 数据库小结.docx
数据库小结.docx
- 文档编号:5418931
- 上传时间:2022-12-16
- 格式:DOCX
- 页数:20
- 大小:89.63KB
数据库小结.docx
《数据库小结.docx》由会员分享,可在线阅读,更多相关《数据库小结.docx(20页珍藏版)》请在冰豆网上搜索。
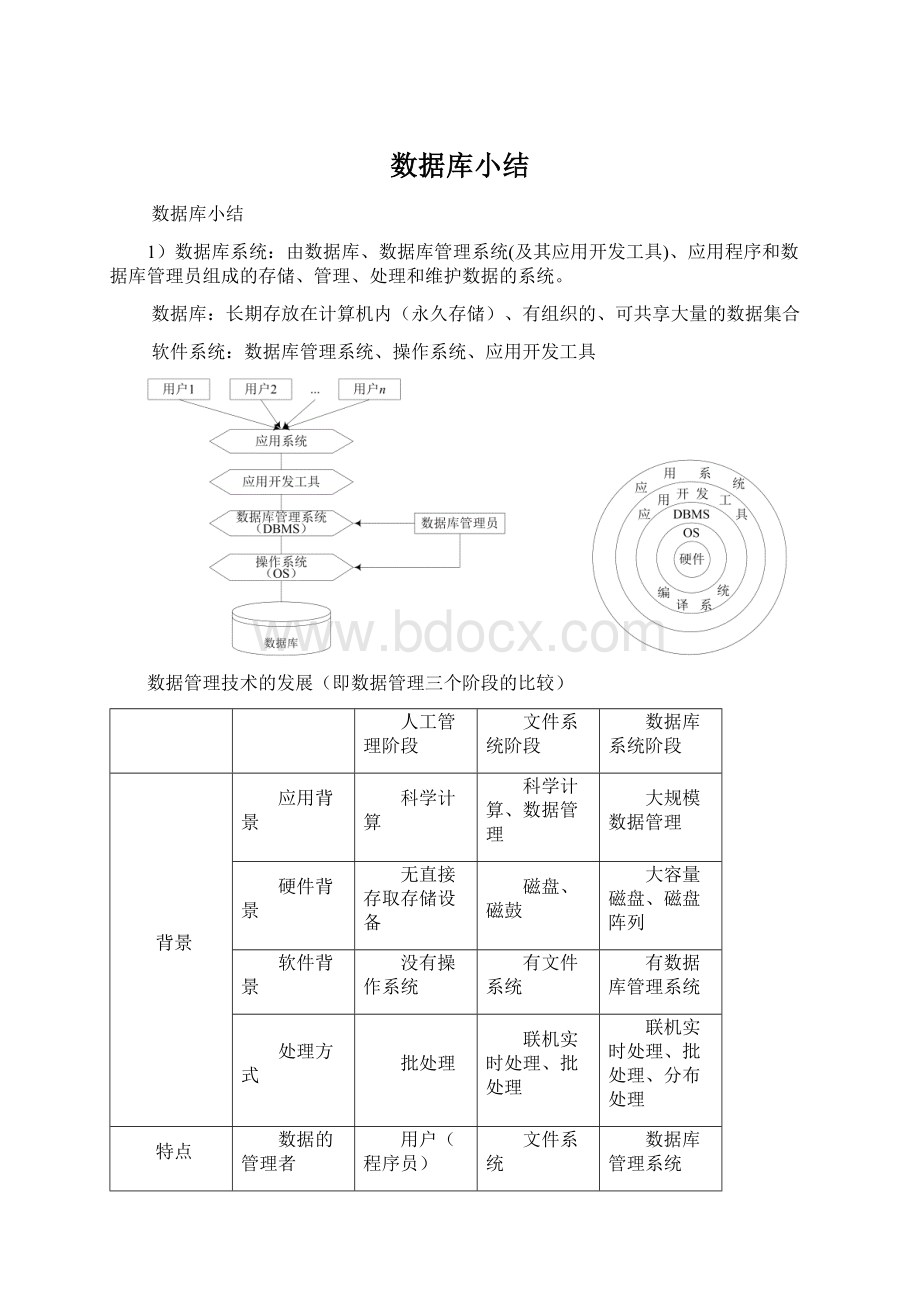
数据库小结
数据库小结
1)数据库系统:
由数据库、数据库管理系统(及其应用开发工具)、应用程序和数据库管理员组成的存储、管理、处理和维护数据的系统。
数据库:
长期存放在计算机内(永久存储)、有组织的、可共享大量的数据集合
软件系统:
数据库管理系统、操作系统、应用开发工具
数据管理技术的发展(即数据管理三个阶段的比较)
人工管理阶段
文件系统阶段
数据库系统阶段
背景
应用背景
科学计算
科学计算、数据管理
大规模数据管理
硬件背景
无直接存取存储设备
磁盘、磁鼓
大容量磁盘、磁盘阵列
软件背景
没有操作系统
有文件系统
有数据库管理系统
处理方式
批处理
联机实时处理、批处理
联机实时处理、批处理、分布处理
特点
数据的管理者
用户(程序员)
文件系统
数据库管理系统
数据面向的对象
某一应用程序
某一应用
现实世界(一个部门、企业、跨国组织等)
数据的共享程度
无共享,冗余度极大
共享性差、冗余度大
共享性高,冗余度小
数据的独立性
不独立,完全依赖于程序
独立性差
具有高度物理独立性和一定的逻辑独立性
数据的结构化
无结构
记录内有结构、整体无结构
整体结构化,用数据模型描述
数据控制能力
应用程序自己控制
应用程序自己控制
由数据库管理系统提供数据安全性、完整性、并发控制和恢复能力
4)数据模型:
对现实世界中数据特征的模拟和抽象,分为概念模型、逻辑模型及物理模型
数据结构、数据操作、数据完整性约束完整的描述了一个数据模型
概念模型:
按用户观点对数据和信息建模,用于数据库设计
逻辑模型:
按计算机系统的观点对数据建模,用于DBMS的实现(网状、层次、关系模型)
物理模型:
描述数据在系统内部的表示方式和存取方法
2)数据库管理系统:
数据库的核心,帮助用户创建和管理数据库的程序集合。
功能:
数据定义(DDL),数据组织、存储和管理,数据操纵(DML),数据库的运行管理,数据库的建立和维护功能,数据通信与转换。
类型:
总是基于某种数据模型,层次、网状、关系
层次模型、网状模型:
传统数据模型,是文件系统中所用数据模型的继承和发展。
1、层次模型:
只有根节点没有双亲结点
优点:
数据模型简单,提供了良好的完整性支持;
缺点:
现实世界很多联系都是非层次性的;对插入和删除限制比较多;查询子女结点必须通过双亲结点。
2、网状模型:
允许一个以上的结点无双亲,一个结点可以有多于一个的双亲。
优点:
更为直接的描述现实世界;良好的性能,存取效率高;
缺点:
结构复杂,不利于用户掌握;其DDL、DML语言复杂,增加了程序员负担。
3、关系模型:
建立在严格的数学基础上。
关系:
一个关系对应通常所说的一张表(笛卡尔积有意义的子集)
元组:
表中的一行(表示一个现实世界具体的事物)
属性:
表中的一列
主码:
可以唯一确定一个元组的属性组
域:
属性的取值范围
分量:
元组中的一个属性值
关系模式:
对关系的描述;表示:
关系名(属性1,属性2,….属性n)
优点:
建立在严格的数学概念基础上;概念简单,数据结构简洁清晰,用户易学;存取路径对用户透明(不可见)
3)数据库结构分为外模式、模式、内模式三级
外模式:
面向用户或应用程序员的用户级(数据库有多个外模式,数据局部逻辑结构)
模式:
面向建立和维护数据库人员的概念级(数据库只有一个模式,数据全局逻辑结构)
内模式:
数据在数据库内部的组织方式,(一个数据库只有一个内模式,数据存储结构)
5)实体:
是具体的人、事、物,也可以是抽象的概念或者联系。
属性:
可以是一个实体,也可以是单纯的属性
码:
也叫键,是唯一标识实体的属性集
域:
属性的取值范围
联系:
分为实体内部联系和实体间联系
实体内部联系:
组成实体的各属性间的联系。
实体间联系:
不同实体集之间的联系(一对一,一对多,多对多)
ER图:
描述实体间的联系以及单个实体内的联系
6)关系数据库:
以关系模型为基础构造的数据库系统,包括关系数据结构,关系操作集合,关系完整性约束。
候选码(键):
能唯一表示一个元组的属性组
主属性:
候选码中的一个属性
主键:
选定候选键之一作为主键
全码:
关系模式的所有属性是这个关系的候选码
基本表:
实际存储的表,是实际存储的逻辑表示
查询表:
查询结果对应的表
视图表:
由基本表或其他视图到处的表(虚表)
7)关系操作:
集合的操作方式
查询操作:
选择、投影、连接、除、并、交、差;
更新操作:
增加、删除、修改
8)完整性约束:
数据库的完整性是为了防止数据库中存在不符合语义的数据
关系完整性规则:
实体完整性,参照完整性,用户自定义完整性
实体完整性:
若属性A是基本关系R的主属性,则A不能取空值(不知道或不存在的值)
参照完整性:
若属性F是关系R的外码(与关系S的主码K对应),则r中f的值必须为空值或者s中某个元组对应主码值。
用户定义完整性:
具体应用环境需要的一些特殊的约束条件。
如check约束,default约束
9)关系代数的运算符:
运算符名称
符号
含义
运算符名称
符号
含义
集合运算符
∪
并
比较运算符
﹥
大于
﹣
差
≥
大于等于
∩
交
﹤
小于
×
笛卡尔积
≤
小于等于
专门的关系运算符
σ
选择
=
等于
π
投影
≠
不等于
⋈
连接
逻辑运算符
非
÷
除
与
或
象集:
给定一个关系R(X,Z),X和Z为属性组。
当t[X]=x时,x在R中的象集为Z={t[Z]|t∈R,t[X]=x}
结果:
它表示R中属性组X上值为x的诸元组在Z上分量的集合。
实际上象集是在属性组X上取值为x的诸元组在属性组Z上的取值的集合。
例子:
查询中华书局出版的大于30元的书籍Publisher=‘中华书局’Price>30(Book)
查询全体读者姓名等信息Name,Type,Department(Patron)
查询book表中有哪些出版社:
Publisher(Book)或4(Book)
连接举例:
连接s表和R表中b>c的列
10)关系数据库语言:
SQL
1、SQL:
综合统一;高度非过程化;面向集合的操作方式;灵活的使用方式;语言简洁,易学易用;
Sql功能
动词
数据查询
Select
数据定义
Create,drop,alter
数据操作
Insert,update,delete
数据控制
Grant,revoke
基本表(table):
本身独立存在的表,一个或几个基本表对应一个存储文件,所有的存储文件和索引文件构成了关系数据库的内模式
视图(View):
视图是从一个或几个表导出的表,是虚表,对应的数据不独立存在数据库中
数据定义语言:
用来创建、修改或删除数据库中的各种对象(表、视图、索引)
操作对象
创建
修改
删除
表
Createtable
alter
droptable
视图
Createview
dropview
索引
createindex
dropindex
查询语言:
按照指定的组合、条件表达式或排序来检索已存在数据库中的数据,不改变数据
语句:
select…from….Where
数据操纵语言:
对已存在的数据库进行记录的插入、删除、修改等操作
语句:
Insert、update、delete;
数据控制语言:
授予或收回数据库的某种权限;控制数据库操纵事务发生的时间及效果
语句:
grant,revoke,commit,rollback;
11)数据定义
建立数据库:
createdatabase数据库名如:
createdatabasestudent;
建立数据库基本表:
createtable表名(列名数据类型列级完整性约束条件,….表级完整性约束条件);
列级约束:
包含在列的定义中,对该列进行约束;表级约束:
表的最后一列定义之后,对整个表进行约束;有些约束既可以是列级约束也可以是表级约束。
空值:
是当前不知道、不确定或无法填入的值;空值不能理解为0或为空白符;
举例如下:
CREATETABLEBook(
CallNoCHAR(20)CONSTRAINTPK_CallNoPRIMARYKEY,
TitleVARCHAR(50)CONSTRAINTNL_TitleNOTNULL,
AuthorCHAR(10),
PublisherCHAR(20),
ISBNCHAR(17)CONSTRAINTUE_ISBNUNIQUE,
PubDateSMALLDATE,
PagesINT,
PriceNUMERIC(10,2),
NumberINT,
AvailableNumberINT,
CONSTRAINTCK_NumberCHECK(AvailableNumber<=Number))
索引:
是数据库联机检索的常用手段,用于改善查询性能
问题:
索引要占用磁盘空间,降低delete、update、insert操作的速度,速度不一定比表扫描的速度快
使用索引的情况:
大表,经常对表查询,不经常更新表,列的取值个数较多
12)数据查询:
字符匹配:
_匹配任意单个字符,%匹配任意长度(包括0)的字符串,[]匹配[]中的任意单字符,[^]不匹配[]中的任意一个字符。
聚集函数:
对数据进行汇总和统计
聚集函数及格式
格式
COUNT([DISTINCT|ALL]*)
统计元组个数
COUNT([DISTINCT|ALL]<列名>)
统计一列中值的个数
SUM([DISTINCT|ALL]<列名>)
计算一列值的总和(该列必须是数值型)
AVG([DISTINCT|ALL]<列名>)
计算一列值的平均值(该列必须是数值型)
MAX([DISTINCT|ALL]<列名>)
求一列值中的最大值
MIN([DISTINCT|ALL]<列名>)
求一列值中的最小值
13)查询例子:
起别名及对取出的值进行计算
SELECTName姓名,YEAR(GETDATE())-YEAR(BirthDate)年龄,'周岁'备注FROMPatron;
查询姓名和年龄:
SELECTName,YEAR(GETDATE())-YEAR(BirthDate)FROMPatron;
消除重复行(distinct关键字):
SELECTDISTINCTPatronIDFROMLend
Where子句中通常使用的条件如下:
查询条件
运算符
比较大小
=、>、>=、<=、<、<>、!
=、!
>、!
<;NOT+上述比较运算符
确定范围
BETWEEN…AND…、NOTBETWEEN…AND…
确定集合
IN、NOTIN
字符匹配
LIKE、NOTLIKE
空值
ISNULL、ISNOTNULL
多重条件(逻辑运算符)
AND、OR
比较大小:
SELECTNameFROMPatronWHEREDepartment='电信学院';
范围:
SELECTCallNo,Title,Publisher,PagesFROMBookWHEREPagesBETWEEN300AND400;
确定集合SELECTName,GenderFROMPatronWHEREDepartmentIN('电信学院','工商学院');
字符匹配SELECT*FROMPatronWHERENameLIKE'赵%';
带转义字符(escape关键字声明):
SELECT*FROMBookWHERETitleLIKE'SQL\_%'ESCAPE'\';
空值查询SELECTDISTINCTPatronIDFROMLendWHEREReturnTimeISNULL;
多重条件SELECTName,BirthDate,DepartmentFROMPatronWHEREBirthDate<'1990-1-1'ANDType='学生';
带有orderby(asc升序,desc降序)
SELECTCallNo,Title,Author,Publisher,PubDate,Price,NumberFROMBookORDERBYPriceDESC;
使用聚集函数:
SELECTMAX(Price)最高单价FROMBookWHEREPubDate=2009
使用groupby:
SELECTPatronID读者证号,AVG(DATEDIFF(DAY,LendTime,ReturnTime))天数
FROMLendGROUPBYPatronIDHAVINGAVG(DATEDIFF(DAY,LendTime,ReturnTime))>20;
交叉连接:
SELECTPatron.*,Lend.*FROMPatron,LendWHEREPatron.PatronID=Lend.PatronID
外连接:
SELECTPatron.PatronID,Name,LendTimeFROMPatron
JOINLendONPatron.PatronID=Lend.PatronIDJOINBookONLend.CallNo=Book.CallNo
WHERETitle='谋生记';
嵌套查询:
SELECTP1.PatronID,P1.Name,P1.Gender,P1.BirthDateFROMPatronP1JOINPatronP2ONP1.Department=P2.DepartmentWHEREP2.Name='韩冬';
SELECTPublisher,TitleFROMBookBookXWHEREPrice>(SELECTAVG(Price)FROMBookBookY
WHEREBookY.Publisher=BookX.Publisher);
带有any(任何一个)或all(全部)(满足大于子查询结果中的最小值,大于子查询结果中最大值)
SELECTTitle,PublisherFROMBookWHEREPrice>ALL(SELECTPriceFROMBook
WHEREPublisher='中华书局');
带有exists关键字:
SELECTDISTINCTName,DepartmentFROMPatron
WHEREEXISTS(SELECT*FROMLendWHERELend.PatronID=Patron.PatronID
ANDReturnTimeISNULL);
14)集合查询:
如果多个select语句得到的结果具有相同的列数,并且对应列的数据类型相同,就可以用集合操作对这些结果进行处理,有并(union),交(intersect),差(except)
例如:
SELECT*FROMPatronWHEREDepartment='电信学院'
INTERSECTSELECT*FROMPatronWHEREBirthDate<'1990-1-1';
15)数据更新:
insert(数据插入),update(修改),delete(删除)
插入数据例子:
INSERTINTOPatron(PatronID,Name,Gender,Department,BirthDate,Type)
VALUES('S0120080201','王东','男','电信学院','1990-9-5','学生');
Update例子:
UPDATEPatronSETDepartment='管理学院‘WHEREDepartment='工商学院';
Delete例子:
DELETEFROMLendWHERELendTime<'2009-5-1';
16)视图:
从基本表或视图导出的表,数据最终源于基本表;视图对应于外模式;
视图和基本表一样都可以进行查询、插入、修改和删除等操作(对视图的更新有一定的限制)
优点:
简化用户操作;使用户能够从不同角度看待同一数据;提供一定程度的逻辑独立性;有助于对数据提供安全保护;
17)T-SQL:
变量:
1、局部变量:
用户自定义变量,作用范围仅限定义他的程序内部。
局部变量名以@开头。
定义变量语法格式为DECLARE@变量名变量类型[,@变量名变量类型]
使用select或set设置变量的值:
SELECT@变量名=变量值或者SET@变量名=变量值
2、全局变量:
不是用户定义的,是在服务器级定义的系统内部使用的变量,任何程序均可以随时使用。
引用全局变量需以@@开头
输出:
print语句可直接显示表达式结果
函数:
一组编译好的T-SQL语句,SQLserver支持内置函数和用户定义函数两种类型
1、内置函数:
一组预定义函数,t-sql的一部分,用户可直接使用实现功能
2、用户定义函数:
由用户编写,用户根据需要编写和修改自定义函数,然后调用
Sqlserver函数分为七类:
数学函数、字符串函数、日期时间函数、聚集函数、转换函数、系统函数、用户自定义函数
批:
从客户端传递给服务器的一组完整的数据和sql指令的集合,从应用程序一次性的发送到sqlserver执行。
go:
批处理的标志,两个‘go’之间的T-SQL语句称为一个批处理
举例如下:
DECLARE@MyVarvarchar(50)--该变量声明仅在该"批"中有效。
SELECT@MyVar='今天天气真不错!
'
PRINT'第一个批处理执行结束'
GO
PRINT@MyVar--将产生错误,因为@MyVar在该"批"中未经定义而直接使用。
PRINT'第二个批处理执行结束'
GO
PRINT'第三个批处理执行结束'
GO
流程控制:
通过判断指定的某些值来控制程序运行方向的语句,begin…end;if….else;case;while;goto;waitfor;
Case计算多个条件样式,并将其中一个符合条件的结果表达式返回。
只能嵌套在select语句的select子句中
两种用法举例如下:
Waitfor:
用来暂停程序,直到所设定的等待时间已过或所设定时间已到才继续执行
USETSG
GO
WAITFORDELAY'00:
00:
30'
DELETEFROMBook
WHERECallNo='12345'
18)过程:
独立存放且拥有不同功能的语句集合
存储过程:
是一组为了完成特定功能的sql语句的集合、它经编译后存储在数据库中,用户通过指定的调用方法执行。
存储过程具有名称,参数及返回值,并且可以嵌套调用
存储过程分类:
系统存储过程、扩展存储过程、用户自定义存储过程
存储过程优点:
允许标准组件式编程;能够实现较快的执行速度;减少网络流量;可被作为一种安全机制来充分利用
与函数区别:
执行效率高;可返回多个输出变量;单独执行,函数可嵌入表达式;对逻辑处理的应用,函数完成特定功能。
19)系统存储过程:
存储在master中,以sp_开头;创建数据库时,一些系统存储过程会在新库中被自动创建;
功能:
从系统表获取(某个数据库对象的)信息;可以直接使用
扩展存储过程:
系统提供的,由外部语言编写的存储过程;弥补sqlserver功能不足,扩展功能;名称以xp开头
创建存储过程:
CREATEPROC[EDURE]procedure_name[{@parameterdata_type}[=default]
[OUTPUT][READONLY][,…n]][WITH[ENCRYPTION[,…n]]
AS{
执行存储过程:
execute语句执行
修改存储过程:
alterprocedure语句
ALTERPROCEDUREusp_Lend_Info
AS
SELECTL.PatronID,P.Name,B.Title,L.LendTime
FROMLendASLJOIN
BookASBONB.CallNo=L.CallNo
ANDL.ReturntimeISNULL
JOINPatronASPONL.PatronID=P.PatronID
删除存储过程:
dropprocedure
存储过程的参数:
输入参数,通过输入参数可将数据传送到存储过程中(定义变量名、类型,还可以设置默认值)
输出参数:
将数据或游标变量传回给调用程序,使用output关键字声明
参数传递:
按位置传递,安参数名字传递。
例子如下:
1、创建存储过程:
CREATEPROCEDUREusp_Query_LendHistByPatronID
@PatronIDVARCHAR(20)
AS
BEGIN
SETNOCOUNTON;
SELECT*FROMLendWHEREPatronID=@PatronID
END
执行存储过程:
常量调用:
EXECusp_Query_LendHistByPatronID‘T0101’
变量调用:
DECLARE@InputPatronIDVARCHAR(20)
SELECT@InputPatronID='T0101'
EXECusp_Query_LendHistByPatronID@InputPatronID
2、多变量的存储过程
创建过程:
CREATEPROCEDUREusp_Get_Patron_Info
@PatronIDVARCHAR(20),
@NameVARCHAR(30)OUTPUT,
@DepartmentVARCHAR(40)OUTPUT,
@TypeVARCHAR(20)OUTPUT
AS
SELECT@Name=Name,@Department=department,@Type=Type
FROMPatronWHEREPatronID=@PatronID
调用过程:
DECLARE@NameVARCHAR(30)
DECLARE@DepartmentVARCHAR(40)
DECLARE@TypeVARCHAR(20)
EXECUTEusp_Get_Patron_Info'T0101',@NameOUTPUT,
@DepartmentOUTPUT,@TypeOUTPUT
SELECT@Name,@Department,@Type--显示执行结果
存储过程返回值:
使用return语句指定存储过程的返回代码,
20)触发器:
一种特殊的存储过程;在指定的数据表中进行插入、修改以及删除操作时,会自动执行对应的触发器代码;为数据库提供了有效的监控和处理机制,确保数据和业务的完整性。
优点:
强化了约束的功能;


- 配套讲稿:
如PPT文件的首页显示word图标,表示该PPT已包含配套word讲稿。双击word图标可打开word文档。
- 特殊限制:
部分文档作品中含有的国旗、国徽等图片,仅作为作品整体效果示例展示,禁止商用。设计者仅对作品中独创性部分享有著作权。
- 关 键 词:
- 数据库 小结
 冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 转基因粮食的危害资料摘编Word下载.docx
转基因粮食的危害资料摘编Word下载.docx
-
高中英语词组大全Word文档下载推荐.docx
-
卫计局年工作总结及新年工作计划Word格式.docx
-
贵州省煤矿安全管理人员安全资格证A考试概况Word格式.docx
-
系统集成项目招标文件Word文件下载.docx
-
电子商务考试题总汇打印版打印打印Word下载.docx
-
选调生考试备考言语理解与表达真题Word文档格式.docx
-
高考物理实验题专练 专练15Word文档格式.docx
-
加装奥迪A4L蓝牙电话功能Word文档下载推荐.docx
-
学年下学期好教育高三月考仿真卷A卷 语文 学生版后附详解Word文档下载推荐.docx
-
净化生产车间工程一般施工技术施工方案Word文档格式.docx
-
内蒙古呼和浩特市第六中学学年高一政治下学期期末考试试题Word下载.docx
-
证券行业客户经理电话营销技巧与实例Word文档下载推荐.docx
-
叶芝 苇间风文档格式.docx
-
最新中美贸易摩擦的原因及解决对策1论文Word文件下载.docx
-
意义的近义词Word格式文档下载.docx
-
上海市中考英语试题S.docx
-
专题12观点论证类设问.docx
-
附加安心重疾条款.docx
-
设计变更管理办法修改意见稿FINAL汇编.docx
-
毕业赠言毕业致词精选多篇.docx
-
银行新员工代表发言稿精选多篇.docx
-
北京市朝阳区届高三第一学期期末语文试题Word版含答案.docx
-
HL线切割使用说明书模板.docx
-
车工实训周记.docx
-
USBHID键盘扫描码.docx
-
Apmpoqu4调研报告.docx
-
最熟悉的陌生人作文八篇.docx
-
被动语态综合讲解.docx
-
部编版语文七上第五单元16猫同步练习试题.docx
-
软件体系结构作业2.docx
-
钢管管道安装焊接施工工艺.docx
-
教科版小学二年级语文上册复习 字词Word格式.docx
-
20xx年高中教师专业发展规划书通用范本Word文档格式.docx
-
参观养殖场心得体会Word文档格式.docx
-
ktv工作总结12篇Word格式文档下载.docx
-
教育系统工作总结范文Word下载.docx
-
中国文化概论课后题答案Word格式文档下载.docx
-
Personenbeschreibung德语人物描写汇总Word格式.docx
-
35KV架线专项施工方案Word格式.docx
-
中考物理第01期考点总动员系列 专题04 熔化与凝固Word格式.docx
-
XX园区休闲娱乐式游泳馆工程建设项目可行性研究报告Word文档下载推荐.docx
-
成长无忧少儿重大疾病保险文档格式.docx
-
Maxquant使用说明Word下载.docx
-
中秋节经典短信贺卡祝福100句中秋节最新祝福语大全Word下载.docx
-
初级经济师《建筑经济》试题及答案卷二Word文档下载推荐.docx
-
挑战杯创业计划作品申报书Word文件下载.docx
-
江苏省公务员考试行测真题及答案解析C类Word文档格式.docx
-
导购员销售技巧培训Word文档下载推荐.docx
-
初中体育工作计划4篇Word文档格式.docx
-
主任述职报告Word文档格式.docx
