符")
UPDATExsdaSETxsda.籍贯=replace(籍贯,"平舆","平玉");
UPDATExsdaSETxsda.籍贯="汝南" WHERE(((xsda.籍贯)="确山"));
DateSerial函数是返回一个指定的日期,有三个参数,年月日,也就是说你给它指定年月日,它给你返回一个日期,这看上去有点多此一举,但它返回的日期是一个通用的日期格式,不受你系统日期格式限制的.所以,它返回的日期放之四海皆可认.
例如:
DateSerial(2012,8,1),它就反回今年的8月1日这个日期,至于是什么样的格式,什么样的年月日顺序,将根据你的系统控制面板里的设置而定.
第一范式就是原子性,字段不可再分割;
第二范式就是完全依赖,没有部分依赖;
第三范式就是没有传递依赖。
Page不能在窗体页脚中使用,在窗体页面页脚中使用时只能在打印预览中才能看到效果
TEXT属性必须在文本框获得焦点的情况下才能引用,系统会在焦点离开文本框时将最后出现的TEXT值保存为VALUE值,焦点离开文本框后如果引用其TEXT属性就会报错。
VALUE属性则是文本框失去焦点后文本框里的值,或者文本框获得焦点时输入新值前的原有值或者说旧值。
Value是默认值
在xsda中查找xscj中没有的记录:
SELECTxsda.姓名fromxsdawherexsda.姓名notin(select姓名fromxscj) 。
不需要建立关系
SQL语句里使用distinct谓词,指对有重复的记录行只取唯一的一条记录(它针对的是所有的输出字段且这些字段值的组合必须是唯一),该谓词必须放在输出字段列表的前面,而不得单独应用到某个字段里,否则必然报错。
“Where”是一个约束声明,使用Where来约束来之数据库的数据,Where是在结果返回之前起作用的,且Where中不能使用聚合函数。
“Having”是一个过滤声明,是在查询返回结果集以后对查询结果进行的过滤操作,在Having中可以使用聚合函数。
聚合函数,SQL基本函数,聚合函数对一组值执行计算,并返回单个值。
除了COUNT以外,聚合函数都会忽略空值。
聚合函数经常与Select语句的GROUPBY子句一起使用。
HAVING子句可以让我们筛选成组后的各组数据,Where子句在聚合前先筛选记录.也就是说作用在GROUPBY子句和HAVING子句前;而HAVING子句在聚合后对组记录进行筛选。
让我们还是通过具体的实例来理解GROUPBY和HAVING子句:
SQL实例:
一、显示每个地区的总人口数和总面积:
Selectregion,SUM(population),SUM(area)
FROMbbc
GROUPBYregion
先以region把返回记录分成多个组,这就是GROUPBY的字面含义。
分完组后,然后用聚合函数对每组中的不同字段(一或多条记录)作运算。
二、显示每个地区的总人口数和总面积.仅显示那些人口数量超过1000000的地区。
Selectregion,SUM(population),SUM(area)
FROMbbc
GROUPBYregion
HAVINGSUM(population)>1000000
select籍贯,count([学号])fromxsdagroupby籍贯havingcount([学号])>=3
删除重复记录
DELETE编号
FROM表1
WHEREidnotin(selectmin(id)from表1groupby编号);
Docmd是一个对象,可在vba中运行运行MicrosoftAccess操作。
格式是docmd.方法。
方法有多种比如打开报表openform等等,在运行sql时格式为SQLStatement 必需 Variant 型。
字符串表达式,表示操作查询或数据定义查询的有效 SQL 语句。
它使用 INSERT INTO、DELETE、SELECT...INTO、UPDATE、CREATE TABLE、ALTER TABLE、DROP TABLE、CREATE INDEX 或 DROP INDEX 语句。
看见了没有?
没有 SELECT ... FROM 语句,因此不允许用 RUNSQL 来运行 SELECT 查询
DoCmd.RunSQL"SELECT学号,姓名intoaaafromxsda"可用变量
PrivateSubCommand4_Click()
Forms!
[ct1]!
[Text2]=Forms!
[ct3]!
[Text0].Text
EndSub
显示图像:
绑定控件只显示bmp,用附件控件可显示多种类型(多个图像可依次显示)
取消子数据表:
在表设计中―――属性表-----取消子数据表名称
追加查询:
在设计中上窗口只选数据源表
INSERTINTOxm(姓名,学号,fs)select姓名,学号,fs2fromxm2wherefs2>60
INSERTINTOxm(姓名,学号,fs)values(“姓名”,“学号”)
查找重复项
SELECTxsda.[学号],xsda.[姓名],xsda.[性别],xsda.[入学分数]
FROMxsda
WHERE(((xsda.[学号])In(SELECT[学号]FROM[xsda]AsTmpGROUPBY[学号],[姓名]HAVINGCount(*)>1And[姓名]=[xsda].[姓名])))
ORDERBYxsda.[学号],xsda.[姓名];
select*fromxsdawhere姓名in(SELECT姓名FROMxsdaGROUPBY姓名HAVINGCount(*)>1)orderby姓名
SQLSelect语句完整的执行顺序:
1、from子句组装来自不同数据源的数据;
2、where子句基于指定的条件对记录行进行筛选;
3、groupby子句将数据划分为多个分组;
4、使用聚集函数进行计算;
5、使用having子句筛选分组;
6、计算所有的表达式;
7、select的字段;
8、使用orderby对结果集进行排序
1.FROM:
对FROM子句中的前两个表执行笛卡尔积,生成虚拟表VT1。
2.ON:
对VT1应用ON筛选器。
只有那些使为真的行才被插入VT2。
3.OUTER(JOIN):
如果指定了OUTERJOIN,保留表中未找到匹配的行将作为外部行添加到VT2,生成VT3。
如果FROM子句包含两个以上的表,则对上一个联接生成的结果表和下一个表重复执行步骤1到步骤3,直到处理完所有的表为止。
4.对VT3应用WHERE筛选器。
只有使为TRUE的行才被插入VT4。
5.GROUPBY:
按GROUPBY子句中的列列表对VT4中的行分组,生成VT5。
6.CUBE|ROLLUP:
把超组插入VT5,生成VT6。
7.HAVING:
对VT6应用HAVING筛选器。
只有使为TRUE的组才会被插入VT7。
注:
having不能单独使用,having子句是对分组后的记录的筛选,所以有having必须要有groupby
8.SELECT:
处理SELECT列表,产生VT8。
9.DISTINCT:
将重复的行从VT8中移除,产生VT9。
10.ORDERBY:
将VT9中的行按ORDERBY子句中的列列表排序,生成一个有表(VC10)。
11.TOP:
从VC10的开始处选择指定数量或比例的行,生成表VT11,并返回给调用者。
注:
topn可以实现分页
selecttop20*from雇员
分组sort,求前2项fs
SELECT*FROMtASa
WHERE(((a.[fs])In(selecttop2fsfromtwheret.sort=a.sortorderbyfsdesc)));
wheret.sort=a.sortorder这一句不必拘泥原因,总之结合top2能求出每个组的前两名
TypeName ( varname )测试类型
Static是定义静态变量和数组变量,Dim定义的叫自动变量。
Static定义的变量,每次引用它时,变量的值会继续保留;而Dim定义的变量,每次引用它时,则会重新赋值。
举个例子你就会懂,看下面两段代码:
Subaa()
DimbAsInteger
StaticcAsInteger
c=c+1
b=b+1
Debug.Print"b",b
Debug.Print"c",c
EndSub
b不变,c累加
还有一点要说明,Stat


- 配套讲稿:
如PPT文件的首页显示word图标,表示该PPT已包含配套word讲稿。双击word图标可打开word文档。
- 特殊限制:
部分文档作品中含有的国旗、国徽等图片,仅作为作品整体效果示例展示,禁止商用。设计者仅对作品中独创性部分享有著作权。
- 关 键 词:
- access 疑难问题
 冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 铝散热器项目年度预算报告.docx
铝散热器项目年度预算报告.docx
-
牛津上海版通用小学英语三年级上册Unit 12同步练习2II 卷.docx
-
论我国私营企业员工激励机制.docx
-
人教版五年级品德与社会上册全册教案.docx
-
开学啦国旗下讲话稿三分钟.docx
-
露天采矿学复习题.docx
-
六年级英语教师年度考核个人总结.docx
-
某路站综合体项PC吊装施工方案.docx
-
人教版九年级历史上册期末考试试题一套.docx
-
隆昌妇幼保健院.docx
-
芦二矿抽采达标中长期规划.docx
-
看拼音写词语.docx
-
模拟磁盘调度算法系统的设计毕业设计.docx
-
每周一条名言警句或一首诗词.docx
-
棉花膜下滴灌示范工程设计总结报告.docx
-
九年级化学教案第十单元酸和碱教案新人教版.docx
-
宁波市水资源公报.docx
-
农业实用技术培训工作意见与农业局上半年工作总结范例两篇汇编.docx
-
平行线的判定.docx
-
内部会计管理制度11成本核算制度.docx
-
盘扣式脚手架支撑方案.docx
-
旅游规划模板.docx
-
煤矿大本大专毕业设计大采高综采工作面作业规程.docx
-
美学选择题整理课件资料.docx
-
名家论腹泻慢性肠炎.docx
-
宁夏银川市第一中学学年高一上学期期中考试地理试题解析解析版.docx
-
年产吨精密纤维纸项目建设建议书.docx
-
农技推广中心工作总结.docx
-
彭宇案的法逻辑批判.docx
-
宁夏仕奇房产网发布份房地产交易情况.docx
-
项目推荐书智能温控节能系统.docx
-
区县节日期间加强消防安全讲话稿与区发改委领导班子述职述廉报告汇编.docx
-
变电站投运前质量监督检查汇报材料模版.docx
-
急救护理常规及抢救规程.docx
-
步进电机驱动设计方案.docx
-
高二英语上学期期末考试试题牛津译林版.docx
-
部编版一年级语文下册生字表笔顺笔画.docx
-
材料科学与工程基础第二章习题答案题目整合版.docx
-
高考生物二轮热点专题专练钻石卷综合测试高考中的热点题型新人教版.docx
-
财务案例分析.docx
-
高空作业安全常识.docx
-
财务管理不规范整改.docx
-
高三下学期半月考文综地理试题 含答案.docx
-
财务账目中英文对照.docx
-
参加现场工作人员安全培训考试试题.docx
-
高新技术企业认定申请书样表.docx
-
诚信的心得体会doc.docx
-
初中化学重点难点知识点总结全.docx
-
高一下学期期末考试英语试题 含答案I.docx
-
初中物理竞赛教程基础篇第23讲 电路.docx
-
格宾石笼施工方案.docx
