 智能控制技术(亲自整理的知识点).doc
智能控制技术(亲自整理的知识点).doc
- 文档编号:30808514
- 上传时间:2024-01-30
- 格式:DOC
- 页数:8
- 大小:1.86MB
智能控制技术(亲自整理的知识点).doc
《智能控制技术(亲自整理的知识点).doc》由会员分享,可在线阅读,更多相关《智能控制技术(亲自整理的知识点).doc(8页珍藏版)》请在冰豆网上搜索。
智能控制
(1)智能控制与传统控制的区别
答:
传统控制方法包括经典控制和现代控制,是基于被控对象精确模型的控制方式,缺乏灵活性和应变能力,适于解决线性、时不变性等相对简单的控制问题,难以解决对复杂系统的控制。
智能控制能解决被控对象的复杂性、不确定性、高度的非线性,是传统控制发展的高级阶段.
(2)智能控制的概念
答:
智能控制是人工智能、自动控制、运筹学的交叉。
(3)1986年美国的PDP研究小组提出了BP网络,实现了有导师指导下的网络学习,为神经网络的应用开辟了广阔的发展前景。
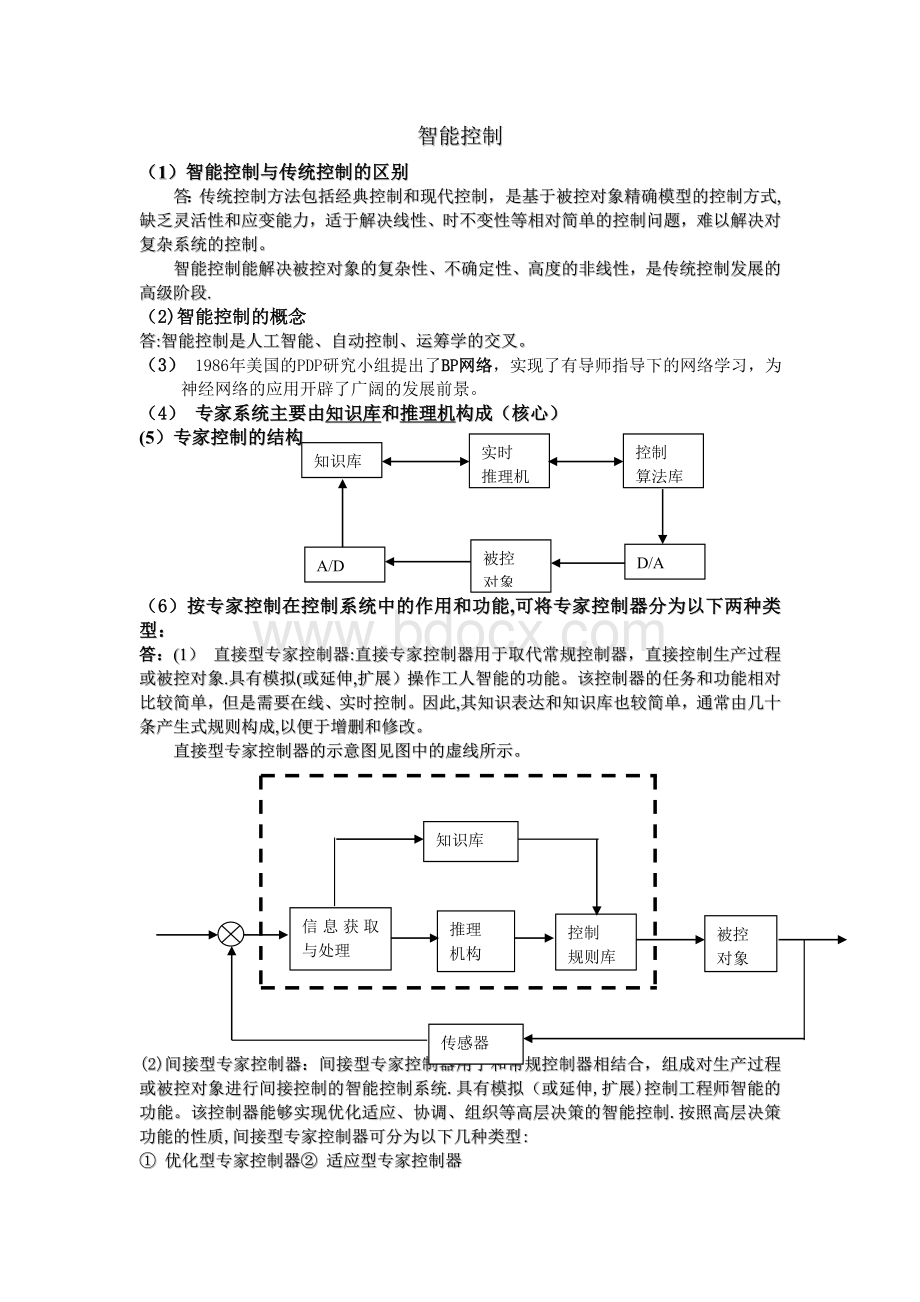
(4)专家系统主要由知识库和推理机构成(核心)
知识库
实时
推理机
A/D
被控
对象
D/A
控制
算法库
(5)专家控制的结构
(6)按专家控制在控制系统中的作用和功能,可将专家控制器分为以下两种类型:
答:
(1)直接型专家控制器:
直接专家控制器用于取代常规控制器,直接控制生产过程或被控对象.具有模拟(或延伸,扩展)操作工人智能的功能。
该控制器的任务和功能相对比较简单,但是需要在线、实时控制。
因此,其知识表达和知识库也较简单,通常由几十条产生式规则构成,以便于增删和修改。
直接型专家控制器的示意图见图中的虚线所示。
知识库
信息获取与处理
推理
机构
被控
对象
传感器
控制
规则库
(2)间接型专家控制器:
间接型专家控制器用于和常规控制器相结合,组成对生产过程或被控对象进行间接控制的智能控制系统.具有模拟(或延伸,扩展)控制工程师智能的功能。
该控制器能够实现优化适应、协调、组织等高层决策的智能控制.按照高层决策功能的性质,间接型专家控制器可分为以下几种类型:
①优化型专家控制器②适应型专家控制器
③协调型专家控制器④组织型专家控制器
例3。
4设
求A∪B,A∩B
则
(7)在模糊控制中应用较多的隶属函数有以下6种隶属函数。
(1)高斯型隶属函数
高斯型隶属函数由两个参数和c确定:
其中参数b通常为正,参数c用于确定曲线的中心。
Matlab表示为
(3)S形隶属函数
S形函数sigmf(x,[ac])由参数a和c决定:
其中参数a的正负符号决定了S形隶属函数的开口朝左或朝右,用来表示“正大"或“负大”的概念。
Matlab表示为
(4)梯形隶属函数
梯形曲线可由四个参数a,b,c,d确定:
其中参数a和d确定梯形的“脚”,而参数b和c确定梯形的“肩膀”。
Matlab表示为:
(5)三角形隶属函数
三角形曲线的形状由三个参数a,b,c确定
其中参数a和c确定三角形的“脚",而参数b确定三角形的“峰”。
Matlab表示为
(6)Z形隶属函数
这是基于样条函数的曲线,因其呈现Z形状而得名。
参数a和b确定了曲线的形状。
Matlab表示为
图高斯型隶属函数(M=1)图S形隶属函数(M=3)
图梯形隶属函数(M=4)图三角形隶属函数(M=5)
图Z形隶属函数(M=6)
例3-10设
则
例3—9设论域x={a1,a2,a3},y={b1,b2,b3},z={c1,c2,c3},已知
试确定“IfAANDBthenC”所决定的模糊关系R,以及
时的输出C1。
解:
将A×B矩阵扩展成如下列向量:
当输入为A1和B1时,有:
将A1×B1矩阵扩展成如下行向量:
最后得即:
(8)模糊控制原理框图
(9)模糊控制器的构成(模糊控制器的组成框图)
(10)模糊控制器结构类型
1单变量模糊控制器
(a)一维模糊控制器如图所示,一维模糊控制器的输入变量往往选择为受控量和输入给定的偏差量E。
由于仅仅采用偏差值,很难反映过程的动态特性品质,因此,所能获得的系统动态性能是不能令人满意的。
这种一维模糊控制器往往被用于一阶被控对象。
(a)(b)
(b)二维模糊控制器二维模糊控制器的两个输入变量基本上都选用受控变量和输入给定的偏差E和偏差变化EC,由于它们能够较严格地反映受控过程中输出变量的动态特性,因此,在控制效果上要比一维控制器好得多,也是目前采用较广泛的一类模糊控制器
(c)三维模糊控制器如图所示,三维模糊控制器的三个输入变量分别为系统偏差量E、偏差变化量EC和偏差变化的变化率ECC。
由于这些模糊控制器结构较复杂,推理运算时间长,因此除非对动态特性的要求特别高的场合,一般较少选用三维模糊控制器。
(11)将模糊推理结果转化为精确值的过程称为反模糊化。
常用的反模糊化有三种:
(1)最大隶属度法
选取推理结果模糊集合中隶属度最大的元素作为输出值,即
如果在输出论域V中,其最大隶属度对应的输出值多于一个,则取所有具有最大隶属度输出的平均值,即:
N为具有相同最大隶属度输出的总数.
(2)重心法
为了获得准确的控制量,就要求模糊方法能够很好的表达输出隶属度函数的计算结果。
重心法是取隶属度函数曲线与横坐标围成面积的重心为模糊推理的最终输出值,即对于具有m个输出量化级数的离散域情况与最大隶属度法相比较,重心法具有更平滑的输出推理控制。
即使对应于输入信号的微小变化,输出也会发生变化。
(3)加权平均法
工业控制中广泛使用的反模糊方法为加权平均法,输出值由下式决定
其中系数ki的选择根据实际情况而定。
不同的系数决定系统具有不同的响应特性.当系数取隶属度时,就转化为重心法。
(12)神经元/神经细胞由三部分构成:
(1)细胞体(主体部分):
包括细胞质、细胞膜和细胞核;
(2)树突:
用于为细胞体传入信息;
(3)轴突:
为细胞体传出信息,其末端是轴突末梢,含传递信息的化学物质;
(4)突触:
是神经元之间的接口(104~105个/每个神经元)。
一个神经元通过其轴突的神经末梢,经突触与另外一个神经元的树突连接,以实现信息的传递。
由于突触的信息传递特性是可变的,随着神经冲动传递方式的变化,传递作用强弱不同,形成了神经元之间连接的柔性,称为结构的可塑性。
(13)神经网络的分类
根据神经网络的连接方式,神经网络可分为两种形式:
(1)前向网络
(2)反馈网络(3)自组织网络
(14)神经网络学习算法按有无导师分类
可分为有教师学习、无教师学习和再励学习等几大类。
(15)最基本的神经网络学习算法:
Hebb学习规则、Delta(δ)学习规则、概率式学习规则、竞争式学习规则
(16)神经网络特征
(1)能逼近任意非线性函数;
(2)信息的并行分布式处理与存储;
(2)便于用超大规模硬件实行并行处理(3)能进行学习,以适应环境的变化
(17)神经网络要素
(1)神经元(信息处理单元)的特性;
(2)神经元之间相互连接的形式-拓扑结构;
(3)为适应环境而改善性能的学习规则。
(18)BP网络特点
(1)是一种多层网络,包括输入层、隐含层和输出层
(2)层与层之间采用全互连方式,同一层神经元之间不连接;
(3)权值通过δ学习算法进行调节;
(4)神经元激发函数为S函数;
(5)学习算法由正向传播和反向传播组成;
(6)层与层的连接是单向的,信息的传播是双向的。
(19)BP算法的学习过程
由正向传播和反向传播组成。
在正向传播过程中,输入信息从输入层经隐层逐层处理,并传向输出层,每层神经元(节点)的状态只影响下一层神经元的状态。
如果在输出层不能得到期望的输出,则转至反向传播,将误差信号(理想输出与实际输出之差)按联接通路反向计算,由梯度下降法调整各层神经元的权值,使误差信号减小.
(20)神经网络监督控制
(21)神经网络直接逆动态控制
(22)遗传算法的基本原理
(1)遗传
(2)变异(3)生存斗争和适者生存
(23)遗传算法的基本操作为:
(1)复制
(2)交叉(3)变异
(24)遗传算法的构成要素
(1)染色体编码方法
(2)个体适应度评价
(3)遗传算子①选择运算:
使用比例选择算子;
②交叉运算:
使用单点交叉算子;
③变异运算:
使用基本位变异算子或均匀变异算子.
(4)基本遗传算法的运行参数
(25)遗传算法的应用步骤
第一步:
确定决策变量及各种约束条件,即确定出个体的表现型X和问题的解空间;
第二步:
建立优化模型,即确定出目标函数的类型及数学描述形式或量化方法;
第三步:
确定表示可行解的染色体编码方法,即确定出个体的基因型x及遗传算法的搜索空间;
第四步:
确定解码方法,即确定出由个体基因型x到个体表现型X的对应关系或转换方法;
第五步:
确定个体适应度的量化评价方法,即确定出由目标函数值到个体适应度的转换规则;
第六步:
设计遗传算子,即确定选择运算、交叉运算、变异运算等遗传算子的具体操作方法.
第七步:
确定遗传算法的有关运行参数,即M,G,Pc,Pm等参数。


- 配套讲稿:
如PPT文件的首页显示word图标,表示该PPT已包含配套word讲稿。双击word图标可打开word文档。
- 特殊限制:
部分文档作品中含有的国旗、国徽等图片,仅作为作品整体效果示例展示,禁止商用。设计者仅对作品中独创性部分享有著作权。
- 关 键 词:
- 智能 控制 技术 亲自 整理 知识点
 冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 江南大学现代远程教育 考试大作业1.docx
江南大学现代远程教育 考试大作业1.docx
-
江南大学《信息安全概论》大作业答案.docx
-
江南大学现代远程教育考试大作业.docx
-
江南大学现代远程教育2020年上半年课程考试大作业.docx
-
2020年江南大学信息安全概论大作业答案.docx
-
江南大学现代远程教育2020年上半年课程考试大作业..docx
-
江南大学现代远程教育 考试大作业.docx
-
兽医师执业活动年度报告登记表.docx
 美术开学第一课-二年级.pptx
美术开学第一课-二年级.pptx
-
中小学教师中高级职称答辩备考试题及答案.docx
-
安卓课程设计-手机通讯录系统.doc
-
名师选拔笔试试题.docx
-
2021年全国普通高等学校运动训练、民族传统体育专业单独统.docx
-
成人失禁相关性皮炎护理实践专家共识解读.pptx
-
人音版音乐六年级下册全册表格式教学设计.docx
-
教师职称学科带头人笔试面试参考题.docx
-
骨干教师选拔笔试试题初稿.docx
-
行政法学判断题.docx
-
动物诊疗机构年度报告登记表.docx
-
好学生好学法读后感.docx
-
房屋买卖合同(详细范本).docx
-
高中寒假开学第一课.pptx
-
XX工程项目管理规划大纲.docx
-
纳税基础与实务(说课课件).pptx
-
美术素描课程标准.docx
-
最新部编人教版小学五年级下册语文全册备课教案设计及板书反思.docx
-
植物组织培养教学设计.docx
-
老年科健康教育.docx
-
紧盯“双碳”目标走好绿色低碳“赶考路”PPT课件.pptx
-
肿瘤的绿色治疗.ppt
-
摄影摄像课程标准.docx
-
植物组织培养教案.docx
-
月理财规划师考试二级理论知识真题.docx
-
招标控制价指标分析及设计概算.docx
-
浙教版七年级数学下册试题第6章《数据与统计图表》单元培优测试题docx.docx
-
诚信教育活动方案7篇.docx
-
城市生活垃圾的处理方式及资源化利用.docx
-
质量保证体系及安全保证措施.docx
-
出纳个人工作总结怎么写.docx
-
初级会计职称经济法基础考试真题及答案.docx
-
初三临考前家长会发言稿精品范文.docx
-
中小企业信息化发展.docx
-
初中德育活动实施方案.docx
-
重庆交通大学双福校区李子湖畔签约须知.docx
-
初中生阅读方法指导一.docx
-
装饰装修工程计量计价编制实训指导书.docx
-
初中信息奥赛题库编程基础之循环控制.docx
-
组织行为学研究所里来了个老费案例分析答案.docx
-
除夕的小学作文.docx
-
处长年度工作总结三篇.docx
-
《好题》小学数学三年级下册第三单元《复式统计表》 单元检测题包含答案解析3.docx
