 数据库系统实现复习提纲.docx
数据库系统实现复习提纲.docx
- 文档编号:433998
- 上传时间:2022-10-10
- 格式:DOCX
- 页数:16
- 大小:1.13MB
数据库系统实现复习提纲.docx
《数据库系统实现复习提纲.docx》由会员分享,可在线阅读,更多相关《数据库系统实现复习提纲.docx(16页珍藏版)》请在冰豆网上搜索。
数据库系统实现复习提纲
复习提纲2015
1.数据库管理系统主要包括存储管理器、查询处理器和事务管理器等几个子系统。
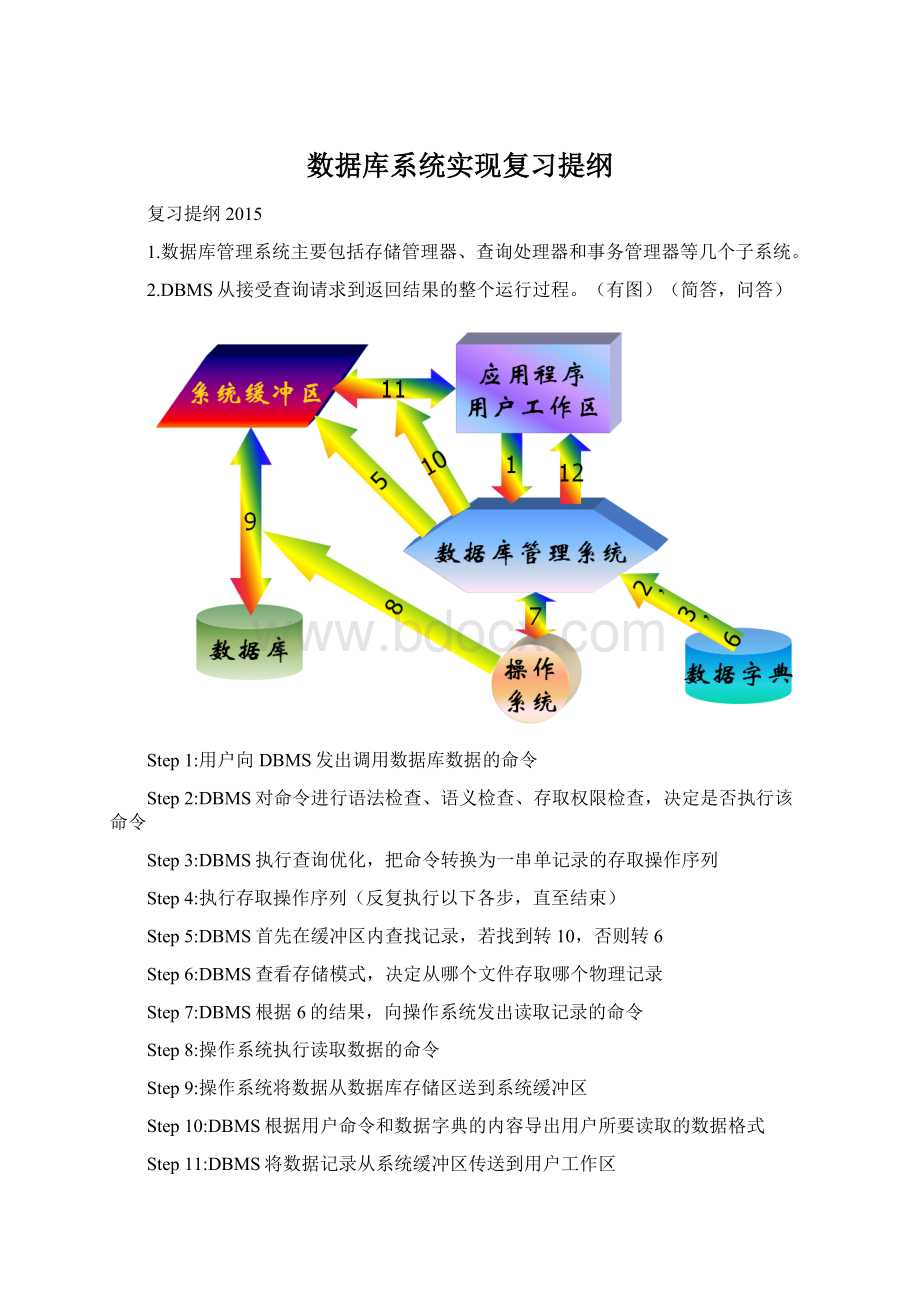
2.DBMS从接受查询请求到返回结果的整个运行过程。
(有图)(简答,问答)
Step1:
用户向DBMS发出调用数据库数据的命令
Step2:
DBMS对命令进行语法检查、语义检查、存取权限检查,决定是否执行该命令
Step3:
DBMS执行查询优化,把命令转换为一串单记录的存取操作序列
Step4:
执行存取操作序列(反复执行以下各步,直至结束)
Step5:
DBMS首先在缓冲区内查找记录,若找到转10,否则转6
Step6:
DBMS查看存储模式,决定从哪个文件存取哪个物理记录
Step7:
DBMS根据6的结果,向操作系统发出读取记录的命令
Step8:
操作系统执行读取数据的命令
Step9:
操作系统将数据从数据库存储区送到系统缓冲区
Step10:
DBMS根据用户命令和数据字典的内容导出用户所要读取的数据格式
Step11:
DBMS将数据记录从系统缓冲区传送到用户工作区
Step12:
DBMS将执行状态信息返回给用户
3.存储管理器负责管理的数据包括目标数据、元数据、索引和日志等,这些数据保存在磁盘上。
4.磁盘结构及磁盘容量的计算。
(填空题)
磁盘控制器:
控制一个或多个磁盘的小处理器,功能如下,
●定位磁头到一个特定的半径位置。
●选择一个准备读写的盘面,从位于该盘面的磁头下的磁道上选择一个扇区。
并识别何时该扇区正开始移动到磁头下面。
●将从该扇区读取的二进制位传送到主存储,或将从主存要写入的二进制位传送到该扇区。
●为所写扇区附加校验和,并在读取扇区时检查它。
●进行坏扇区的重映射。
硬盘容量=柱面数(表示每面盘面上有几条磁道,一般总数是1024)×磁头数(表示盘面数)×扇区数(表示每条磁道有几个扇区,一般总数是64)×扇区(存储基本单元,大小一般为512B/4KB)
5.一次磁盘访问(I/O)的时间包括寻道时间(占时多)、定位时间(中)和读取时间(小),相互关系。
6.磁盘块存取的优化方法。
(调度那些,双缓冲,什么鬼)(填空,简答)
⏹在主存储器中对块进行缓冲以减少块的读写次数
⏹按柱面组织数据
⏹使用多个磁盘
⏹磁盘镜像
⏹磁盘臂调度--电梯算法
⏹利用非易失性RAM作为写缓冲
⏹预读和双缓冲
⏹日志磁盘
7.RAID具有提高性能和提高可靠性能两方面的作用。
(填空题)
RedundantArraysofInexpensiveDisks
价格上,大量廉价的磁盘比少量昂贵的大磁盘合算得多
性能上,使用大量磁盘可以提高数据的并行存取
可靠性上,冗余数据可以存放在多个磁盘上,因此一个磁盘的故障不会导致数据丢失
RAID级别
RAID0级:
块级拆分,无冗余
RAID1级:
带块级拆分的磁盘镜像
RAID2级:
内存风格的纠错码组织结构
RAID3级:
位交叉的奇偶校验组织结构
RAID4级:
块交叉的奇偶校验组织结构
RAID5级:
块交叉的分布奇偶校验位的组织结构
RAID6级:
P+Q冗余方案
8.重点掌握RAID4(块级拆分,奇偶校验)、RAID5(块级拆分,)和RAID6(提供两个冗余盘,允许两个盘出现故障)优缺点(填空简答)
RAID4
假定:
有4个数据盘和一个冗余盘
读出数据,和从任何一个磁盘读块没有差别;
写数据需要2次磁盘读和2次磁盘写操作。
RAID5
将数据和奇偶校验位都分布到所有的N+1个磁盘上;对每个块,一个磁盘存储奇偶校验位,其余磁盘存储数据
例如由5个磁盘组成的阵列,第n块的奇偶校验位存储在第(nmod5)+1上,其余4个磁盘的第n块存储了对应这个块的实际数据
奇偶校验块不能和这个块对应的数据存储在同一个磁盘上
所有磁盘都参和对读请求的服务,而RAID4中奇偶校验磁盘不参和读操作
RAID5包容了RAID4,同时在相同成本下,提供了更好的读写性能
RAID6
类似于RAID5,存储了额外的冗余信息
不采用奇偶校验位的方法,使用类似Reed-Solomon码的编码
对每4位数据存储2位冗余信息
可以容忍两个磁盘发生故障
9.缓冲区管理工作流程。
(还有数据结构,填空简答)
数据结构和流程:
每个frame包括:
pin_count,dirty
pin_count:
正在访问该frame的事务的个数
Dirty:
已经被修改过的Frame
请求处理的流程
查看Bufferpool是否包含此页,如没有,则
找一个pin_count为0的frame,pin_count++
如dirty为true,则将其写入磁盘
将相应的页读入此frame
将frame的地址返回
10.文件中定长纪录的组织方法,纪录id(页号,块号)的组成。
11.文件中变长纪录的组织方法,纪录id(页号,块号,块内起始地址,长度)的组成。
(填空)
12.文件中组织纪录的几种方法:
堆文件组织、顺序文件组织、散列文件组织、聚簇文件组织。
(填空)
堆文件组织(heap)–一条记录可以放在文件中的任何地方,只要有空间存放这条记录。
记录是无序的。
通常一个关系是一个单独的文件。
顺序文件组织(sequential)–记录根据“搜索码”的值顺序存储。
散列文件组织(hashing)–在每条记录的某些属性上计算一个散列函数。
散列函数的结果确定了记录应该放到文件的哪个块中。
聚簇文件组织(clustering)–几个不同关系的记录存储在同一文件中(通常用一个文件存储一个关系的记录。
)甚至不同关系中的相关记录存储在相同的块中,于是一个I/O操作可以从多个关系中取到相关记录。
13.顺序文件组织中,为什么在进行大量插删改后需要重组?
(溢出块溢出表里)(简答题)
索引顺序文件上的修改动作:
创建或删除一个空存储块
创建或删除一个溢出块
插入一条记录到一个空块中
删除记录
将记录移动相邻的块中
14.索引是支持对于所要求的数据进行快速定位的附加的数据结构。
聚集索引和非聚集索引
稠密索引和稀疏索引
多级索引(填空)
15.B+树的树结点的大小一般取块的大小。
16.B+树的查询及构造方法,插入、删除方法,效率。
(简答,问答)
17.动态散列索引的实现原理(可扩充散列,实现方法,桶分裂~~)(简答,问答)
思想原理:
动态散列技术允许散列函数动态改变,通过桶的合并和分解实现数据库的增大或缩小的需求,这样既继承了散列高效查找效率又保持了良好的空间压缩率。
动态散列是逐步扩充散列值的位数来构造索引,它通过位比较来实现散列值的定位,这种比较方式计算机通过几个CPU机器指令即可实现,故它的效率很高。
18.在位图索引中,从位向量得到压缩编码位向量的方法以及从压缩编码位向量重新构造实际的位向量的方法(填空)K.O.
19.位图索引的构造及维护方法(简答)K.O.
20.查询优化是为关系代数表达式的计算选择最有效的查询计划的过程。
(填空题)
21.选择运算算法及代价分析(主要考虑带有B+树索引的情况)(填空题,分析题)
22.外部排序的算法(初始归并段的数目、归并的趟数)及代价分析(填空题,多空)
23.各种连接算法的实现及其代价分析(块嵌套循环连接算法、散列连接算法、排序-归并连接算法)(占比例高,分析题)
24.对于基于主码、外码连接的情况:
结果集的元组数等于外码所在表的元组数。
(填空题)
25.为什么要进行结果集大小的估计?
(判断要不要用索引)
26.DBMS中存储的统计信息(最大最小值,分布情况什么鬼)的作用是什么?
(制定执行计划时,计算代价需要)(简答题)
27.启发式优化的步骤。
(简答题)
28.事务的ACID特性,以及分别有什么机制保证(填空题)
事务定义:
事务是由一系列操作序列构成的程序执行单元,这些操作要么都做,要么都不做,是一个不可分割的工作单位,例如银行转帐。
SQL中事务的定义:
事务以Begintransaction开始,以Commitwork或Rollbackwork结束。
Commitwork表示提交,事务正常结束
Rollbackwork表示事务非正常结束,撤消事务已做的操作,回滚到事务开始时状态
事务特性(ACID):
原子性(Atomicity):
事务中包含的所有操作要么全做,要么全不做;原子性由恢复机制实现
一致性(Consistency):
事务的隔离执行必须保证数据库的一致性
事务开始前,数据库处于一致性的状态;事务结束后,数据库必须仍处于一致性状态
数据库的一致性状态由用户来负责,由并发控制机制实现
隔离性(Isolation):
系统必须保证事务不受其它并发执行事务的影响
对任何一对事务T1,T2,在T1看来,T2要么在T1开始之前已经结束,要么在T1完成之后再开始执行
隔离性通过并发控制机制实现
持久性(Durability):
一个事务一旦提交之后,它对数据库的影响必须是永久的
系统发生故障不能改变事务的持久性
持久性通过恢复机制实现
29.事务可串行化的判断一般采用优先图来实现,优先图的构造方法及可串行化的判断方法。
(什么鬼图,有没有环—可不可串行化)(填空)
可串行化:
若调度S和一个串行调度的执行有相同的效果,则称调度S是可串行化的。
冲突可串行化:
视图可串行化:
如果某个调度视图等价于一个串行调度,则称该调度是视图可串行化的,冲突可串行化调度一定是视图可串行化的,存在视图可串行化但非冲突可串行化的调度。
30.死锁(产生)及其解决方法(填空)
死锁:
如果系统中存在一个事务集,集合中的每个事务在等待该集合中的另一个事务所锁住的数据项,则称系统处于死锁状态。
处理死锁的两种主要方法:
⏹死锁预防:
采用死锁预防协议保证系统永不进入死锁状态
1:
对加锁请求加以限制
2:
强占和事务回滚
⏹死锁检测和死锁恢复:
允许系统进入死锁状态,然后进行检测和恢复。
------死锁恢复
选择牺牲者:
应使事务回滚带来的代价最小。
影响事务回滚代价的因素:
事务已计算了多久,在完成之前还将计算多长时间,事务已使用了多少数据项,为完成事务还需使用多少数据项,回滚时将牵涉多少事务
回滚:
彻底回滚,或只回滚到可以解除死锁处。
基于超时的机制:
一种介于死锁预防和死锁检测之间的折中的机制。
31.锁表结构(散列表?
)及其工作原理(在申请加锁,释放锁是怎样的)(简答题,问答)
封锁的实现
锁管理器中重要的数据结构:
锁表(locktable)。
⏹为目前已加锁的每个数据项维护一个链表,链表中每一个记录表示对该数据项的一个加锁请求。
记录按请求到达的顺序排序。
⏹链表中的每个记录主要包括如下内容:
哪个事务提出的请求,请求的锁类型,该请求是否已被授予锁。
⏹采用一个以数据项名称为索引的散列表作为链表入口。
锁管理器工作方式
⏹当一个封锁请求到达时,如果相应数据项的链表存在,则在该链表末尾增加一个记录,否则新建一个仅包含该请求的链表。
(数据项上的第一次加锁请求总是被授予,但当事务向已被加锁的数据项申请加锁时,只有当该请求和先前请求相容,并且所有先前的请求都已被授予锁的条件下,锁管理器才为该请求授予锁,否则令请求等待。
)
⏹当收到一个事务的解锁消息时,则将相应的链表记录删除,然后检查随后的记录,如果有正在等待的封锁请求,则看该请求能否被授权,如果能,则授权该请求并处理其后记录,如果还有,类似地一个接一个的处理。
⏹如果一个事务中止,则删除该事务产生的正在等待加锁的所有请求。
当数据库系统撤消了该事务,则该中止事务持有的所有锁将被释放。
32.同数据库交互的三个地址空间


- 配套讲稿:
如PPT文件的首页显示word图标,表示该PPT已包含配套word讲稿。双击word图标可打开word文档。
- 特殊限制:
部分文档作品中含有的国旗、国徽等图片,仅作为作品整体效果示例展示,禁止商用。设计者仅对作品中独创性部分享有著作权。
- 关 键 词:
- 数据库 系统 实现 复习 提纲
 冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 (完整word版)信息论与编码期末考试题----学生复习用.doc
(完整word版)信息论与编码期末考试题----学生复习用.doc
-
(完整)六年级上册几何图形题.docx
-
(完整)储罐防腐施工方案.doc
-
(完整word版)公务员录用体检表.doc
-
(完整)八年级上册几何证明题专项练习.doc
-
(决策管理)投资决策委员会实施细则.doc
-
(完整)四年级上册口算、竖式计算、脱式计算.doc
-
(压轴题)初中物理八年级上册第一章《机械运动》检测(含答案解析)(2).doc
-
(完整)小学三年级心理健康教案.doc
-
(完整)初中文言文翻译技巧.doc
-
(名师整理)语文中考《骆驼祥子》名著导读优秀教案.docx
-
(完整word版)偏旁部首名称大全.doc
-
(人教PEP)五年级英语竞赛试题及答案.doc
-
(完整)山东省普通高中学生综合素质评价信息管理系统操作手册学生用户手册.doc
-
(完整word版)体育课教案模板.doc
-
(住宅楼方案)房屋建筑学课程设计说明书.doc
-
(完整word版)《分数的意义》优秀教学设计(公开课).doc
-
(完整word版)安全生产标准化实施方案.doc
-
(完整)初中生人物形象分析常用词汇.doc
-
(完整版)借用公司资质协议.doc
-
(完整word版)仙剑奇侠传三图文攻略(最详细版).doc
-
(完整word版)历年陕西省专升本英语真题(答案解析超全).doc
-
(完整)四年级四则混合运算训练题100道.doc
-
(完整word版)学校团总支部换届选举方案.doc
-
(完整word版)安全标准化绩效评定计划.doc
-
(完整)分布式光伏发电项目施工组织设计.doc
-
(完整版)埋地塑料管结构环刚度计算.doc
-
(完整版)国家农业产业强镇示范建设实施方案.doc
-
(完整版)八年级数学上几何典型试题及答案.doc
-
(完整版)六年级音乐下册人音版理论知识梳理.doc
-
(完整版)囚徒健身图文教程和计划表(完美打印版).doc
 (完整版)固定资产盘点表.xls
(完整版)固定资产盘点表.xls
-
可编程自动门控制系统设计毕业设计.docx
-
职业规划 景立森1.docx
-
形容感触很深的句子.docx
-
物业管理服务要求及实施方案.docx
-
孝道演讲稿12篇完美版.docx
-
陕西省咸阳市实验中学高中英语链式高效课堂课时导.docx
-
国电智深DCS培训总结教程文件.docx
-
三支一扶个人工作总结个人工作总结三支.docx
-
学习管理学心得体会.docx
-
桩基施工论文集 精品.docx
-
王羲之行书结构92法.docx
-
社会学概论新修郑杭生第四版重点知识.docx
-
python练习题答案.docx
-
浅谈医院药品规范化管理.docx
-
三国杀卡牌说明.docx
-
江苏省兴化市顾庄学区届九年级语文下学期第二次模拟试题含答案.docx
-
新概念英语第一册教学计划.docx
-
学生会五月份工作计划精选5篇.docx
-
西华大学专升本计算机资料.docx
