 网页链接提取方法.docx
网页链接提取方法.docx
- 文档编号:28493191
- 上传时间:2023-07-15
- 格式:DOCX
- 页数:11
- 大小:2.80MB
网页链接提取方法.docx
《网页链接提取方法.docx》由会员分享,可在线阅读,更多相关《网页链接提取方法.docx(11页珍藏版)》请在冰豆网上搜索。
网页链接提取方法
网页提取方法
网页的提取是数据采集中非常重要的局部,当我们要采集列表页的数据时,除了列表标题的还有页码的,数据采集只采集一页是不够,还要从首页遍历到末页直到把所有的列表标题采集完,然后再用这些采集详情页的信息。
假设仅仅靠手工翻开网页源代码一个一个复制粘贴出来,太麻烦了。
掌握网页提取方法能让我们的工作事半功倍。
在进展数据采集的时候,我们可能有提取网页的需求。
网页提取一般有两种情况:
提取页面内的;提取当前页地址栏的。
针对这两种情况,八爪鱼采集器均有相关功能实现。
下面介绍一个网页提取方法。
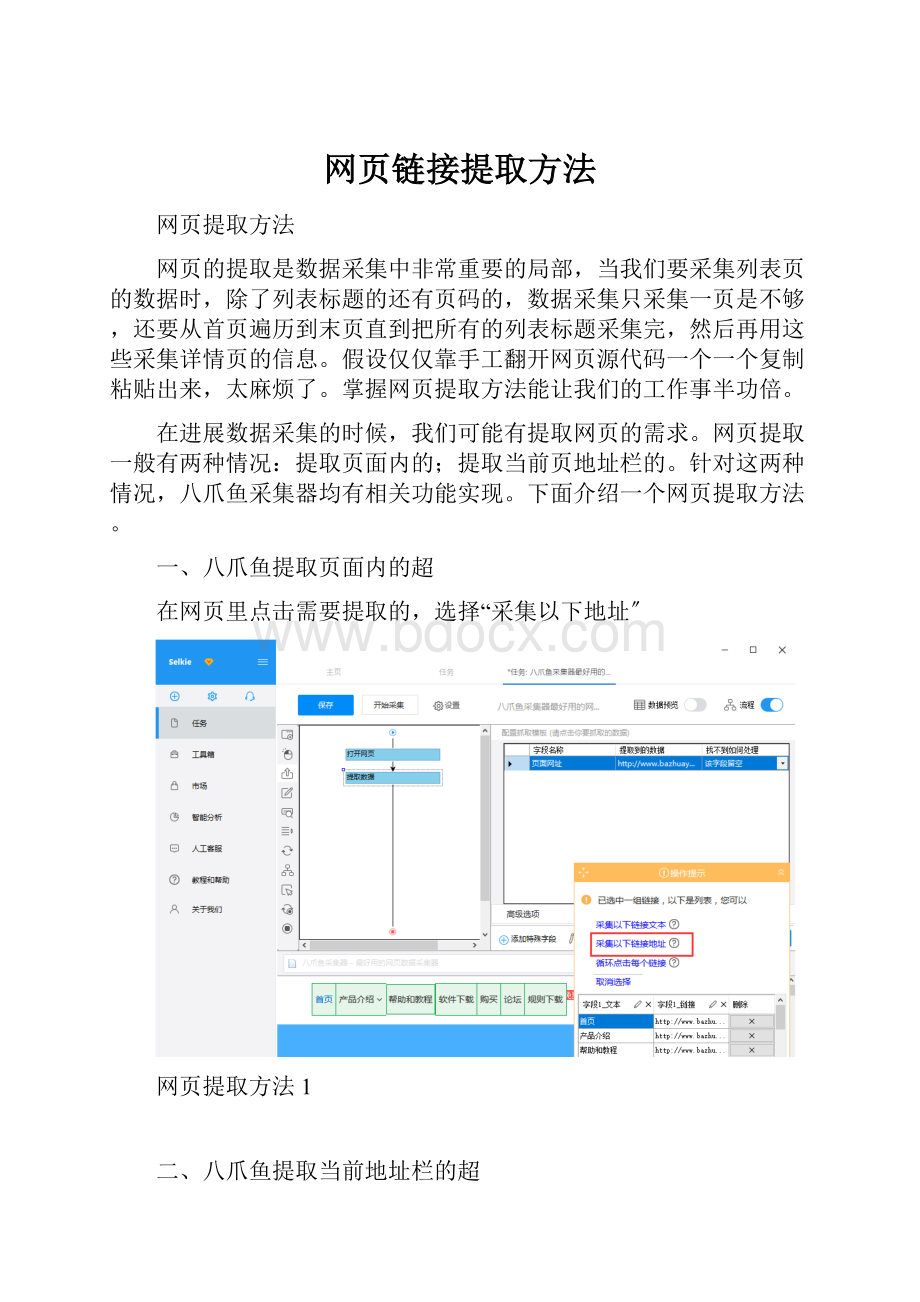
一、八爪鱼提取页面内的超
在网页里点击需要提取的,选择“采集以下地址〞
网页提取方法1
二、八爪鱼提取当前地址栏的超
从左边栏拖出一个提取数据的步骤出来〔如果当前页已经有其他的提取字段,这一步可省略〕
点击“添加特殊字段〞,选择“添加当前页面网址〞。
可以看到,当前地址栏的超被抓取下来
网页提取方法2
而批量提取网页的需求,一般是指批量提取页面内的超。
以下是一个使用八爪鱼批量提取页面内超的完整例如。
采集:
s:
//s.taobao./search?
initiative_id=tbindexz_20210918&ie=utf8&spm=a21bo.50862.202156-taobao-item.2&sourceId=tb.index&search_type=item&ssid=s5-e&mend=all&imgfile=&q=手表&suggest=history_1&_input_charset=utf-8&wq=&suggest_query=&source=suggest
步骤1:
c:
\iknow\docshare\data\cur_work\jingyan.baidu\article\javascript:
;创立采集任务
1)进入主界面,选择自定义模式
网页提取方法3
2〕将上面网址的网址复制粘贴到输入框中,点击“保存网址〞
网页提取方法4
3〕保存网址后,页面将在八爪鱼采集器中翻开,红色方框中的商品url
是这次演示采集的信息
网页提取方法5
步骤2:
c:
\iknow\docshare\data\cur_work\jingyan.baidu\article\javascript:
;创立翻页循环
1〕将页面下拉到底部,找到下一页按钮,鼠标点击,在右侧操作提示框中,
选择“循环点击下一页〞
网页提取方法6
步骤3:
商品url采集
1〕如图,移动鼠标选中列表中商品的名称,右键点击,需采集的内容会变成绿色,然后点击“选中全部〞
网页提取方法7
2〕选择“采集以下地址〞
网页提取方法8
3〕点击“保存并开场采集〞
网页提取方法9
4〕根据采集的情况选择适宜的采集方式,这里选择“启动本地采集〞
网页提取方法10
步骤4:
c:
\iknow\docshare\data\cur_work\jingyan.baidu\article\javascript:
;数据采集及导出
1〕选择适宜的导出方式,将采集好的数据导出
网页提取方法11
通过以上操作,目标网页内的商品超就被批量采集下来了。
我们可以使用这些超,建立列表循环,来采集我们需要的其他字段数据,如下所示。
步骤5:
创立url列表采集任务
1〕重新创立一个采集任务,将导出后的商品复制,放到输入框中,点击“保存网址〞
网页提取方法12
注意:
输入框中的url列表数量不要超过2W个,超过的局部可以新建任务进展采集,url翻开的页面必须是一样样式相近的,否那么会导致数据采集缺失。
2〕在页面中点击需要采集的文本数据,点击“采集数据〞
网页提取方法13
3〕翻开流程图,修改采集字段名称,点击“保存并开场采集〞
网页提取方法14
注意:
点击右上角的“流程〞按钮,即可展现出可视化流程图。
4〕采集完成,点击“导出数据〞
网页提取方法15
5〕选择适宜的导出方式,将采集好的数据导出
网页提取方法16
注:
在八爪鱼中,要提取超,需要满足两个条件。
1、点击的字段在A标签,在网页源码中,A标签代表超,如果不是在A标签内,八爪鱼无法判断
2、A标签内有href属性,href属性里的就是点击之后转向的地址,属性里显示什么,八爪鱼就提取什么。
如果没有href属性,自然就没方法提取到。
这些都是八爪鱼自动判断的,其实看不懂也不影响操作。
只是如果发现提取不到的时候,也许就是因为没满足这两个条件,要看当前网页源码的特点,根据特点找别的方式提取数据。
相关采集教程:
网页视频提取,以腾讯视频为例:
.bazhuayu./tutorial/txsp
网页数据爬取教程:
.bazhuayu./tutorial/hottutorial
电商爬虫:
.bazhuayu./tutorial/hottutorial/dianshang
淘宝数据采集:
.bazhuayu./tutorial/hottutorial/dianshang/taobao
京东爬虫:
.bazhuayu./tutorial/hottutorial/dianshang/jd
天猫爬虫:
.bazhuayu./tutorial/hottutorial/dianshang/tmall
阿里巴巴数据采集:
.bazhuayu./tutorial/hottutorial/dianshang/alibaba
亚马逊爬虫:
.bazhuayu./tutorial/hottutorial/dianshang/amazon
电商爬虫教程:
.bazhuayu./tutorial/hottutorial/dianshang/dsqita
金融数据采集:
.bazhuayu./tutorial/hottutorial/jrzx
八爪鱼——70万用户选择的网页数据采集器。
1、操作简单,任何人都可以用:
无需技术背景,会上网就能采集。
完全可视化流程,点击鼠标完成操作,2分钟即可快速入门。
2、功能强大,任何都可以采:
对于点击、登陆、翻页、识别验证码、瀑布流、Ajax脚本异步加载数据的网页,均可经过简单设置进展采集。
3、云采集,关机也可以。
配置好采集任务后可关机,任务可在云端执行。
庞大云采集集群24*7不连续运行,不用担忧IP被封,网络中断。
4、功能免费+增值效劳,可按需选择。
免费版具备所有功能,能够满足用户的根本采集需求。
同时设置了一些增值效劳〔如私有云〕,满足高端付费企业用户的需要。


- 配套讲稿:
如PPT文件的首页显示word图标,表示该PPT已包含配套word讲稿。双击word图标可打开word文档。
- 特殊限制:
部分文档作品中含有的国旗、国徽等图片,仅作为作品整体效果示例展示,禁止商用。设计者仅对作品中独创性部分享有著作权。
- 关 键 词:
- 网页 链接 提取 方法
 冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 #2机组现场施工用电布置措施.docx
#2机组现场施工用电布置措施.docx
-
《个人贵金属质押借款合同》兴业银行.docx
-
《科学发展观和小康社会的经济建设》复习导学案.docx
-
《我和祖父的园子》第一课时教案两篇word.docx
-
《质量》教学案例与设计.docx
-
2惠农小册子.docx
-
7A版个人与团队模拟考试题及答案.docx
-
10篇新部编四年级下册语文课内外阅读理解专项练习题及答案.docx
-
16初四物理热和能知识点总结精讲.docx
-
20XX社会语言经典语录流行风暴.docx
-
48篇教学案例分析报告题.docx
-
《电子工厂安全管理制度汇总》.docx
-
《机械制造课程设计》指导.docx
-
《钱学森》教案第二课时.docx
-
《边城》读后感5篇.docx
-
《固定式压力容器安全技术监察规程》.docx
-
《论雷峰塔的倒掉》.docx
-
《手术台就是阵地》教学设计三年级语文下册.docx
-
《夏洛的网》课外阅读教学设计.docx
-
《自己的花是让别人看的》教案.docx
-
3C检查表090429.docx
-
7客运专线CRTSⅡ型板式无砟轨道施工工法.docx
-
《笔算除法》课时教案设计.docx
-
11#楼高大模板支撑体系专项方案.docx
-
17科学分析经济形势.docx
-
《电流和电路》易错题精讲综合检测题与答案.docx
-
《会计信息系统》习题含答案.docx
-
《汽车电器设备与维修》发电机分教考分离试题及标准答案.docx
-
《四川省排污许可证管理暂行办法》.docx
-
《新编实用英语》教案第一册Unit.docx
-
0母版锅炉值班员计算题WORD版.docx
-
3年级下册英语单词记忆人教版.docx
-
关于给母校感谢信五篇Word格式.docx
-
关于想念情人恋人的唯美的句子Word文档下载推荐.docx
-
第一章药典概况Word文档格式.docx
-
基于Matlab和Arduino的智能循迹小车的设计Word下载.docx
-
发动机故障码大全Word格式.docx
-
基坑围护钢格构柱Word格式文档下载.docx
-
读零件图高职机械含答案文档格式.docx
-
当你困难的时候说说Word下载.docx
-
郭国庆第二版服务营销第二章文档格式.docx
-
电焊复习题Word文件下载.docx
-
肺结核病人适宜吃的食物Word文档下载推荐.docx
-
六年级篮球单元计划Word格式文档下载.docx
-
低碳减排 绿色生活致学生及家长的一封信Word下载.docx
-
基于DSP的无限冲击响应Word文档格式.docx
-
吉林公主岭市范家屯一中届高三模拟英语试题Word文档格式.docx
-
电路设计基础知识梳理之元器件Word文档格式.docx
-
关于基本医疗保险问题解释Word文档格式.docx
-
电站热力管网工程施工组织设计Word文档下载推荐.docx
-
高三年级阶段检测试题Word格式文档下载.docx
