 SAS实验报告.docx
SAS实验报告.docx
- 文档编号:4043612
- 上传时间:2022-11-27
- 格式:DOCX
- 页数:12
- 大小:105.70KB
SAS实验报告.docx
《SAS实验报告.docx》由会员分享,可在线阅读,更多相关《SAS实验报告.docx(12页珍藏版)》请在冰豆网上搜索。
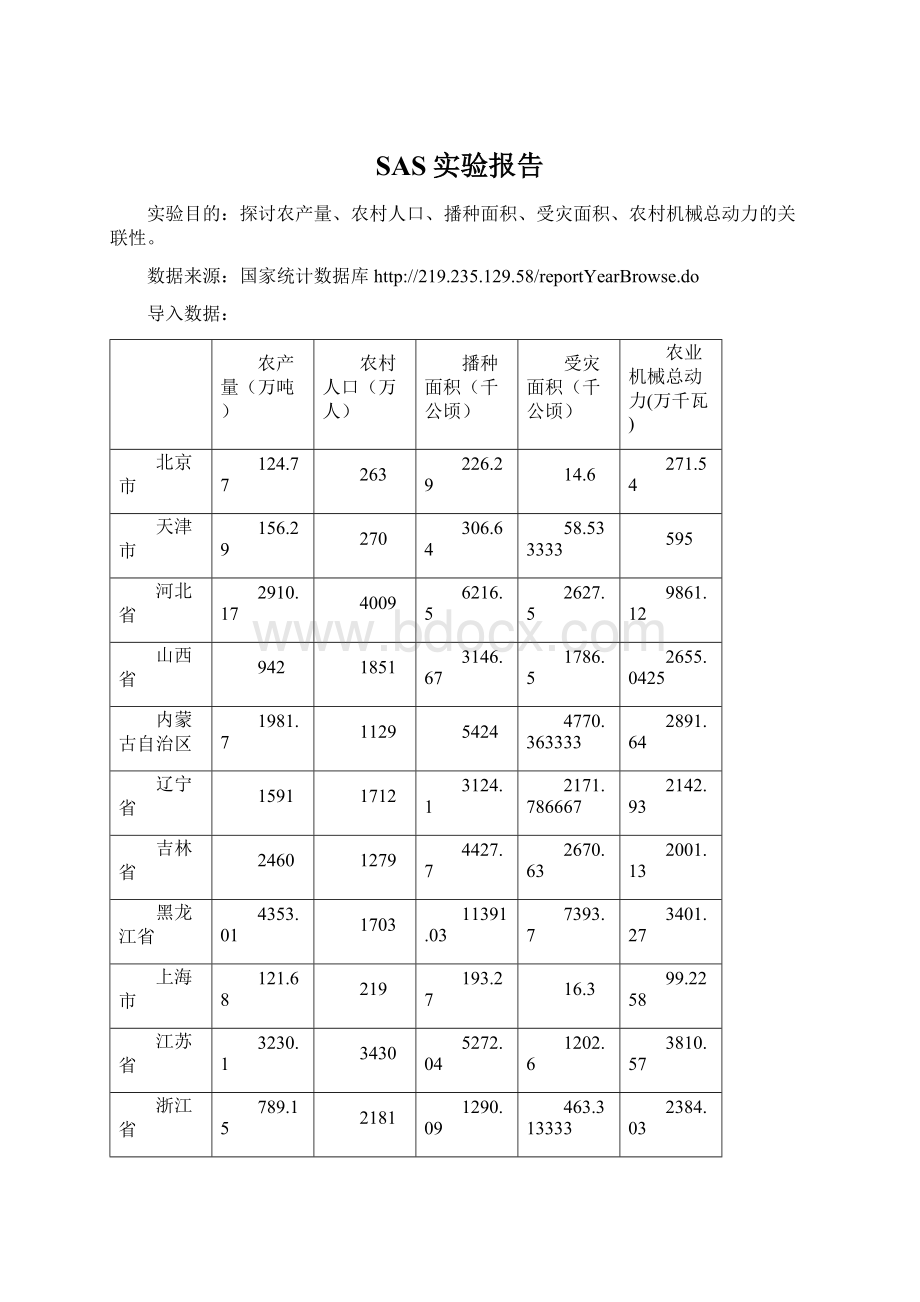
SAS实验报告
实验目的:
探讨农产量、农村人口、播种面积、受灾面积、农村机械总动力的关联性。
数据来源:
国家统计数据库http:
//219.235.129.58/reportYearBrowse.do
导入数据:
农产量(万吨)
农村人口(万人)
播种面积(千公顷)
受灾面积(千公顷)
农业机械总动力(万千瓦)
北京市
124.77
263
226.29
14.6
271.54
天津市
156.29
270
306.64
58.533333
595
河北省
2910.17
4009
6216.5
2627.5
9861.12
山西省
942
1851
3146.67
1786.5
2655.0425
内蒙古自治区
1981.7
1129
5424
4770.363333
2891.64
辽宁省
1591
1712
3124.1
2171.786667
2142.93
吉林省
2460
1279
4427.7
2670.63
2001.13
黑龙江省
4353.01
1703
11391.03
7393.7
3401.27
上海市
121.68
219
193.27
16.3
99.2258
江苏省
3230.1
3430
5272.04
1202.6
3810.57
浙江省
789.15
2181
1290.09
463.313333
2384.03
安徽省
3069.872484
3550
6605.568384
2101.32
5108.85
福建省
666.861112
1763
1231.012133
265.693333
1175.0092
江西省
2002.56
2518
3604.6
1351.676667
3358.93
山东省
4316.3
4894
7030.09
2341.87
11080.66
河南省
5389
5910
9683.61
2987.353333
9817.843
湖北省
2309.1
3089
4012.53
1827.1
3057.24
湖南省
2902.7
3639
4799.1
1824.87
4352.39
广东省
1314.5
3528
2538.5
643.3
2190.177
广西壮族自治区
1463.2
2952
3067.5
1109.61
2550.9337
海南省
187.604049
440
430.433876
119.9
396.07
重庆市
1137.2
1384
2229.49
495.1
967.41
四川省
3194.6
5017
6419.4
1598.763333
2952.66
贵州省
1168.27
2663
2984.73
779.866667
1606.4196
云南省
1576.92
3017
4200.13
1667.523333
2159.402
西藏自治区
90.53
221
169.43
53.04
358.44
陕西省
1131.4
2131
3133.973333
1220.666667
1832.9785
甘肃省
906.2
1775
2740.03
1880.796667
1822.65
青海省
102.69
324
275.72
159.58
388.68
宁夏回族自治区
340.7
337
826.88
365.533333
702.55
新疆维吾尔自治区
1152
1299
1984.7
1244.3
1503.31
全国
53082.077645
68497
108985.7577
47213.689999
87496.1013
实验过程:
①生成数据集
(以下均为2009年数据,number为各个省、直辖市、自治区代号,y为农产量(单位:
万吨),x1为农村人口(单位:
万人),x2为播种面积(单位:
千公顷),x3为受灾面积(单位:
千公顷),x4为农业机械总动力(单位:
万千瓦)):
dataexperiment;
inputnumberyx1x2x3x4@@;
cards;
1124.77263226.2914.6271.54
2156.29270306.6458.53595
32910.1740096216.52627.59861.12
494218513146.671786.52655.04
51981.7112954244770.362891.64
6159117123124.12171.792142.93
7246012794427.72670.632001.13
84353.01170311391.037393.73401.27
9121.68219193.2716.399.23
103230.134305272.041202.63810.57
11789.1521811290.09463.312384.03
123069.8735506605.572101.325108.85
13666.8617631231.01265.691175.01
142002.5625183604.61351.683358.93
154316.348947030.092341.8711080.66
16538959109683.612987.359817.84
172309.130894012.531827.13057.24
182902.736394799.11824.874352.39
191314.535282538.5643.32190.18
201463.229523067.51109.612550.93
21187.6440430.43119.9396.07
221137.213842229.49495.1967.41
233194.650176419.41598.762952.66
241168.2726632984.73779.871606.42
251576.9230174200.131667.522159.40
2690.53221169.4353.04358.44
271131.421313133.971220.671832.98
28906.217752740.031880.791822.65
29102.69324275.72159.58388.68
30340.7337826.88365.53702.55
31115212991984.71244.31503.31
;
run;
②基本统计量分析:
procunivariatedata=experiment;
varyx1x2x3x4;
run;
结果:
各地区农产量均值为1712.32万吨,标准差为1404.26;
各地区农村人口均值为2209.58万人,标准差为1544.86;
各地区播种面积均值为3515.67千公顷,标准差为2797.99;
各地区受灾面积均值为1523.02千公顷,标准差为1539.50;
各地区农业机械总动力均值为2822.46万千瓦,标准差为2773.71。
结果分析:
从各个变量的标准差来看,各地区的各项数据波动很大(标准差很大)。
③由于前面生成的数据集仅有2009年一年各地区的农产量,对于显著性差别分析数据不充分,所以添加2007年和2008年各地区的农产量数据进行分析:
dataabc;
doi=1to3;
donumber=1to31;
inputy@@;output;
end;end;
cards;
102.07147.152841.551007.051810.6918352453.77613462.94109.23132.24728.64
2901.4635.06093719044148.765245.222185.442692.21284.71396.600383177.51088
3027.00491100.860261460.7193.861067.91048824106.18415323.52867.04125.45
148.932905.8110282131.31860.328404225115.673175.49775.553023.3652.328336
1958.14260.55365.482227.2328051243.441394.7183.47741153.2314011581518.59
95.031111888.5101.8329.24930.5124.77156.292910.179421981.715912460
4353.01121.683230.1789.153069.872484666.8611122002.564316.353892309.1
2902.71314.51463.2187.6040491137.23194.61168.271576.9290.531131.4906.2
102.69340.71152
;
procnpar1waydata=abcWilcoxon;
classnumber;
vary;
run;
结果:
结果分析:
由结果得到Pr>Chi-Square的值小于0.0001,远小于临界概率值0.05,所以结论为在5%显著性水平下全国各地区的年农产量有显著性差异。
思考:
为什么全国各地区的年农产量会有显著性差异呢?
是否与农村人口数、播种面积、受灾面积、农业机械总动力等因素有关呢?
④回归分析:
procregdata=experiment;
modely=x1x2x3x4;
run;
结果:
结果分析:
从结果看出Pr>F的值小于0.0001,所以回归方程是显著的,而各自变量的Pr>|t|值中X1的为0.9454>0.05,X2、X3、X4的均小于0.05,所以变量X1对农产量y影响不显著,变量X2、X3、X4对农产量y影响显著。
然而选择哪些变量进行回归分析才能建立“最优”回归方程呢?
实验选用逐步回归的方法继续进行分析:
procregdata=experiment;
modely=x1x2x3x4/selection=stepwise;
run;
结果:
结果分析:
从输出结果来看,变量X2、X3、X4对农产量y影响显著,用其能建立“最优”回归方程。
建立“最优”回归方程:
procregdata=experiment;
modely=x2x3x4;
run;
结果:
结果分析:
由于结果中常数项Pr>|t|的值为0.7948,大于0.05,所以不显著,故消去常数项。
程序为:
procregdata=experiment;
modely=x2x3x4/noint;
run;
结果输出:
回归方程:
y=0.53197*x2–0.25023*x3+0.08213*x4
思考:
一次线性回归已达“最优”,但回归中是否可能含二次项呢?
画残差图分析。
procregdata=experiment;
modely=x2x3x4/p;
plotresidual.*x2='*';
run;
结果:
结果分析:
残差图接近正常的残差图,可认为回归方程不含二次项。
⑤聚类判别:
procclusterdata=experimentmethod=wardstdpesudocccouttree=aaa;
varx2x3x4;
idnumber;
proctreedata=aaahorizontalgraphicsn=4out=bbb;
copyx2-x4;
run;
procsortdata=bbb;
bycluster;
procmeansdata=bbb;
bycluster;
varx2x3x4;
run;
结果输出:
R2准则支持分为两类、三类和四类;伪F统计量支持分为六类、五类和四类;伪t2统计量支持分为三类、两类和四类。
综合分析,认为用离差平方和法分为四类比较合适。
分类结果为:
G1={北京市,西藏自治区,上海市,天津市,海南省,青海省,浙江省,福建省,宁夏回族自治区},G2={山西省,湖北省,江西省,云南省,辽宁省,甘肃省,吉林省,广东省,贵州省,重庆市,广西壮族自治区,陕西省,新疆维吾尔自治区,内蒙古自治区,江苏省,湖南省,四川省,安徽省},G3={河北省,山东省,河南省},G4={黑龙江省}。
由此看出,根据播种面积、受灾面积和农业机械总动力三个条件进行分类的结果与根据农产量分类的结果基本一致。
实验结论:
2009年各地区农产量均与播种面积、受灾面积和农业机械总动力有密切的关联性,与农村人口无关。
另外,全国31个省市自治区可根据农产量分为4类。


- 配套讲稿:
如PPT文件的首页显示word图标,表示该PPT已包含配套word讲稿。双击word图标可打开word文档。
- 特殊限制:
部分文档作品中含有的国旗、国徽等图片,仅作为作品整体效果示例展示,禁止商用。设计者仅对作品中独创性部分享有著作权。
- 关 键 词:
- SAS 实验 报告
 冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 如何打造酒店企业文化2刘田江doc.docx
如何打造酒店企业文化2刘田江doc.docx
-
律师提供著作权法律服务业务操作指引.docx
-
18秋福建师范大学《经济法》在线作业一.docx
-
施工现场危险源.docx
-
山东省潍坊市昌乐县学年七年级地理下学期期中学业质量评估试题.docx
-
新视野大学英语视听说教程第二版第一册完整答案.docx
-
精校版重庆市 初中毕业水平暨高中招生考试中考英语试题AB卷Word版含答案解析.docx
-
新视野大学英语视听说教程第二版第一册完整答案.docx
-
江苏省刘国钧中学1112学年高二语文上学期期末考前辅导试题卷苏教版会员独享.docx
-
山东省潍坊市昌乐县学年七年级地理下学期期中学业质量评估试题.docx
-
西安交通大学18年课程考试《管理会计》作业考核试题.docx
-
施工安全保证体系.docx
-
南开17秋学期《科学启蒙尔雅》在线作业2.docx
-
秋福师《大学英语1》在线作业二.docx
-
231695 北交《运输物流管理》在线作业2 15秋答案.docx
-
梁原学区安全管理工作实施方案.docx
-
环保管理台帐明细.docx
-
我国三大翻译证书考试概览.docx
-
东大17秋学期《大学英语二》在线作业31.docx
-
静态分析指标.docx
-
山东金瀚控股金瀚置业绩效考核指标库.docx
-
B0301A国际贸易.docx
-
人教版八年级数学上册同步练习试题及答案第11章《三角形》 同步练习及答案111.docx
-
秋福师《概率论》在线作业二.docx
-
17秋福师《高级英语阅读二》在线作业一.docx
-
西南大学17秋0764《工程建设监理》在线作业参考资料.docx
-
生活宝典之社会大转盘一.docx
-
专卖店管理.docx
-
100个CFO的八年之资金管理篇.docx
-
东北师范古代汉语三16秋在线作业2.docx
-
专业技术人员公共危机管理考试.docx
-
东大17秋学期《大学英语二》在线作业31.docx
-
吉林省吉林市第二中学届高三月考试题语文.docx
-
中学考试作文题目集锦.docx
-
助理物流师三级综合复习题.docx
-
幼儿园小班中秋节的活动方案.docx
-
升压站调试试验方案.docx
-
添加助磨剂试验.docx
-
生活垃圾焚烧处理工程技术规范.docx
-
投标报价上限值.docx
-
实验三类的构成和对象的使用.docx
-
软件测试流程.docx
-
计算机技能鉴定考试选择题.docx
-
语文高三大联考山东卷含答案.docx
-
又是一年时半命题作文.docx
-
软考网络工程师广域网和接入网练习题及答案.docx
-
语文老师整理的小学16年级重点难点+基础知识大全太实用了.docx
-
纪昌学射练习题.docx
-
三个人合伙协议.docx
-
玉米淀粉产业链分析.docx
-
中长篇睡前童话故事阅读文字版.docx
