 编码蛋白质的基因序列提交NCBI教程.pdf
编码蛋白质的基因序列提交NCBI教程.pdf
- 文档编号:30838892
- 上传时间:2024-01-30
- 格式:PDF
- 页数:12
- 大小:887.08KB
编码蛋白质的基因序列提交NCBI教程.pdf
《编码蛋白质的基因序列提交NCBI教程.pdf》由会员分享,可在线阅读,更多相关《编码蛋白质的基因序列提交NCBI教程.pdf(12页珍藏版)》请在冰豆网上搜索。
翻译蛋白的翻译蛋白的基因基因序列提交序列提交NCBI教程教程说明说明:
在上传编码蛋白质的基因到NCBI时,定义基因的CDS区段是非常重要的一步,也是大多数学生所迷茫和不会的地方。
那么,在基因序列上传时,大家还在发愁序列的CDS编码区段是从多少位碱基到哪吗?
这篇教程给大家详细的演示了如何定义手中序列的CDS区段,轻松上传序列。
注:
注:
大家都知道像ITS,18S,28S等这些序列片段不是基因,它们是不翻译蛋白质的,这个教程教大家如何提交能翻译蛋白的基因序列。
提交通道提交通道:
通过NCBI内的BanKIt进行提交。
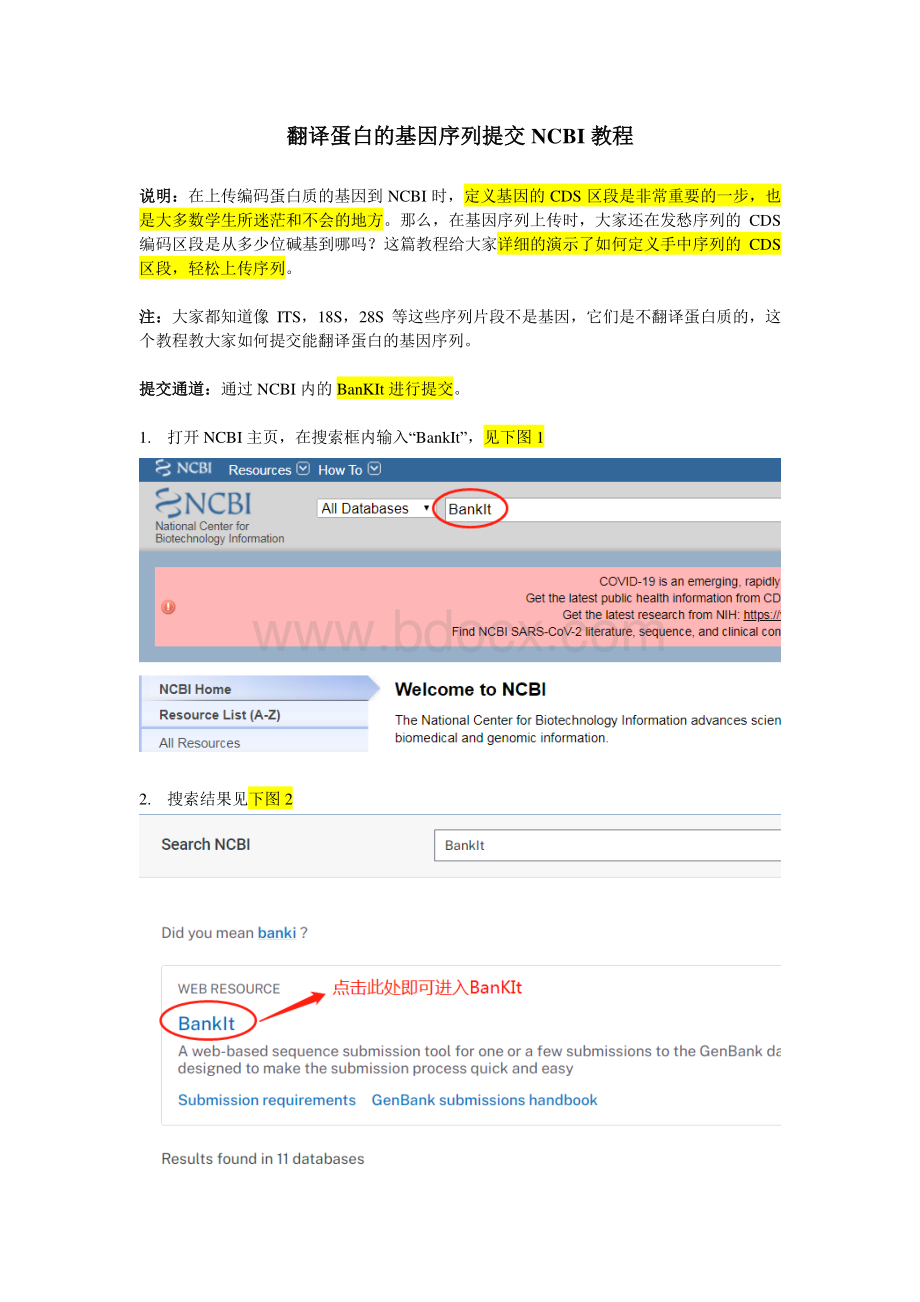
1.打开NCBI主页,在搜索框内输入“BankIt”,见下图12.搜索结果见下图23.进入后进行登录,用NCBI的账号和密码登录(注:
注:
如果没有,可以使用邮箱注册),登录后的页面见下图3,根据需要点击相应按钮开始进入序列提交界面(注:
注:
也可点击下图红色框圈出的位置)4.我们需完成如下图4中的8个步骤,即可完成提交5完成第一步的ContactInformation后,第二步的Reference我们需要填写如下图5的信息6SequencingTechnology选项,填写如下图67Nucleotide(这一步需要我们准备上传的序列文件)a.序列文件类型为fasta文件,我们需要先对序列进行定义(也就是介绍该序列,可以先将自己的序列在NCBI里Blast一下,然后再点开QueryCover(可理解为覆盖度)和Per.Ident(可理解为匹配度)都非常高的那个网上的参考序列,然后复制该参考序列的定义内容即可,见下图7-1)b.然后粘贴成为我们手中的序列定义,见下图7-2(注:
注:
不要忘记将菌株号改为自己的菌株号,序列开端一定要是“Seq1organism=genusspecies”,其中的Seq1可以用你的菌株号,也可以随意编号,只要你自己知道就可,方括号xxxx内填写自己序列的菌的拉丁名)c.准备好序列后,我们勾选如下图7-3的选项d.然后这个序列就可以载入了(点击Uploadfile),或者直接粘贴该序列,见下图7-4单个序列的界面注:
注:
这一步上传序列时你也可以将多条序列,包括不同基因的序列都可以准备到同一个fasta文件里,载入后再选择“Batch”(批量提交的意思),界面见下图7-5e.点击Continue8.Organism这一项需输入咱们的菌拉丁名,见下图89.SubmissionCategory如下图910.SourceModifiers这一项需要我们输入一些有关咱们的菌的信息,如采集国家,采集人,isolate,时间等信息,见下图1011.Features(Overview)这一项是非常重要的一项,也是大家经常有问题的一项,一定要认真学。
编码蛋白的序列提交界面需勾选如下选项,再点击Add,见图11-1a.接下来的操作需要我们对自己手中的序列的CDS区段进行定义(也就是从哪到哪是CDS区段),这需要我们先选择一条参考序列,正如上文讲到的,先将自己的序列在NCBI里Blast一下,然后再点开QueryCover(可理解为覆盖度)和Per.Ident(可理解为匹配度)都非常高的那个网上序列作为参考序列。
b.选定参考序列后,我们需要将这条序列的fasta序列下载下来,再将我们的序列和这条参考序列都载入到DNAMAN软件c.载入后,我们分别将这两条序列用DNAMAN进行翻译,具体步骤是点击菜单栏的“Protein”,选择“Translation”,再选择“Oneletter”即可将序列翻译成蛋白,如下图11-2翻译后的界面如下图11-3所示注:
注:
将哪条翻译就一定要用鼠标点击在DNAMAN的相应的序列频道上,如“Channel1里的序列,Channel2里的序列等,也可以直接点击左侧的频道1,2,3.”,,鼠标点在哪个频道上就是对哪个频道进行操作,见下图11-4d.分别将自己的序列和参考序列翻译后,我们就要开始定义自己序列的CDS了,如何进行定义呢?
首先我们需要在NCBI里查看这条参考序列的定义范围,如NigroporusvinosusJN710728,我们查看如下图11-5圈出的CDS区段内容,要知道这条序列是从哪里开始编码又从哪里编码结束的。
注:
注:
由上图我们发现参考序列首先是从52位碱基开始的到188位碱基结束.,而上图中编码的氨基酸的前几个分别为WSEDRFNE.。
那么我们需要先在参考序列中定位出它的第52位碱基及向后的几个碱基(我们可以用DNAMAN软件通过选中碱基进行查数,见下图11-6)e.然后我们先复制第52位碱基及向后的一小段碱基“TGGAGCGAGGA”f.复制后,我们需在DNAMAN中找到原先咱们翻译过的那个自己的序列,在这个翻译界面通过CTRL+F查找,咱们刚才复制的那一小段“TGGAGCGAGGA”,界面见下图11-7g.查找到“TGGAGCGAGGA”后,我们会发现当从序列开端处的第三个密码子开始翻译时,刚好氨基酸就是“WSEDRFN.”这说明是从第三位碱基开始编码的。
随后我们需要在自己的序列里定位“TGGAGCGAGGA”是从第几个碱基开始的(见下图11-8),通过在自己序列里定位我们知道“TGGAGCGAGGA”是从第12位碱基开始的,那么我们的序列的CDS编码的开端就找到啦。
h.随后,用同样的方法我们查找参考序列的第188位碱基,这时我们可以复制第188位碱基及其前面的一小段碱基(GTCCACCAA),然后再用这一小段复制的碱基在自己序列的翻译蛋白那一界面进行查找定位(注:
一定要看下图11-9,否则你看到的188并非是真正的188。
)i.在自己的序列翻译后的界面我们定位(GTCCACCAA)后,结果见下图11-10,我们可以在参考序列中定位到该段及其前面的几个氨基酸为LEEST,这说明正确。
j.随后我们在自己的序列里定位(GTCCACCAA),以明确其是第多少位碱基,经定位我们知道这一小段碱基的最后一位碱基A是第148位,所以我们知道我们的第一段CDS的范围为12-148(参见步骤g和j),而在参考序列中是从52-188开始的。
这样一来我们就完成了第一段的CDS定位,接下来需用同样的方法完成第二段及以后的定位。
大家自己试试吧。
12.Features选项我们需要勾选及填写如下区域,见下图1213.CDS定义完成后系统会给你生成一个氨基酸的序列,你需要核查一下你的氨基酸序列的开端和结尾是否和参考序列一样,有时由于自己的序列较短,我们的氨基酸序列会落在参考序列的区间内,大家可以用查找进行判断。
这样以来既可以完成提交了。
祝大家顺利。


- 配套讲稿:
如PPT文件的首页显示word图标,表示该PPT已包含配套word讲稿。双击word图标可打开word文档。
- 特殊限制:
部分文档作品中含有的国旗、国徽等图片,仅作为作品整体效果示例展示,禁止商用。设计者仅对作品中独创性部分享有著作权。
- 关 键 词:
- 编码 蛋白质 基因 序列 提交 NCBI 教程
 冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 江南大学现代远程教育 考试大作业1.docx
江南大学现代远程教育 考试大作业1.docx
-
江南大学《信息安全概论》大作业答案.docx
-
江南大学现代远程教育考试大作业.docx
-
江南大学现代远程教育2020年上半年课程考试大作业.docx
-
2020年江南大学信息安全概论大作业答案.docx
-
江南大学现代远程教育2020年上半年课程考试大作业..docx
-
江南大学现代远程教育 考试大作业.docx
-
兽医师执业活动年度报告登记表.docx
 美术开学第一课-二年级.pptx
美术开学第一课-二年级.pptx
-
中小学教师中高级职称答辩备考试题及答案.docx
-
安卓课程设计-手机通讯录系统.doc
-
名师选拔笔试试题.docx
-
2021年全国普通高等学校运动训练、民族传统体育专业单独统.docx
-
成人失禁相关性皮炎护理实践专家共识解读.pptx
-
人音版音乐六年级下册全册表格式教学设计.docx
-
教师职称学科带头人笔试面试参考题.docx
-
骨干教师选拔笔试试题初稿.docx
-
行政法学判断题.docx
-
动物诊疗机构年度报告登记表.docx
-
好学生好学法读后感.docx
-
房屋买卖合同(详细范本).docx
-
高中寒假开学第一课.pptx
-
XX工程项目管理规划大纲.docx
-
纳税基础与实务(说课课件).pptx
-
美术素描课程标准.docx
-
最新部编人教版小学五年级下册语文全册备课教案设计及板书反思.docx
-
植物组织培养教学设计.docx
-
老年科健康教育.docx
-
紧盯“双碳”目标走好绿色低碳“赶考路”PPT课件.pptx
-
肿瘤的绿色治疗.ppt
-
摄影摄像课程标准.docx
-
植物组织培养教案.docx
-
公交站规范化改造工程施工组织设计方案Word文件下载.docx
-
市场策划培训--常规销售数据统计流程PPT课件下载推荐.ppt
-
电子系统Word下载.docx
-
动力电池低温加热方法分类Word格式.docx
-
度全国二级建造师执业资格考试真题文档格式.docx
-
高中历史第一单元中国传统文化主流思想的演变第4课明清之际活跃的儒家思想同步测试新人教版必修3Word下载.docx
-
市场策划培训--标准合同、认购书制定与备案流程PPT文档格式.ppt
-
钢结构安装安全系统平台方案设计Word格式文档下载.docx
-
风电项目围堰及道路工程施工组织设计风机基础平台工程Word文件下载.docx
-
构建城乡教科研一体化促进庐阳教育均衡发展Word文档格式.docx
-
二手车评估报告模板空白可修改Word格式.docx
-
反洗钱非现场监管办法Word格式.docx
-
房地产各部门以及各岗位名称和职责Word格式.docx
-
高中数学人教版A版必修三配套单元检测第二章 单元检测 A卷 Word版含答案文档格式.docx
-
高中英语语法归纳总结Word文档下载推荐.docx
-
高等学校辅导员职业能力标准暂行文档格式.docx
-
高二语文第五单元 散而不乱 气脉中贯人教实验版知识精讲Word格式文档下载.docx
-
份工业微型计算机试题加答案Word文档下载推荐.docx
-
法律基础课件Word格式.docx
