 硬件平台解决方案.docx
硬件平台解决方案.docx
- 文档编号:5313645
- 上传时间:2022-12-15
- 格式:DOCX
- 页数:78
- 大小:4.58MB
硬件平台解决方案.docx
《硬件平台解决方案.docx》由会员分享,可在线阅读,更多相关《硬件平台解决方案.docx(78页珍藏版)》请在冰豆网上搜索。
硬件平台解决方案
硬件平台解决方案
2014年2月
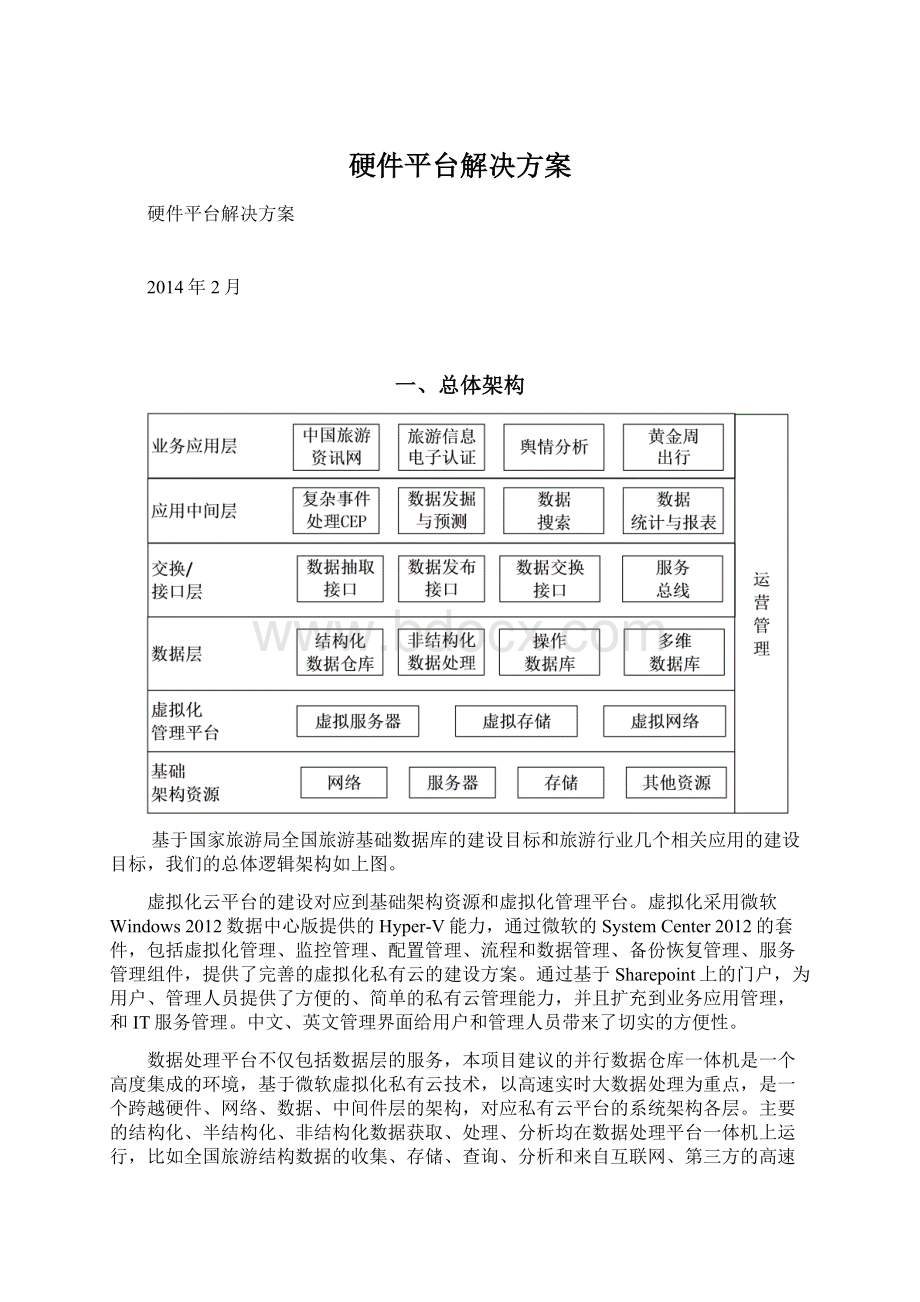
一、总体架构
基于国家旅游局全国旅游基础数据库的建设目标和旅游行业几个相关应用的建设目标,我们的总体逻辑架构如上图。
虚拟化云平台的建设对应到基础架构资源和虚拟化管理平台。
虚拟化采用微软Windows2012数据中心版提供的Hyper-V能力,通过微软的SystemCenter2012的套件,包括虚拟化管理、监控管理、配置管理、流程和数据管理、备份恢复管理、服务管理组件,提供了完善的虚拟化私有云的建设方案。
通过基于Sharepoint上的门户,为用户、管理人员提供了方便的、简单的私有云管理能力,并且扩充到业务应用管理,和IT服务管理。
中文、英文管理界面给用户和管理人员带来了切实的方便性。
数据处理平台不仅包括数据层的服务,本项目建议的并行数据仓库一体机是一个高度集成的环境,基于微软虚拟化私有云技术,以高速实时大数据处理为重点,是一个跨越硬件、网络、数据、中间件层的架构,对应私有云平台的系统架构各层。
主要的结构化、半结构化、非结构化数据获取、处理、分析均在数据处理平台一体机上运行,比如全国旅游结构数据的收集、存储、查询、分析和来自互联网、第三方的高速海量大数据,都通过并行数据仓库一体机平台进行处理。
对应的,具体业务应用和部分应用支撑数据库则运行在虚拟化私有云平台上,比如中国旅游资讯网、旅游信息电子认证等应用。
大数据管理设计
微软的愿景是让所有用户都能从几乎任何数据中获得业务洞察力,包括以前隐藏在非结构化数据中的洞察力。
为实现此愿景,微软制定了全面的大数据策略以解决以下关键的客户要求:
强大的数据管理层:
可支持所有数据类型,包括结构化、半结构化和非结构化的静态或动态数据。
丰富的数据处理层:
提供对数据分析的扩充,用于发现、转换、共享和监管数据。
提供令人瞩目的BI工具套件,可帮助用户通过分析获得洞察力。
深度的业务洞察层:
提供更深入的洞察力,将企业的数据和来自外部源的数据及服务相结合。
(以下图片展示了完整的大数据解决方案。
交换和接口层。
基于国家旅游基础数据库和非结构化数据的分析、挖掘和预测产生的数据内容需要被更多的业务应用程序调用。
交换和接口层负责数据平台和大量的业务应用间的数据交换,其中包括数据格式转换接口、流程驱动、流程监视、自动化任务执行等功能。
交换和接口层基于微软的Biztalk2013平台,这个产品是微软企业应用集成和企业服务总线的底层架构。
通过SOA动态的方式,将多种数据和技术糅合,有选择的把数据分类存放在不同性质的数据库或服务目录中,使其在上述的架构下发挥各自的作用,实现数据整合。
服务总线(以下简称ESB)作为数据交换的中枢,肩负着数据的传递、转换、路由、监控以及对多种通讯协议的支持等众多责任。
ESB采用了“总线”这样一种模式来管理和简化应用之间的集成拓扑结构,以广为接受的开放标准为基础来支持应用之间在消息、事件和服务的级别上动态的互连互通。
ESB最大的技术特点在于,可以架构在现有的网络框架、软硬件系统之上,构筑出一个全局的信息系统解决方案。
在ESB中,服务器犹如一个个汽车站,可以自由地连接和脱离ESB中间件,所有的信息系统都可以通过其发送或接受任务、指令,它适用于所有的现有或未来的信息应用平台。
ESB和数据交换平台的建设,要根据国家旅游局的数据获取策略和应用互联互通的发展节点决定具体策略。
二、技术架构
1.数据处理平台技术架构
通过对传统面向关系型数据分析为主的数据仓库架构的扩充,本方案的数据仓库平台不大大增强了对海量关系数据的管理和分析能力,还引入了基于Hadoop架构的非结构化数据分析能力,此外,对流式数据的分析也进行了有益的扩充,实现了全面的大数据处理和与业务实时互动的能力。
为帮助国家旅游局快速采用其基础数据库大数据解决方案,本方案提供了对Hadoop的无缝集成,用户可以选择市面上众多的Hadoop平台进行非结构化数据的管理;同时,提供基于本地的Hadoop版本,提供了支持企业级整合的能力,大大简化了以数据库和结构化数据为主要数据管理手段的传统用户引入Hadoop等新兴非结构化处理技术。
此外,也通过公有云平台上提供基于云端的Hadoop服务,为未来国家旅游局数据服务走向开放的公有云平台奠定统一的技术基础。
采用的Hadoop版本使得客户可以从几乎任何规模的结构化和非结构化数据中获得业务洞察力并应用新型数据而无需考虑其具体位置。
Hadoop的丰富洞察可以与BI平台无缝结合,使客户能够借助熟悉的工具(例如MicrosoftOffice和SharePoint等以及公用的数据和服务来丰富他们的模型。
本大数据解决方案还通过简单的部署以及与目录管理和系统管理中心等组件的集成,为Hadoop提供了易用性和可管理性。
凭借公有云上基于Hadoop的服务,为其大数据解决方案在云端提供了灵活性。
整合了数据仓库、大数据平台和云服务平台的总体技术架构包括:
大数据平台
大数据平台以Hadoop及其相关技术为核心,提供海量数据存储和数据挖掘分析能力。
通过集成系统中各来源的非结构化数据和半结构化数据,一方面将各级旅游单位非结构化信息进行统一管理,另一方面将互联网上相关信息加以融合。
大数据平台将结合其他各个业务系统,集成各种数据源后,搭建统一集中大数据处理和分析平台,从全方位,多角度为运营决策提供强有力的帮助。
该体系架构可以使用开源平台,帮助国家旅游局以低廉的代价获得世界上最先进的技术,以快速适应当前业务的快速变化。
大数据平台是总体数据处理平台的一个重要部分,通过对海量非结构化的数据进行处理和分析,一方面提供舆情、热点等数据挖掘,另一方面为数据仓库平台提供结构化数据导入,将纷繁复杂的各来源的非结构化数据进行整理和萃取,输入至数据仓库中,与原有结构化数据进行综合分析挖掘。
此外,对于数据仓库中的历史数据,亦可下沉到大数据平台中,通过数据仓库提供年度数据分析,同时对历史数据可以随时调用加载、查询、分析。
大数据平台主体结构如下图示,
具体到大数据平台,其技术架构主要由五个部分组成:
源数据层:
涵盖各种数据来源,首先是用户访问数据,包括互联网数据,各旅游单位数据,以及新兴的社交媒体数据等;
基础架构层:
由分布式文件存储(HDFS和HBASE)和分布式计算(MapReduce/Yarn)构成;
数据服务层:
由各种工具构成,完成对数据的处理和分析;
商业智能层:
对清洗整理后的数据,进行深度数据挖掘,并进行各种数据可视化,将各种数据以及关联从各个维度,序列直观地展示出来,供决策层分析
集群管理层:
管理集群,以及部署在上面的各种服务
支撑大数据平台的技术架构为Hadoop平台,Hadoop分布式文件系统(HDFS)是一个设计为用在普通硬件设备上的分布式文件系统。
它与现有的分布式文件系统有很多近似的地方,但又和这些文件系统有很明显的不同。
HDFS是高容错的,设计为部署在廉价硬件上的。
HDFS对应用程序的数据提供高吞吐量,而且适用于那些大数据集应用程序。
HDFS开放了一些POSIX的必须接口,容许流式访问文件系统的数据。
HDFS最初是为了Apache的Nutch网络搜索引擎项目的下层构件而设计的。
运行在HDFS上的应用程序使用大数据集。
HDFS一个典型的文件可能是几GB的或者几TB的。
因此,HDFS适用于大文件,并将小文件进行聚合后进行管理以提高效率。
这将提供高集成带宽,并在一几集群中提供上百个节点。
一个实例可能支持上千万个文件。
数据仓库平台
由于国家旅游局数据量庞大,在其上面进行的计算复杂度高,并应充分考虑到未来容量和计算性能的扩展能力。
并行数据仓库架构具备很强的可伸缩性,可以通过大规模并行计算(MassivelyParallelProcessing,MPP)架构,以很低的成本实现很高的性能,从而帮助国家旅游局构建企业级数据仓库的高端平台。
该平台的主要能力包括:
每TB平均成本低廉,且性能卓越
采用并行数据仓库具备很强的可伸缩性,这也是业内数据仓库发展的新方向。
并行数据仓库采用MPP架构,不但实现了高性能,而且还可以进一步扩展遵循行业标准的硬件的平台的处理能力。
MPP架构提供了更为卓越的可伸缩性,增强了性能的可预测性,降低了风险,并且与其它任何数据仓库解决方案相比,其每TB数据的平均成本是最为低廉的。
在传统的对称多线程处理(SymmetricMultiProcessing,SMP)架构当中,数据查询过程完全在一个物理实例当中进行,因此CPU、内存、以及存储都将限制查询速度以及可伸缩性。
而并行数据仓库采用MPP架构,可以对大型数据表进行分区,并将分区存储在多个物理节点当中,每一个节点均有其独占的CPU资源、内存资源、以及存储资源,并且各自运行独立的数据库实例,这种模型称之为UltraSharedNothing。
所有组件彼此间都是平衡的,从而消除了性能瓶颈,另外所有的服务器和存储均采用镜像方式,从而实现企业级的冗余。
控制节点(ControlNode)可以将查询从应用程序路由到所有的计算节点(ComputeNode),然后收集并返回查询结果。
由于数据最终分布在多个节点当中且查询采用并行方式完成,因此查询速度要比采用单一的SMP数据库服务器快很多倍。
采用这种架构的成本实际上也更为低廉,因为并行数据仓库无需依赖昂贵的专用处理器或存储,只要使用遵循行业标准的硬件设备即可。
随着数据量的不断增加,用户只需要添加额外的存储即可,而无需进行交叉式升级(forkliftupgrade,即升级全部设备)。
增强现有BI投资的回报率
并行数据仓库与现有BI工具紧密结合,可以帮助企业从现有的BI投资当中榨取更多的价值。
并行数据仓库MPP可以与现有BI套装当中的各个组件(包括集成服务、分析服务、以及报表服务)相结合,并且现有的SMP数据集市也可以作为一个节点,“插入”到MPP星型拓扑结构当中来接收数据。
从“应用模型”当中受益
数据仓库的部署和运维将变得更加简单。
并行数据仓库采用顶尖厂商所提供的预安装的软硬件设备,这种“应用模型”可以让企业更加快速的看到价值,并且极大地降低了部署成本。
提供可预测的性能
通过平衡式的配置、严谨的规格和测试,并行数据仓库MPP可以提供可预测的性能。
微软在设计时针对不同的使用场景均提供了相应配置,例如针对报表操作和即席查询。
自动化的工作负载管理以及系统资源平衡功能可以让用户在查询过程中并发加载数据且无需以牺牲性能为代价。
随着数据量的增长以及业务需求的变更,微软可以同时支持更多用户执行不同类型的查询。
通过星型拓扑架构实现更好的灵活性并优化业务整合
采用星型拓扑架构,企业的全部数据均可以通过并行数据仓库进行维护,同时各个部门以及业务单元依然可以保留数据集市以满足其各自需求。
高速数据传输大大缓解了传统星型拓扑结构所遇到的瓶颈。
高水平的用户甚至可以专门部署一个MPP作为节点,以便实现资源的独立管理,同时IT部门还可以强制所有数据满足企业标准。
其它收益
自动化的存储管理取代了复杂的空间分配机制。
诊断功能可以检测出硬件问题并通知管理员。
管理控制台通过统一的GUI界面和仪表盘来跟踪问题并解决问题。
快速的数据加载以及备份极大地简化了大型数据仓库的管理。
统一数据关口
由于结构化数据和非结构化数据的存储、访问、分析模式存在着较大的差异,传统的非结构化数据分析往往采用不同的数据处理、分析和展现手段,加大了系统的应用开发和后期维护的复杂度。
为此,本方案提出在结构化数据和非结构化数据间建立一个统一的数据关口,实现应用对数据仓库中结构化数据和Hadoop中非结构化数据的透明访问,并为应用提供基于SQL标准的统一接口,而不需花费大量的精力学习和实现基于MapRaduce及其他Hadoop组件的开发,大大降低了系统开发的复杂度;实现一个平台统一管理和访问两种不同类型的数据,降低了系统构建和运维的复杂度。
综合数据应用
作为全国性旅游信息资源管理应用平台,系统建成后,将实现:
1、旅游系统内部信息查询和共享
提升各种应用运行效率,满足旅游信息海量拾取、海量处理和海量存储的需求,为各级旅游管理机构提供全面的信息支撑
2、综合数据分析应用
通过搜索引擎、Web信息抽取、数据挖掘等技术,建立两到三个例如舆情分析、黄金周出行热点分析挖掘等综合数据分析应用
3、对外信息服务
为旅游企业、旅游在线运营商、游客提供权威的、全面的数据支撑,如:
1)中国旅游资讯网
2)实现旅游信息电子认证
复杂事件处理
数据流作为一种新的数据形态,不同于传统的静态数据,具有连续快速、短暂易逝和不可预测的特点,对其进行有效地分析和挖掘遇到了极大的挑战。
数据流分析的模型、数据流处理模型均和传统关系型数据分析的方法有着很大不同。
传统的数据库查询处理技术通常只适合处理存储在磁盘或内存等介质中的静态数据,难以直接应用到无限、连续、快速、“单遍扫描”的数据流中,因而,数据流应用对数据管理与分析提出了更高的要求。
如何从海量流数据中快速提取有价值的信息已成为数据库及相关应用领域面临的一个重大挑战。
微软提供StreamInsight解决方案提供包括数据流管理和数据流分析两个方面的技术能力,以拓展传统商业智能的应用范围。
结构化数据源
传统业务数据源系统采用关系型数据模型,这些系统承载着用户的核心业务系统。
随着时间的推移,这些系统上积累量大量的历史数据,这些历史数据通过ETL/ELT的手段整合到数据仓库中。
用户一般会依据自身行业的业务特点定义企业级数据模型,并将这些数据整合到同一的数据模型中,以满足于企业全局的数据服务需求。
为面向特定的分析专题,一般会对数据仓库中的数据进行不同粒度的汇总,行成为专题的数据集市,并通过多维分析服务(SQLServerAnalysisService)行成多维数据立方体以服务于OLAP分析,通过报表服务(SQLServerReportingService)行成各类分析报表和KPI支持。
这些服务于前端Office、Excel等分析工具结合,将KPI、固定报表、动态分析等能力呈现在最终用户面前;通过通过分析能力与业务流程的整合业务洞察力与流程,实现闭环的动态分析。
在ETL/ELT层面:
微软提供SQLServerIntegrationService(SSIS),DataQualityService(DQS),MasterDataService(MDS)等产品实现数据整合、数据质量管理和主数据管理的能力;
在数据仓库层面:
微软提供并行数据仓库ParallelDataWarehouse(PDW),以支持海量结构化数据的存储和复杂数据分析报表的能力。
基于并行数据仓库的技术,使微软PDW能达到数十倍甚至上百倍与传统数据库的性能,同时能管理上PB级的数据规模;
在专题分析层面:
微软提供了SQLServer以服务于传统关系型数据集市,SQLServerAnalysisService(SSAS)进行多维数据立方体的管理,及DataMining中集成的挖掘算法实现数据挖掘分析,发现数据中潜藏的规律、模式,实现深刻洞察力和预测。
并通过SQLServerReportingService(SSRS)提供报表和KPI的服务。
此外,通过与微软Office、SharePoint的整合,实现复杂商业智能分析和发布,及灵活的、面向全员的自助式商业智能分析。
非结构化数据源
据IDC的一项调查报告中指出:
企业中80%的数据都是非结构化数据,这些数据每年都按指数增长60%。
非结构化数据,顾名思义,是存储在文件系统的信息,而不是数据库。
据报道指出:
平均只有1%-5%的数据是结构化的数据。
过去,这些数据被直接丢弃或归档后很少过问;如何更好从这些非结构化的数据中去发现潜在的业务价值,也被日益被客户重视。
基于智能设备、传感器、网页爬虫等终端产生的非结构化数据被放到Hadoop环境中,通过Hadoop高效的分布式计算能力产生出有意义的结果;这些结果可以通过Hive、SCOOP等接口被用户的应用访问,进行交互式分析。
此外,Hadoop产生的分析结果能够被结构化并存放在传统的关系数据库或数据仓库中,并利用结构化分析平台的能力对数据进行进一步分析和展现,实现与传统的商业智能应用接轨。
在本解决方案中,微软提供了基于WindowsServer或WindowsAzure的Hadoop平台便于用户快速部署和维护Hadoop平台;同时,微软通过PDWconnectionforHadoop,提供PDW向Hadoop的访问和Hadoop分析结果向PDW数据仓库的装载。
2.云服务平台
作为全国性旅游信息管理系统,在信息系统基础架构建设层面,将遵循云计算的管理方式以及该旅游平台的管理要求,对所有基础架构资源进行一体化资源管理,在实施前期对所需的硬件物理设备进行规划,包括其所需的计算资源、存储资源、网络资源等。
在底层基于虚拟化技术,在保证可靠性能的同时,可根据平台具体的需要动态分配所需所有硬件物理资源。
从而有效提高硬件资源利用效率,降低硬件投资成本。
云服务平台能够提供全面的云计算管理功能,其中包括:
自服务功能:
提供服务的自由选择,旅游信息系统管理员可以根据实际业务的需求选择不同的服务资源,比如计算资源可以根据操作系统、处理器能力和内存大小等来选择,或对现有的旅游信息系统资源进行伸缩调整。
服务生命周期管理:
提供当前云平台所支持申请资源组合(套餐)目录列表,应用管理员以及开发测试人员可根据需要发起资源申请流程。
资源管理:
主要管理着平台的核心资源,包括帐号、权限、镜像文件、虚拟机、网络配置、存储配置、软硬件以及软件许可等。
资源服务:
对资源池资源的操作封装,将底层资源包装成服务,其中包括数据采集、监控告警、软件部署、应用迁移、备份与恢复等子模块。
安全管理:
对整个云平台以及旅游信息系统的安全进行统一管理,其中包括:
用户管理,访问认证,安全审计,漏洞管理,补丁管理,安全配置管理,安全事件管理,资源池安全控制等。
云计算平台的设计追求标准化、开放性、完备性、健壮性、灵活性、可监控/可跟踪性、安全性、运营性和可维护性等要求,同时遵循松耦合、模块化、可重用、可配置的原则,以B/S架构设计并保持可扩展性,为旅游局提供可度量的标准服务。
并将采用Java、.NET等开发平台进行开发,基于以上要求,提供以下动态云计算平台的架构设计。
在满足以上所有建设目标的同时,云计算平台在构建过程中同时涵盖一个更为重要的功能特征-----利旧,即通过技术手段将现有的IT环境转换整合到该云平台资源池中,一方面达到扩充资源池的目的,另外一方面则使得老旧资源能够被重复使用,减少投入。
三、部署架构
1.大数据平台物理架构
大数据平台的Hadoop集群由X86机架PC服务器及相关网络设备等构成。
在整个Hadoop集群中,主要包括主节点和从结点两部分
此外,围绕Hadoop集群,还需要配置ETL服务器,数据获取服务器,BI服务器,数据挖掘服务器,这些服务器与数据仓库平台的相关服务器整合,提供综合的服务。
Hadoop采用主/从结构的。
一个集群有一个主结点,也就是主控制服务器,负责管理文件系统的名字空间并协调客户对文件的访问。
还有一堆从结点(数据节点),一般一个物理结点上部署一个,负责它们所在的物理结点上的存储管理。
HDFS开放文件系统的命名空间以便让用户数据存储的文件中。
内部,一个文件被分割为一个或者多个数据块,这些数据块存储在一组数据结点中。
主结点执行文件系统的名字空间操作,比如打开、关闭、重命名文件或目录,还决定数据块从数据结点的映射。
数据结点负责提供客户的读写请求。
从结点还依照名字结点的指令执行数据块的创建、删除复制工作。
主结点和从结点是设计为运行在普通机器上的软件组件。
这些机器大多运行基于x86的Windows或Linux操作系统。
HDFS使用JAVA语言来实现;任何支持JAVA的机器都可以运行名字结点和数据结点软件。
使用高度可以移植的JAVA语言意味着HDFS可以被很多种机器使用。
一般小型规模的Hadoop集群可以配置如下:
2.数据仓库平台物理架构
采用多节点MPP架构的并行数据仓库机架系统,包括一个执行控制功能的控制节点和一个或多个存储用户数据并处理并行查询的数据节点。
当用户数据量增长或要求更高的计算能力时,可以增加更多的计算节点甚至更多的机架。
PDW体系结构的各组件如下图所示:
管理服务器:
客户端通过管理服务器中的“控制”节点访问并行数据仓库平台,该节点将整个基础结构抽象为一个单独的数据库并提供了单独的管理点。
并行数据仓库需支持通用的数据接口,如基于ADO.Net、OLEDB和ODBC的连接。
控制节点为一体机提供了控制、管理和用户界面功能。
它充当了用户与计算节点之间的界面。
一种称为“AdminConsole”的基于浏览器的实用工具为该一体机提供了全面的监控。
MPP引擎在控制节点中运行,它会分析传入的请求。
它利用数据智能来创建一体机范围内的并行查询计划并协调一体机内的查询执行情况。
一体机范围内的元数据和数据库配置数据也存储在控制节点内。
DMS(DataMovementService,数据移动服务)作为一种服务在控制节点中运行,它负责一体机各节点之间的数据传输。
它会处理需要在节点之间传输数据的查询操作,它的主要功能是优化数据传输速度,从而能够提高性能。
控制节点作为并行数据仓库的一个实例运行,它可以管理并行数据仓库的全局元数据。
计算服务器:
计算节点服务器是该解决方案的存储功能和可伸缩性的一个基本组成部分。
每个计算节点都作为数据库的一个实例运行,如其名称所示,大部分计算和查询操作都在此节点内执行。
计算节点中的数据机架装载着存储用户数据库并执行并行查询操作的硬件。
每个用户数据库都分布在多个数据库实例之间。
您可以使用多个数据机架,并通过添加数据机架来提高存储量和性能(如上文所述)。
它以无共享体系结构为基础,不与其它计算节点共享存储器、CPU或内存。
高可用服务器:
每个机架都有一台或多台备用服务器,它配置为被动式群集服务器。
如果机柜中某个服务器无法使用,其上的应用实例将会转移到备用服务器
并行数据仓库平台的数据常用以下两种方式进行部署:
表可以在各节点之间进行哈希分布(需要选择分布密匙),或复制到每个节点上(较小的表)。
数据分布是查询并行化的基础,它为大型数据集带来了高性能。
对于经过分布的表,其行分散在多个存储位置上。
每个存储位置包含一组单行或多行,称为一个分布区。
下图展示了一个完整的表(未经过分布的表)如何存储为一个分布表。
分布区存储在计算节点上;在一体机中,每个计算节点有八个分布区。
每行属于且只属于一个分布区。
并行数据仓库使用确定性的哈希算法将每个行分配到分布区。
根据表的大小不同,每个分布区存储的表行数量可能会有所差异。
为了包含无共享体系结构,每个分布区都存储在其自己的磁盘组上。
为了达到此目的,每个计算节点的存储阵列都分割为磁盘组(LUN)。
每个分布区都存储在一个计算节点的一个LUN上。
复制表都整体存储在每个计算节点上。
如要复制某个表,就无需在执行JOIN操作之前在各计算节点之间传输其表行。
因为每个计算节点都需要额外的存储空间来存储完整的表,所以复制表仅适用于小型表。
下图展示了复制表是如何存储在每个计算节点上的。
计算节点的每个磁盘组(LUN)都存储着一部分行。
这是通过SQLServer文件组实现的。
并行数据仓库提供了一种“横向伸缩”(scale-out)的方法来添加额外的机架,以提供额外的CPU、RAM和存储容量。
提供了一个具有高度灵活性和可扩展性的模型进行大规模、不断扩展的数据仓库部署。
并行数据仓库中每个计算节点都包含


- 配套讲稿:
如PPT文件的首页显示word图标,表示该PPT已包含配套word讲稿。双击word图标可打开word文档。
- 特殊限制:
部分文档作品中含有的国旗、国徽等图片,仅作为作品整体效果示例展示,禁止商用。设计者仅对作品中独创性部分享有著作权。
- 关 键 词:
- 硬件 平台 解决方案
 冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 转基因粮食的危害资料摘编Word下载.docx
转基因粮食的危害资料摘编Word下载.docx
-
高中英语词组大全Word文档下载推荐.docx
-
卫计局年工作总结及新年工作计划Word格式.docx
-
贵州省煤矿安全管理人员安全资格证A考试概况Word格式.docx
-
系统集成项目招标文件Word文件下载.docx
-
电子商务考试题总汇打印版打印打印Word下载.docx
-
选调生考试备考言语理解与表达真题Word文档格式.docx
-
高考物理实验题专练 专练15Word文档格式.docx
-
加装奥迪A4L蓝牙电话功能Word文档下载推荐.docx
-
学年下学期好教育高三月考仿真卷A卷 语文 学生版后附详解Word文档下载推荐.docx
-
净化生产车间工程一般施工技术施工方案Word文档格式.docx
-
内蒙古呼和浩特市第六中学学年高一政治下学期期末考试试题Word下载.docx
-
证券行业客户经理电话营销技巧与实例Word文档下载推荐.docx
-
叶芝 苇间风文档格式.docx
-
最新中美贸易摩擦的原因及解决对策1论文Word文件下载.docx
-
意义的近义词Word格式文档下载.docx
-
上海市中考英语试题S.docx
-
专题12观点论证类设问.docx
-
附加安心重疾条款.docx
-
设计变更管理办法修改意见稿FINAL汇编.docx
-
毕业赠言毕业致词精选多篇.docx
-
银行新员工代表发言稿精选多篇.docx
-
北京市朝阳区届高三第一学期期末语文试题Word版含答案.docx
-
HL线切割使用说明书模板.docx
-
车工实训周记.docx
-
USBHID键盘扫描码.docx
-
Apmpoqu4调研报告.docx
-
最熟悉的陌生人作文八篇.docx
-
被动语态综合讲解.docx
-
部编版语文七上第五单元16猫同步练习试题.docx
-
软件体系结构作业2.docx
-
钢管管道安装焊接施工工艺.docx
-
安全等级保护3级和2级的区别long.docx
-
最新电厂个人专业技术总结精选多篇.docx
-
土木工程监理实习报告.docx
-
最新教育教学随笔5篇中班教育随笔大全1.docx
-
营销策划阳台农场策划书.docx
-
建筑工程制图实训总结.docx
-
护理基础试题医院感染.docx
-
产科复核评估标准.docx
-
学生会主席就职演讲稿集锦15篇.docx
-
幼儿园外出学习心得体会四篇.docx
-
住房城乡建设部公布《建筑业企业资质管理规定 》及《建筑业企业资质管理规定和资质标准实施意见》.docx
-
污水处理厂工程技术标.docx
-
版十八项护理核心制度.docx
-
医学英语常用词汇.docx
-
优质护理服务评价细则.docx
-
医院消毒管理工作总结.docx
-
XXXXX山体滑坡地质灾害治理工程施工方案.docx
-
并机技术方案汇总.docx
-
护理人员理论考试分析.docx
