 C语言运算符的优先级.docx
C语言运算符的优先级.docx
- 文档编号:28895595
- 上传时间:2023-07-20
- 格式:DOCX
- 页数:21
- 大小:25.51KB
C语言运算符的优先级.docx
《C语言运算符的优先级.docx》由会员分享,可在线阅读,更多相关《C语言运算符的优先级.docx(21页珍藏版)》请在冰豆网上搜索。
C语言运算符的优先级
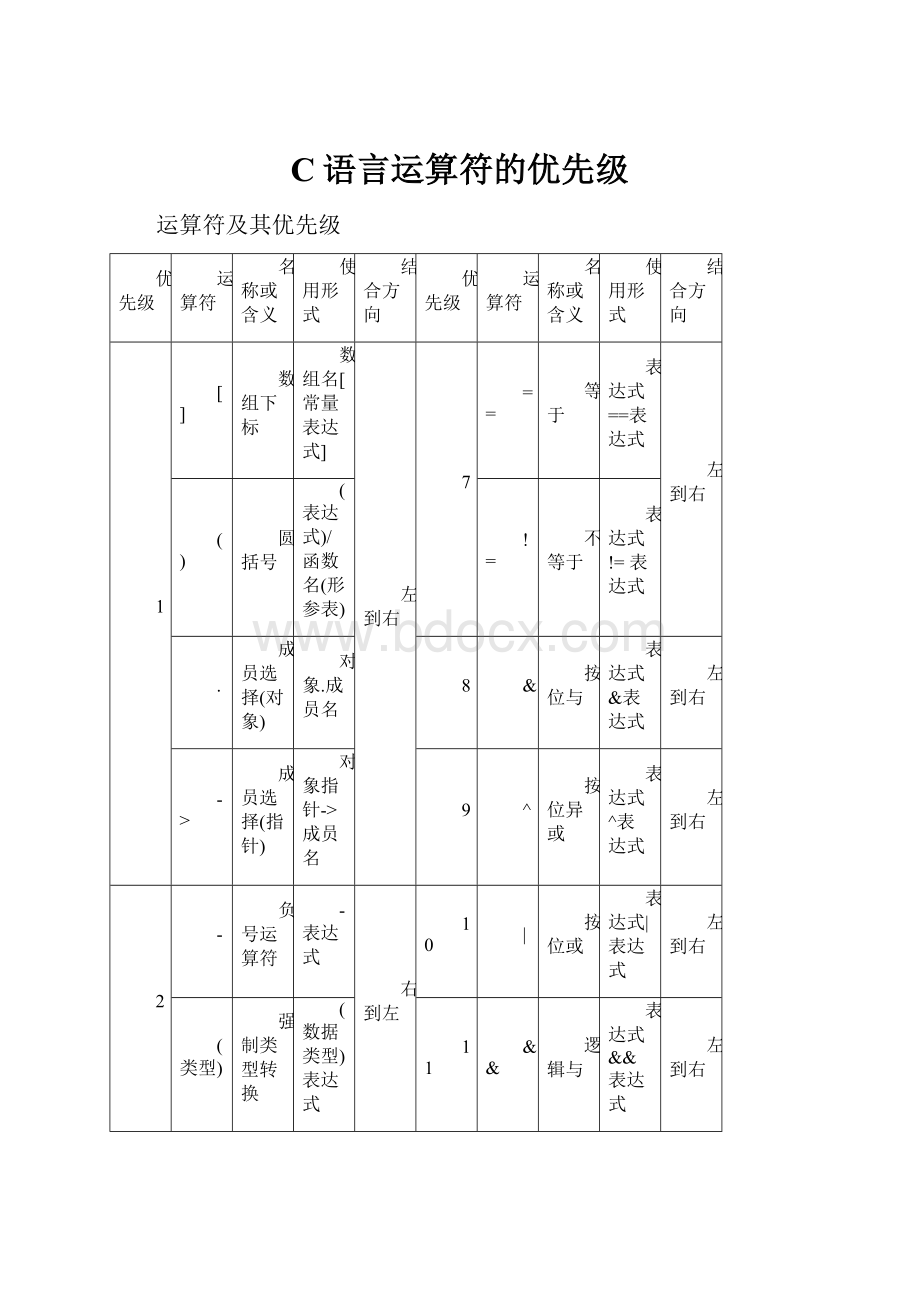
运算符及其优先级
优先级
运算符
名称或含义
使用形式
结合方向
优先级
运算符
名称或含义
使用形式
结合方向
1
[]
数组下标
数组名[常量表达式]
左到右
7
==
等于
表达式==表达式
左到右
()
圆括号
(表达式)/函数名(形参表)
!
=
不等于
表达式!
=表达式
.
成员选择(对象)
对象.成员名
8
&
按位与
表达式&表达式
左到右
->
成员选择(指针)
对象指针->成员名
9
^
按位异或
表达式^表达式
左到右
2
-
负号运算符
-表达式
右到左
10
|
按位或
表达式|表达式
左到右
(类型)
强制类型转换
(数据类型)表达式
11
&&
逻辑与
表达式&&表达式
左到右
++
自增运算符
++变量名/变量名++
12
||
逻辑或
表达式||表达式
左到右
--
自减运算符
--变量名/变量名--
13
?
:
条件运算符
表达式1?
表达式2:
表达式3
右到左
*
取值运算符
*指针变量
14
=
赋值运算符
变量=表达式
右到左
&
取地址运算符
&变量名
/=
除后赋值
变量/=表达式
!
逻辑非运算符
!
表达式
*=
乘后赋值
变量*=表达式
~
按位取反运算符
~表达式
%=
取模后赋值
变量%=表达式
sizeof
长度运算符
sizeof(表达式)
+=
加后赋值
变量+=表达式
3
/
除
表达式/表达式
左到右
-=
减后赋值
变量-=表达式
*
乘
表达式*表达式
<<=
左移后赋值
变量<<=表达式
%
余数(取模)
整型表达式/整型表达式
>>=
右移后赋值
变量>>=表达式
4
+
加
表达式+表达式
左到右
&=
按位与后赋值
变量&=表达式
-
减
表达式-表达式
^=
按位异或后赋值
变量^=表达式
5
<<
左移
变量<<表达式
左到右
|=
按位或后赋值
变量|=表达式
>>
右移
变量>>表达式
15
逗号运算符
表达式,表达式,…
左到右
6
>
大于
表达式>表达式
左到右
>=
大于等于
表达式>=表达式
<
小于
表达式<表达式
<=
小于等于
表达式<=表达式
数组和指针
一、指向一维数组元素的指针
inta[10],*p;
p=&a[0];/*与语句 p=a;等价*/
此时p指向数组中的第0号元素,即a[0],*p就是*a,就是a[0]的值,*(a+i)就是a[i]的值。
由于数组元素在内存中是连续存放的,根据地址运算规则,p+i和a+i都表示为a[i]的地址(即&a[i])。
二、二维数组元素的地址
为了说明问题,我们定义以下二维数组:
inta[3][4]={{0,1,2,3},{4,5,6,7},{8,9,10,11}};
二维数a也可这样来理解:
数组a由三个元素组成:
a[0],a[1],a[2],而每个元素又是一个一维数组,且都含有4个元素(相当于4列)。
如图所示:
______ _______________
a----|a[0]|----|0|1|2|3|------>(0x1000)
|______| |___|___|___|___|
|a[1]|----|4|5|6|7|------>(0x1010)
|______| |___|___|___|___|
|a[2]|----|8|9|10|11|------>(0x1020)
|______| |___|___|___|___|
但从二维数组的角度来看,a代表二维数组的首地址,当然也可看成是二维数组第0行的首地址,a+1就代表第1行的首地址,依次。
如果此二维数组的首地址为0x1000,由于第0行有4个整型元素,所以a+1为0x1010。
既然我们把a[0],a[1],a[2]看成是一维数组名,可以认为它们分别代表它们所对应的数组的首地址,也就是讲a[0]代表第0行中第0列元素的地址,即&a[0][0],a[1]是第1行中第0列元素的地址,即&a[1][0],根据地址运算规则,a[0]+1即代表第0行第1列元素的地址,即&a[0][1],一般而言,a[i]+j即代表第i行第j列元素的地址,即&a[i][j]。
另外,在二维数组中我们还可用指针的形式来表示各元素的地址,如a[0]与*(a+0)等价,a[i]与*(a+i)等价,它表示数组元素a[i]的地址&a[i][0]。
而二维数组元素a[i][j]可表示成*(a[i]+j)或*(*(a+i)+j),或者写成(*(a+i))[j]。
三、指向一个由n个元素所组成的数组指针
数组指针用的比较少,但在处理二维数组时,还是很方便的。
例如:
int (*p)[4]; /*在数组指针的定义中,圆括号是不能少的,否则它是指针数组*/
inta[3][4];
p=a;
开始时p指向二维数组第0行,当进行p+1运算时,根据地址运算规则,此时放大因子为4x4=16,所以此时正好指向二维数组的第1行。
和二维数组元素地址计算的规则一样,*p+1指向a[0][1],*(p+i)+j则指向数组元素a[i][j]。
四、指针数组
因为指针是变量,因此可设想用指向同一数据类型的指针来构成一个数组,这就是指针数组。
数组中的每个元素都是指针变量,根据数组的定义,指针数组中每个元素都为指向同一数据类型的指针。
格式:
类型标识 *数组名[整型常量表达式];
例如:
int *a[10];
以上指针数组中包含10个指针变量a[0],a[1],a[2],...,a[9],可以指向10个不同的地址。
指针函数和函数指针
一、指针函数
指针函数是指声明其返回值为一个指针的函数,实际上就是返回一个地址给调用函数。
格式:
类型说明符*函数名(参数)
例如:
void*GetDate(intID);
二、函数指针
指向函数的指针包含了函数的地址,可以通过它来调用函数。
格式:
类型说明符(*函数名)(参数)
例如:
int(*fptr)(intID);
其实这里不能称为函数名,应该叫做指针的变量名。
这个特殊的指针指向一个返回整型值的函数。
指针的声明笔削和它指向函数的声明保持一致。
指针名和指针运算符外面的括号改变了默认的运算符优先级。
如果没有圆括号,就变成了一个返回整型指针的函数的原型声明。
可以采用下面的形式定义函数指针数据类型:
typedefint(*T_MY_FUNC)(intID);/*此时”T_MY_FUNCfptr;”等价于”int(*fptr)(intID);”*/
可以采用下面的形式把函数的地址赋值给函数指针:
fptr=&Function;/*或用“fptr=Function;”*/
可以采用下面的形式通过指针来调用函数:
(*fptr)(ID);/*或用“fptr(ID);”的格式,使用这种调用格式看上去与调用普通函数无异,因此使用前一种调用格式可以明确指出是通过指针而非函数名来调用函数的。
*/
三、指针的指针
指针的指针用于指向指针的地址,它的声明有两个星号。
例如:
char**cp;
如果有三个星号,那就是指针的指针的指针,有四个星号那就是指针的指针的指针的指针,依次类推。
四、指向指针数组的指针
指针的指针另一用法是处理指针数组。
有些程序员喜欢用指针数组来代替多维数组,一个常见的用法就是处理字符串。
char*Names[]=
{
"Bill",
"Sam",
"Jim",
0
};
main()
{
char**nm=Names;/*定义一个指向指针数组的指针的指针*/
while(*nm!
=0)printf("%s\n",*nm++);
}
可变参数的函数
下面是一个简单的可变参数的函数,该函数至少有一个整数参数,第二个参数也是整数,是可选的。
#include
voidsimple_va_fun(inti,...)
{
va_listarg_ptr;
intj=0;
va_start(arg_ptr,i);/*va在这里是可变参数(variable-argument)的意思*/
j=va_arg(arg_ptr,int);
va_end(arg_ptr);
printf("%d%d\n",i,j);
return;
}
从这个函数的实现可以看到,使用可变参数应该有以下步骤:
1)#include
2)在函数里定义一个va_list型的变量,这里是arg_ptr,这个变量是指向参数的指针。
3)用va_start宏初始化变量arg_ptr,该宏的第二个参数是第一个可变参数的前一参数,是一固定的参数。
4)用va_arg返回可变的参数,并赋值给j。
va_arg的第二个参数是要返回的参数的类型,这里是int型。
5)最后用va_end宏结束可变参数的获取。
下面的例子可以进一步加深对可变参数的理解,该函数的效果与sprintf函数完全相同:
voidmy_printf(char*buffer,constchar*format,...)
{
va_listarg_ptr;
va_start(arg_ptr,format);
vsprintf(buffer,format,arg_ptr);/*将arg_ptr按format格式打印到buffer中*/
va_end(arg_ptr);
}
位域的使用
位域的定义和位域变量的说明与结构定义相仿,其形式例如为:
structbs
{
inta:
8;
intb:
2;
int:
2/*无位域名,该2bit不能使用*/
intc:
4;
};
对于位域的定义尚有以下几点说明:
1.一个位域必须存储在同一个字节中,不能跨两个字节。
如一个字节所剩空间不够存放另一位域时,应从下一单元起存放该位域。
也可以有意使某位域从下一单元开始。
2.由于位域不允许跨两个字节,因此位域的长度不能大于一个字节的长度,也就是说不能超过8位二进位。
3.位域可以无位域名,这时它只用来作填充或调整位置。
无名的位域是不能使用的。
链表
typedefstructstudent
{
intnumber;
intscore;
structstudent*next;
}STUDENT_LINK;
/**************建立一个有cnt个结点的链表,返回链表头****************/
STUDENT_LINK*link_creat(intcnt)
{
STUDENT_LINK*head=NULL;/*head始终指向链表头,用于返回*/
STUDENT_LINK*new_node;/*new_node始终指向新申请的节点*/
STUDENT_LINK*cur_node;/*cur_node始终指向当前操作的(也是最后的)节点*/
intn=1;
while(n<=cnt)
{
printf("您正在创建节点%d:
\n",n);
new_node=(STUDENT_LINK*)malloc(sizeof(STUDENT_LINK));
link_input(new_node);
if(n==1)/*判断是否为第一个结点,若是第1个结点则将head指向新节点*/
{
head=new_node;
}
else/*若不是第1个结点则将最后的节点的next指向新节点*/
{
cur_node->next=new_node;
}
cur_node=new_node;/*让cur_node始终指向当前的(也是最后的)节点*/
cur_node->next=NULL;/*不要忘记让最后的节点的next指向NULL*/
n++;
}
return(head);
}
/**********删除链表中number字段为num的结点,并返回链表头***************/
STUDENT_LINK*link_delete(STUDENT_LINK*head,intnum)
{
STUDENT_LINK*cur_node;/*cur_node始终指向当前操作的节点*/
STUDENT_LINK*pre_node;/*pre_node始终指向当前操作的节点的上一个节点*/
if(head==NULL)
{
printf("这个链表是空的,请先建立一个链表.\n");
return(head);
}
cur_node=head;
while(cur_node->number!
=num&&cur_node->next!
=NULL)/*当前节点不是要删除的也不是最后的节点*/
{
pre_node=cur_node;
cur_node=cur_node->next;/*将cur_node向后移一个结点*/
}
if(cur_node->number==num)/*在链表中找到了要删除的结点*/
{
if(cur_node==head)/*要删除的是头结点*/
{
head=cur_node->next;
}
else
{
pre_node->next=cur_node->next;
}
free(cur_node);
printf("学号为%d的节点已经从链表中删除.\n",num);
}
else/*在链表中没有找到要删除的结点*/
{
printf("您想要删除的结点不在此链表中.\n");
}
return(head);
}
/************插入一个新结点到链表的最后,并返回链表头***************/
STUDENT_LINK*link_insert(STUDENT_LINK*head,STUDENT_LINK*node)
{
STUDENT_LINK*cur_node;/*cur_node始终指向当前操作的节点*/
if(head==NULL)
{
head=node;
}
else
{
cur_node=head;
while(cur_node->next!
=NULL)
{
cur_node=cur_node->next;/*将cur_node向后移一个结点*/
}
cur_node->next=node;
}
node->next=NULL;/*不要忘记让最后的节点的next指向NULL*/
printf("这个节点已经插入当前链表的最后.\n");
return(head);
}
/**************用户输入一个节点****************/
voidlink_input(STUDENT_LINK*node)
{
……
}
/**************输出一个链表****************/
voidlink_output(STUDENT_LINK*head)
{
STUDENT_LINK*cur_node;
intcnt=0;
cur_node=head;
printf("ID\t学号\t\t分数\n");
while(cur_node!
=NULL)
{
printf("%d\t%d\t\t%d\n",++cnt,cur_node->number,cur_node->score);
cur_node=cur_node->next;
}
printf("合计有%d条记录\n",cnt);
}
/**************链表接口调用范例****************/
voidlink_main(void)
{
STUDENT_LINK*new_list=NULL;
STUDENT_LINKnew_stud;/*要插入的新结点*/
intcnt=5;
intnum=100;
new_list=link_creat(cnt);
printf("您创建的列表为:
\n");
link_output(new_list);
new_list=link_delete(new_list,num);
printf("删除结点后的列表为:
\n");
link_output(new_list);
link_input(&new_stud);
new_list=link_insert(new_list,&new_stud);
printf("插入新结点后的列表为:
\n");
link_output(new_list);
}
预处理
一、预处理过程和预处理指令
在C语言中,并没有任何内在的机制来完成如下一些功能:
在编译时包含其他源文件、定义宏、根据条件决定编译时是否包含某些代码,要完成这些工作,就需要使用预处理程序。
尽管在目前绝大多数编译器都包含了预处理程序,但通常认为它们是独立于编译器的。
预处理过程读入源代码,检查包含预处理指令的语句和宏定义,并对源代码进行响应的转换,预处理过程还会删除程序中的注释和多余的空白字符。
下面是部分预处理指令:
指令 用途指令 用途
# 空指令,无任何效果#include 包含一个源代码文件
#if 如果给定条件为真,则编译下面代码#define 定义宏
#ifdef 如果宏已经定义,则编译下面代码#undef 取消已定义的宏
#ifndef 如果宏没有定义,则编译下面代码
#elif 如果前面的#if给定条件不为真,且当前条件为真,则编译下面代码
#else如果前面的#if给定条件不为真,则编译#else下面的代码
#endif 结束一个#if……#else条件编译块
二、预定义的宏名
ANSI标准说明了五个预定义的宏名。
它们是:
LgvLinux联盟
__LINE__:
当前语句所在的行号LgvLinux联盟
__FILE__:
当前语句所在文件的文件名LgvLinux联盟
__DATE__:
该宏指令含有形式为"月日年"的串,表示源代码翻译到目标代码的日期LgvLinux联盟
LgvLinux联盟__TIME__:
该宏指令含有形式为"时:
分:
秒"的串,表示源代码翻译到目标代码的时间LgvLinux联盟
__STDC__:
如果实现是标准的,则该宏含有十进制常量1,如果它含有任何其它数,则表示实现是非标准的LgvLinux联盟
注:
如果编译不是标准的,则可能仅支持以上宏名中的几个,或都不支持,但也许还提供其它预定义的宏名。
三、#运算符
#的功能是将其后面的宏参数进行字符串化操作(Stringfication),简单说就是在对它所引用的宏变量通过替换后在其左右各加上一个双引号,有时把这种用法的#称为字符串化运算符。
比如:
#defineWARN_IF(EXP)\
if(EXP)\
fprintf(stderr,"Warning:
"#EXP".\n");
那么语句WARN_IF(divider==0)将被替换为:
if(divider==0)
fprintf(stderr,"Warning:
""divider==0"".\n");/*会打印出“Warning:
divider==0.”*/
再比如:
#define PASTE(n) "adhfkj"#n
printf("%s\n",PASTE(15));/*宏定义中的#运算符告诉预处理程序,把源代码中任何传递给该宏的参数转换成一个字符串。
所以输出应该是adhfkj15。
*/
四、##运算符
##被称为连接符(concatenator),##运算符用于把参数连接到一起。
预处理程序把出现在##两侧的参数合并成一个符号。
先看一个简单的例子:
#define NUM(a,b,c) a##b##c
#define STR(a,b,c) a##b##c/*##前后可以加空格*/
printf("%d\n",NUM(1,2,3));
printf("%s\n",STR("aa","bb","cc"));
最后程序的输出为:
123
aabbcc
再比如要做一个菜单项命令名和函数指针组成的结构体的数组,并且希望在函数名和菜单项命令名之间有直观的、名字上的关系,那么下面的代码就非常实用:
structcommand
{
char*name;/*菜单项命令名*/
void(*function)(void);/*命令名对应的函数指针*/
};
#defineCOMMAND(NAME){#NAME,NAME##_command}
structcommandmy_commands[]={
COMMAND(quit),/*相当于{"quit",quit_command}*/
COMMAND(help)/*相当于{"help",help_command}*/
};
五、#error指令
#error指令用于程序的调试,当编译中遇到#error指令就停止编译,并显示相应的出错信息。
#error命令的基本形式为:
#error出错信息
六、#line指令
命令#line主要用于调试及其它特殊应用,#line改变__LINE__与__FILE__的内容,它们是在编译程序中预先定义的标识符。
LgvLinux联盟
#line命令的基本形式为:
LgvLinux联盟#linenumber["filename"]LgvLinux联盟
其中的数字为任


- 配套讲稿:
如PPT文件的首页显示word图标,表示该PPT已包含配套word讲稿。双击word图标可打开word文档。
- 特殊限制:
部分文档作品中含有的国旗、国徽等图片,仅作为作品整体效果示例展示,禁止商用。设计者仅对作品中独创性部分享有著作权。
- 关 键 词:
- 语言 运算 优先级
 冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 《贝的故事》教案4.docx
《贝的故事》教案4.docx
-
《对韵歌》优秀教案8.docx
-
《函数yAsinωx+φ+P图象》wwwnet.docx
-
《静夜思》教学设计.docx
-
《汽车底盘构造与维修》题库与考核标准.docx
-
《世说新语》复习资料.docx
-
《我的服装我做主》教案设计.docx
-
《在品味情感中成长》教学片断设计.docx
-
11造价员《建设工程造价管理基础知识》精讲教程文件.docx
-
《不会叫的狗》教案 人教部编版1.docx
-
《操作系统》二学期A卷及答案.docx
-
《傅雷家书》名著阅读笔记.docx
-
《反不正当竞争法》下互联网平台封禁行为考辨以消费者用户合法权益保护为中心.docx
-
《化工原理》第六章蒸发.docx
-
《蓝海战略》概要11页.docx
-
《人生》读书心得.docx
-
《荷叶圆圆》公开课教案优秀教学设计26.docx
-
《科技出行研究报告》智能网联与新能源将变革未来汽车出行.docx
-
《272 向量的应用举例》导学案1.docx
-
《秋天》评课稿.docx
-
《电算化》第二章会计电算化的工作环境章节练习.docx
-
《室外给排水管道》施组.docx
-
《广东省建筑与装饰工程综合定额》计算规则.docx
-
《我多想去看看》教学.docx
-
《直通车车手基础认证》 考试答案 70题之欧阳育创编.docx
-
7天销量翻10倍皇冠卖家教您玩转最精准流量.docx
-
9 阿长和山海经.docx
-
《比例尺》教案.docx
-
《菜根谭》注译四闲适篇.docx
-
《福尔摩斯探案集》读后感15篇.docx
-
《红对勾》古代诗歌选择题答案补充.docx
-
《课堂密码》读后感及心得精选多篇.docx
-
鹫峰国家森林公园基础资料汇编.docx
-
地基钎探记录表13.docx
-
给朋友的国庆节快乐祝福语.docx
-
MAC高分子自粘胶膜防水卷材施工方案总结.docx
-
初三英语教学总结五篇.docx
-
部编教材语文二年级上册预习单.docx
-
汉方临床治验精粹.docx
-
动力源液压系统使用说明书.docx
-
参赛号码.docx
-
高级职称评定之专业技术工作总结建工类.docx
-
变压器的过负荷能力.docx
-
高考英语短文改错答题6步法附100道专项练习题+答案1.docx
-
四年级下《乘法交换律和结合律》教学设计.docx
-
公园一期工程安全文明施工方案.docx
-
精密测量技术课后答案.docx
-
湖北省安全员B证考题题库及答案.docx
-
绩效考核预拌商品混凝土搅拌站质量管理考评.docx
-
矿山事故隐患排查治理责任体系.docx
-
个人工作总结范文.docx
