 卷积神经网络ConvolutionalNeuralNetworksCNN摘要.docx
卷积神经网络ConvolutionalNeuralNetworksCNN摘要.docx
- 文档编号:6721607
- 上传时间:2023-01-09
- 格式:DOCX
- 页数:14
- 大小:296.15KB
卷积神经网络ConvolutionalNeuralNetworksCNN摘要.docx
《卷积神经网络ConvolutionalNeuralNetworksCNN摘要.docx》由会员分享,可在线阅读,更多相关《卷积神经网络ConvolutionalNeuralNetworksCNN摘要.docx(14页珍藏版)》请在冰豆网上搜索。
卷积神经网络ConvolutionalNeuralNetworksCNN摘要
卷积神经网络ConvolutionalNeuralNetworks(CNN)
一、什么是卷积
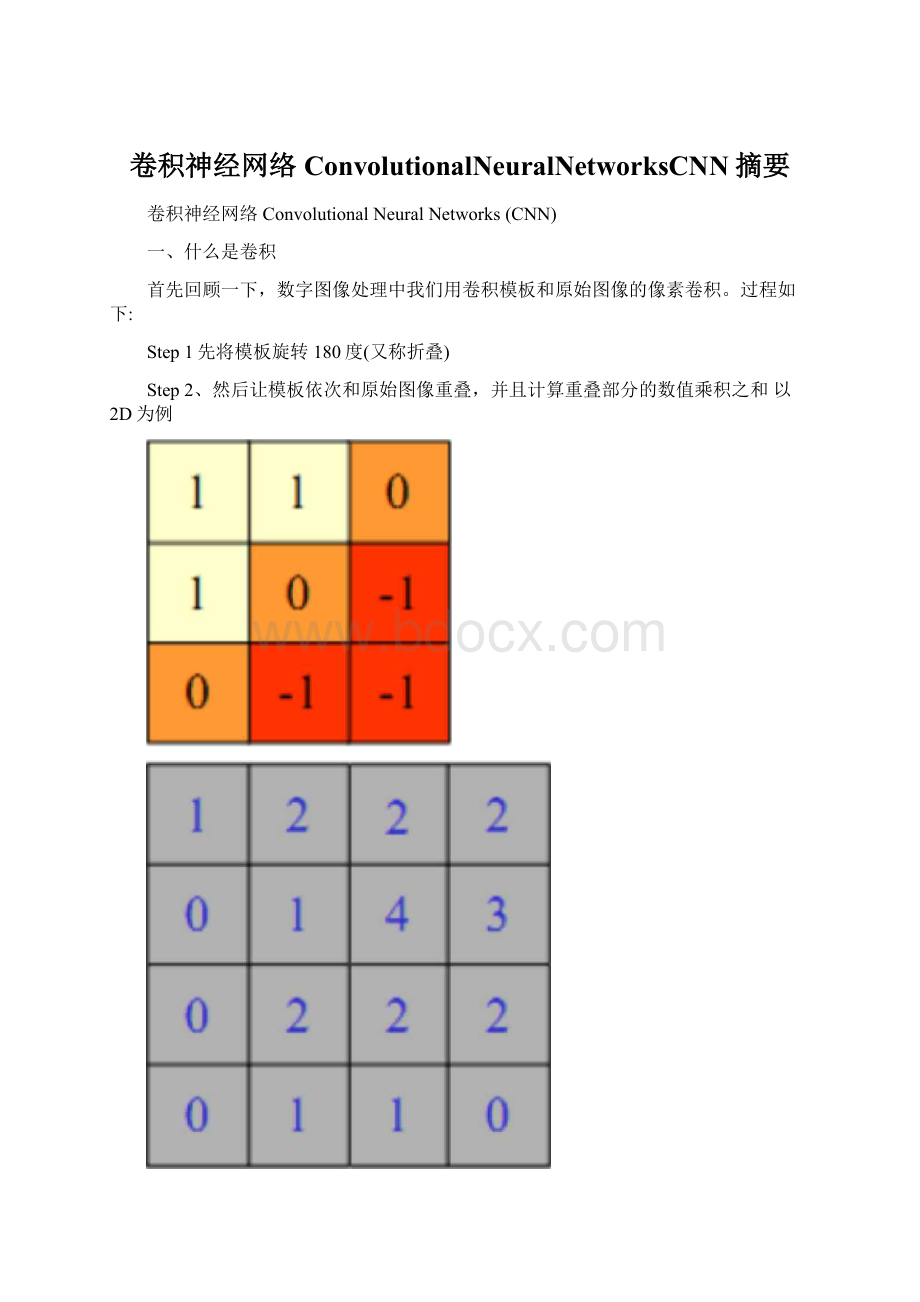
首先回顾一下,数字图像处理中我们用卷积模板和原始图像的像素卷积。
过程如下:
Step1先将模板旋转180度(又称折叠)
Step2、然后让模板依次和原始图像重叠,并且计算重叠部分的数值乘积之和以2D为例
K卷积模板(Kernel),I原始图像
先对模板K做折叠,然后依次覆盖图像I,并且计算重叠部分的数值乘积之和
依次进行到最后,会多出一圈,得到最后的卷积结果
1
3
4
4
2
]
3
6
7
1
-2
0
2
5
2
-6
-5
0
3
3
-4
-9
-5
0
1
-1
-5
_2
0
0
-1
-2
▼1
0
卷积的意义(图像处理而言);对图像使用不同的卷积模板,对图像做不同的处理。
比如平滑模板可以使图像模糊,并且可以减少噪声、锐化模板可以使图像的轮廓变得清晰。
二、卷积网络的结构
2.1从BP网络到卷积网络
回想一下BP神经网络。
BP网络每一层节点是一个线性的一维排列状态,层与层的网络节点之间是全连接的。
这样设想一下,如果BP网络中层与层之间的节点连接不再是全连接,而是局部连
接的。
这样,就是一种最简单的一维卷积网络。
如果我们把上述这个思路扩展到二维,这就是我们在大多数参考资料上看到的卷积神经网络。
具体参看下图:
FULLYCONNECTEDNEURALNET
LOCALLYCONNECTEDNEURALNET
Ex^mpre:
1000x1000ivnagt
iMhrddenynits
10*12jMror«t 'll -Spctialcorrelationi占local -BettertoputresMirceseJsewhcrc* l^anzei E也仰俺;JOQOkIOOOima赛IMhiddenuniffFiltersize-10x10100Mparamfefi^S 图1: 全连接的2D网络(BP网络)图2: 局部连接的2D网络(卷积网络) 现在我们考虑单隐层结构, 上图左: 全连接网络。 如果我们有1000x1000像素的图像,有1百万个隐层神经元,每个隐层神经 元都连接图像的每一个像素点,就有1000x1000x1000000=10X2个连接,也就是10X2个权值参数。 上图右: 局部连接网络,每一个节点与上层节点同位置附近10x10的窗口相连接,则1百万个隐层 神经元就只有100w乘以100,即10A8个参数。 其权值连接个数比原来减少了四个数量级。 因此,卷积网络降低了网络模型的复杂度,减少了权值的数量。 该优点在网络的输入是多维图像时 表现的更为明显,使图像可以直接作为网络的输入,避免了传统识别算法中复杂的特征提取和数据重建过程。 2.2卷积网络的结构 卷积神经网络是一个多层的神经网络,每层由多个二维平面组成,而每个平面由多个独立神经元组成。 卷积神经网络中的每一个特征提取层(C-层)都紧跟着一个用来求局部平均与二次提取的 INPUT 32x32 C1: featuremaps C3f.maps16@10xW S4: f.maps16@5x5 S2.fmaps F6: layerOUTPUT 8410 下采样层(S-层),这种特有的两次特征提取结构使网络在识别时对输入样本有较高的畸变容忍能力。 Convolulions Gaussianconnections SibsamplingConvolutiocsSubsamplingFullconneclion 图3经典的卷积神经网络结构图 原始图像的大小决定了输入向量的尺寸,隐层由C-层(特征提取层)和S-层(下采样层)组成,每 层均包含多个平面。 C1层神经元提取图像的局部特征,因此每个神经元都与前一层的局部感受野(也 就是局部输入窗口)相连。 C1层中各平面(由神经元构成)提取图像中不同的局部特征,如边缘特 征,上下左右方向特征等,C1层中的输入是有由上一层局部窗口的数值和连接的权值的加权和(也 就是卷积,后面会具体解释为什么是卷积),然后通过一个激活函数(如sigmoid函数,反正切函数)得到C1层的输出,接下来S2层是下采样层,简单来书,由4个点下采样为1个点,也就是4个数 的加权平均。 换句话说,就是我们把2*2的像素缩小成为一个像素,某种意义上来说可以认识是图 像处理中的模糊。 然后按照这个C—S的结构继续构成隐层,当然这些隐层的连接都是局部相连的。 同时有人会问了,例如S2和C3层具体要怎么连接呢,为什么会从6张变成16张特征图呢。 C3层的特征图是由S2层图像的感受野和对应权值的卷积后,通过随机的组合而形成的,也就意味着S2 层和C3层并不像C1层和S2层那样是一一对应的。 但当我们感受野的大小和图像一样时,我们经过特征提取后就变成一个像素了,这里我们开始使用全连接(这样才能完整的把特征保留)。 2.3为什么给这种局部连接命名为卷积网络 卷积网络第一个特点是连接权值远远小于BP网络的权值。 卷积神经网络另外一个特性是权值 共享。 这样一来就更进一步减少了对网络权值的训练(毕竟权值是共享的,也就意味着有一些全是 是相同的)。 权值共享是指同一平面层的神经元权值相同。 如何理解呢! 看下图2,假设红色的点和 黑色的点是C1层第一个特征图的2个不同神经元,感受窗口的大小是5*5的(意味着有25个连接),这2个神经元连接的权值是共享的(相同的)。 这样一来,C1层中的每个神经元的输入值,都有由 原始图像和这个相同的连接权值的加权和构成的,想想看,这个过程是不是和卷积的过程很像呢! 没错,就是由这个得名的。 同时这样一来,我们需要训练的权值就更少了,因为有很多都是相同的。 LOCALLYCONNECTEbNEURALNET 图2: 局萤连接的2D郦备(卷积网络)- 32.f.maps 6@Hx14 Gaussianconnections Fullcom C1: featuremaps 54: f.maps16@5x5 INPUT32x32 黑晌Fe: layerOUTPUT 1208410 还没理解的话,接着看 C1层是一个卷积层(也就是上面说的特征提取层),由6个特征图FeatureMap构成。 特征图中每 个神经元与输入中5*5的邻域相连。 特征图的大小为28*28。 C1层有156个可训练参数(每个滤波 器5*5=25个unit参数和一个bias[偏置]参数,一共6个滤波器,共(5*5+1)*6=156个参数),共156*(28*28)=122,304个连接。 S2层是一个下采样层,有6个14*14的特征图。 特征图中的每个单元与C1中相对应特征图的 2*2邻域相连接。 S2层每个单元的4个输入相加,乘以一个可训练参数,再加上一个可训练偏置。 结果通过sigmoid函数计算。 每个单元的2*2感受野并不重叠,因此S2中每个特征图的大小是C1 中特征图大小的1/4(行和列各1/2)。 S2层有12个可训练参数和5880个连接。 C3: f.maps16@10x10 Convoljlions SibsamplingCorwolutjocsSubsamplingFullconneclion三、卷积网络的训练 我们想想卷积网络到底有什么那些参数需要训练呢。 第一、卷积层中的卷积模板的权值。 第二、下采样层的2个参数(每个单元的4个输入相加,乘以一个可训练参数,再加上一个可训练偏置), 第三、学习特征的组合(例如S2到C3的组合方式) 3.1我们先回顾一下BP的反向传播算法 3.1.1、FeedforwardPass前向传播 在下面的推导中,我们采用平方误差代价函数。 我们讨论的是多类问题,共c类,共N个训练 样本。 EJ揽士以-朋. n=1jt=l 这里表示第n个样本对应的标签的第k维。 表示第n个样本对应的网络输出的第k个输出。 对于多类问题,输出一般组织为“oneof-c”的形式,也就是只有该输入对应的类的输出节点输 出为正,其他类的位或者节点为0或者负数,这个取决于你输出层的激活函数。 sigmoid就是0,tanh就是-1. 因为在全部训练集上的误差只是每个训练样本的误差的总和,所以这里我们先考虑对于一个样本的BP。 对于第n个样本的误差,表示为: c 1I 曰=㊁刀何-城)2=押―严喙 传统的全连接神经网络中,我们需要根据BP规则计算代价函数E关于网络每一个权值的偏导 数。 我们用I来表示当前层,那么当前层的输出可以表示为: =/(u*,withu*=W'x'T+b‘ 输出激活函数f(.)可以有很多种,一般是sigmoid函数或者双曲线正切函数。 sigmoid将输出压缩到[0,1],所以最后的输出平均值一般趋于0。 所以如果将我们的训练数据归一化为零均值和方差为1,可以在梯度下降的过程中增加收敛性。 对于归一化的数据集来说,双曲线正切函数也是不错的选择。 3.1.2、BackpropagationPass反向传播 反向传播回来的误差可以看做是每个神经元的基的灵敏度sensitivities(灵敏度的意思就是我们 的基b变化多少,误差会变化多少,也就是误差对基的变化率,也就是导数了),定义如下: (第二 个等号是根据求导的链式法则得到的) 0E_OEdu dbduOb 因为? u/? b=1,所以? E/? b=? E/? u=,也就是说bias基的灵敏度? E/? b=S和误差E对一个节点全部输入u的导数? E/? u是相等的。 这个导数就是让高层误差反向传播到底层的神来之笔。 反向传播就 是用下面这条关系式: (下面这条式子表达的就是第I层的灵敏度,就是) M二(lL+1卩於+1。 口j) 公式 (1) 这里的“表示每个元素相乘。 输出层的神经元的灵敏度是不一样的: H^f(uL)o(yn-tnV 最后,对每个神经元运用delta(即S)规则进行权值更新。 具体来说就是,对一个给定的神经元,得到它的输入,然后用这个神经元的delta(即S)来进行缩放。 用向量的形式表述就是,对于 第I层,误差对于该层每一个权值(组合为矩阵)的导数是该层的输入(等于上一层的输出)与该层的灵敏度(该层每个神经元的3组合成一个向量的形式)的叉乘。 然后得到的偏导数乘以一个负 学习率就是该层的神经元的权值的更新了: 9E cwf ="(旳T △w‘ OE _一"讥,“ 公式 (2) 对于bias基的更新表达式差不多。 实际上,对于每一个权值(W)ij都有一个特定的学习率n。 3.2卷积神经网络 上一层的特征maps被一个可学习的卷map。 每一个输出map可能是组合卷 3.2.1、ConvolutionLayers卷积层 我们现在关注网络中卷积层的BP更新。 在一个卷积层, 积核进行卷积,然后通过一个激活函数,就可以得到输出特征积多个输入maps的值: 这里Mj表示选择的输入maps的集合,那么到底选择哪些输入maps呢? 有选择一对的或者三 个的。 但下面我们会讨论如何去自动选择需要组合的特征maps。 每一个输出map会给一个额外的偏 置b,但是对于一个特定的输出map,卷积每个输入maps的卷积核是不一样的。 也就是说,如果输 出特征mapj和输出特征mapk都是从输入mapi中卷积求和得到,那么对应的卷积核是不一样的。 ComputingtheGradients梯度计算 我们假定每个卷积层I都会接一个下采样层1+1。 对于BP来说,根据上文我们知道,要想求得层I的每个神经元对应的权值的权值更新,就需要先求层I的每一个神经节点的灵敏度3(也就是权 值更新的公式 (2))。 为了求这个灵敏度我们就需要先对下一层的节点(连接到当前层I的感兴趣节 点的第I+1层的节点)的灵敏度求和(得到3+1),然后乘以这些连接对应的权值(连接第I层感兴 趣节点和第1+1层节点的权值)W。 再乘以当前层I的该神经元节点的输入u的激活函数f的导数值(也就是那个灵敏度反向传播的公式 (1)的3的求解),这样就可以得到当前层I每个神经节点对 应的灵敏度3了。 然而,因为下采样的存在,采样层的一个像素(神经元节点)对应的灵敏度3对应于卷积层(上 一层)的输出map的一块像素(采样窗口大小)。 因此,层I中的一个map的每个节点只与1+1层中 相应map的一个节点连接。 为了有效计算层I的灵敏度,我们需要上采样upsample这个下采样downsample层对应的灵敏度map(特征map中每个像素对应一个灵敏度,所以也组成一个map),这样才使得这个灵敏度map 大小与卷积层的map大小一致,然后再将层I的map的激活值的偏导数与从第1+1层的上采样得到的灵敏度map逐元素相乘(也就是公式 (1))。 在下采样层map的权值都取一个相同值3,而且是一个常数。 所以我们只需要将上一个步骤得到的结果乘以一个3就可以完成第I层灵敏度3的计算。 我们可以对卷积层中每一个特征mapj重复相同的计算过程。 但很明显需要匹配相应的子采样层的map(参考公式 (1)): 仍=禹+1(/(讷)。 叩©+1)| up(.)表示一个上采样操作。 如果下采样的采样因子是n的话,它简单的将每个像素水平和垂直 方向上拷贝n次。 这样就可以恢复原来的大小了。 实际上,这个函数可以用Kronecker乘积来实现: up(x)=X®lnxn. 好,到这里,对于一个给定的map,我们就可以计算得到其灵敏度map了。 然后我们就可以通 过简单的对层I中的灵敏度map中所有节点进行求和快速的计算bias基的梯度了: uv 公式(3) 最后,对卷积核的权值的梯度就可以用BP算法来计算了(公式 (2))。 另外,很多连接的权值 是共享的,因此,对于一个给定的权值,我们需要对所有与该权值有联系(权值共享的连接)的连接对该点求梯度,然后对这些梯度进行求和,就像上面对bias基的梯度计算一样: dE 这里, (P厂 中的在卷积的时候与 的(u,v)位置的值是由上一层的(u,v)位置的patch与卷积核 "j逐元素相乘的patch,输出卷积mapk_ij逐元素相乘的结果。 咋一看,好像我们需要煞费苦心地记住输出map(和对应的灵敏度map)每个像素对应于输入 map的哪个patch。 但实际上,在Matlab中,可以通过一个代码就实现。 对于上面的公式,可以用Matlab的卷积函数来实现: 9E =rot180(conv2(x--1. rot180(\ali(r)) 我们先对delta灵敏度map进行旋转,这样就可以进行互相关计算,而不是卷积(在卷积的数学 定义中,特征矩阵(卷积核)在传递给conv2时需要先翻转(flipped)一下。 也就是颠倒下特征矩 阵的行和列)。 然后把输出反旋转回来,这样我们在前向传播进行卷积的时候,卷积核才是我们想要的方向。 3.2.2、Sub-samplingLayers子采样层 对于子采样层来说,有N个输入maps,就有N个输出maps,只是每个输出map都变小了。 Xj=f(3;dowufx^-1}+b;) down(.)表示一个下采样函数。 典型的操作一般是对输入图像的不同nxn的块的所有像素进行求 和。 这样输出图像在两个维度上都缩小了n倍。 每个输出map都对应一个属于自己的乘性偏置B和 一个加性偏置b。 ComputingtheGradients梯度计算 这里最困难的是计算灵敏度map。 一旦我们得到这个了,那我们唯一需要更新的偏置参数B和 b就可以轻而易举了(公式(3))。 如果下一个卷积层与这个子采样层是全连接的,那么就可以通过BP来计算子采样层的灵敏度maps。 我们需要计算卷积核的梯度,所以我们必须找到输入map中哪个patch对应输出map的哪个像 素。 这里,就是必须找到当前层的灵敏度map中哪个patch对应与下一层的灵敏度map的给定像素,这样才可以利用公式 (1)那样的3递推,也就是灵敏度反向传播回来。 另外,需要乘以输入patch 与输出像素之间连接的权值,这个权值实际上就是卷积核的权值(已旋转的)。 d;=oconv2(6j+1,rotl80(kj+1), 在这之前,我们需要先将核旋转一下,让卷积函数可以实施互相关计算。 另外,我们需要对卷积边界进行处理,但在Matlab里面,就比较容易处理。 Matlab中全卷积会对缺少的输入像素补0。 到这里,我们就可以对b和B计算梯度了。 首先,加性基b的计算和上面卷积层的一样,对灵 敏度map中所有元素加起来就可以了: S-=口%• 而对于乘性偏置3,因为涉及到了在前向传播过程中下采样map的计算,所以我们最好在前向 的过程中保存好这些maps,这样在反向的计算中就不用重新计算了。 我们定义: d;=down(xj_1). 这样,对3的梯度就可以用下面的方式计算: 9E °3j =£(硝砂 3.2.3、LearningCombinationsofFeatureMaps学习特征map的组合 大部分时候,通过卷积多个输入maps,然后再对这些卷积值求和得到一个输出map,这样的效 果往往是比较好的。 在一些文献中,一般是人工选择哪些输入maps去组合得到一个输出map。 但我们这里尝试去让CNN在训练的过程中学习这些组合,也就是让网络自己学习挑选哪些输入maps来 计算得到输出map才是最好的。 我们用aj表示在得到第j个输出map的其中第i个输入map的权 值或者贡献。 这样,第j个输出map可以表示为: 需要满足约束: ctij=1,and0 这些对变量ai的约束可以通过将变量ai表示为一个组无约束的隐含权值cij的softmax函数来 加强。 (因为softmax的因变量是自变量的指数函数,他们的变化率会不同)。 =网(切)叮一52fcexP(c*>) 因为对于一个固定的j来说,每组权值Cij都是和其他组的权值独立的,所以为了方面描述,我 们把下标j去掉,只考虑一个map的更新,其他map的更新是一样的过程,只是map的索引j不同 而已。 Softmax函数的导数表示为: 飞—=加g一gg 这里的3是Kroneckerdelta。 对于误差对于第I层变量a的导数为: dEdOLi u.v 最后就可以通过链式规则去求得代价函数关于权值Ci的偏导数了: dE ()a ()E 2灵瓦


- 配套讲稿:
如PPT文件的首页显示word图标,表示该PPT已包含配套word讲稿。双击word图标可打开word文档。
- 特殊限制:
部分文档作品中含有的国旗、国徽等图片,仅作为作品整体效果示例展示,禁止商用。设计者仅对作品中独创性部分享有著作权。
- 关 键 词:
- 卷积 神经网络 ConvolutionalNeuralNetworksCNN 摘要
 冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 铝散热器项目年度预算报告.docx
铝散热器项目年度预算报告.docx
-
牛津上海版通用小学英语三年级上册Unit 12同步练习2II 卷.docx
-
论我国私营企业员工激励机制.docx
-
人教版五年级品德与社会上册全册教案.docx
-
开学啦国旗下讲话稿三分钟.docx
-
露天采矿学复习题.docx
-
六年级英语教师年度考核个人总结.docx
-
某路站综合体项PC吊装施工方案.docx
-
人教版九年级历史上册期末考试试题一套.docx
-
隆昌妇幼保健院.docx
-
芦二矿抽采达标中长期规划.docx
-
看拼音写词语.docx
-
模拟磁盘调度算法系统的设计毕业设计.docx
-
每周一条名言警句或一首诗词.docx
-
棉花膜下滴灌示范工程设计总结报告.docx
-
九年级化学教案第十单元酸和碱教案新人教版.docx
-
宁波市水资源公报.docx
-
农业实用技术培训工作意见与农业局上半年工作总结范例两篇汇编.docx
-
平行线的判定.docx
-
内部会计管理制度11成本核算制度.docx
-
盘扣式脚手架支撑方案.docx
-
旅游规划模板.docx
-
煤矿大本大专毕业设计大采高综采工作面作业规程.docx
-
美学选择题整理课件资料.docx
-
名家论腹泻慢性肠炎.docx
-
宁夏银川市第一中学学年高一上学期期中考试地理试题解析解析版.docx
-
年产吨精密纤维纸项目建设建议书.docx
-
农技推广中心工作总结.docx
-
彭宇案的法逻辑批判.docx
-
宁夏仕奇房产网发布份房地产交易情况.docx
-
项目推荐书智能温控节能系统.docx
-
区县节日期间加强消防安全讲话稿与区发改委领导班子述职述廉报告汇编.docx
-
滴滴打车融资投资发展史.docx
-
工程垫资协议书范本.docx
-
二年级奥数周周练第20周简单推理一教师版答案.docx
-
17秋学期《商法尔雅》在线作业1.docx
-
法律逻辑学课程重点与教学要求参照模板.docx
-
区文化创意产业发展经验汇报材料.docx
-
初级会计职称考试必须掌握的100个知识点.docx
-
思念水饺品牌分级的个案研究.docx
-
小学教师个人成长心得精选多篇.docx
-
二级建造师学习资料.docx
-
人教版五年级语文下册课内阅读和课外阅读及答案汇编.docx
-
学年湖南省株洲市醴陵二中醴陵四中高二下学期期中联考政治试题 Word版.docx
-
四川省科技厅项目经费预算书模板.doc
 介绍电影PPT.ppt
介绍电影PPT.ppt
-
多种多样的购物场所文档.docx
-
小学三年级书法教案1.docx
-
教师社团活动方案.doc
-
法治企业建设知识竞赛试题库.docx
-
小学三年级校硬笔书法下册教案1.docx
