 罗马尼亚问题.docx
罗马尼亚问题.docx
- 文档编号:25878401
- 上传时间:2023-06-16
- 格式:DOCX
- 页数:32
- 大小:755.72KB
罗马尼亚问题.docx
《罗马尼亚问题.docx》由会员分享,可在线阅读,更多相关《罗马尼亚问题.docx(32页珍藏版)》请在冰豆网上搜索。
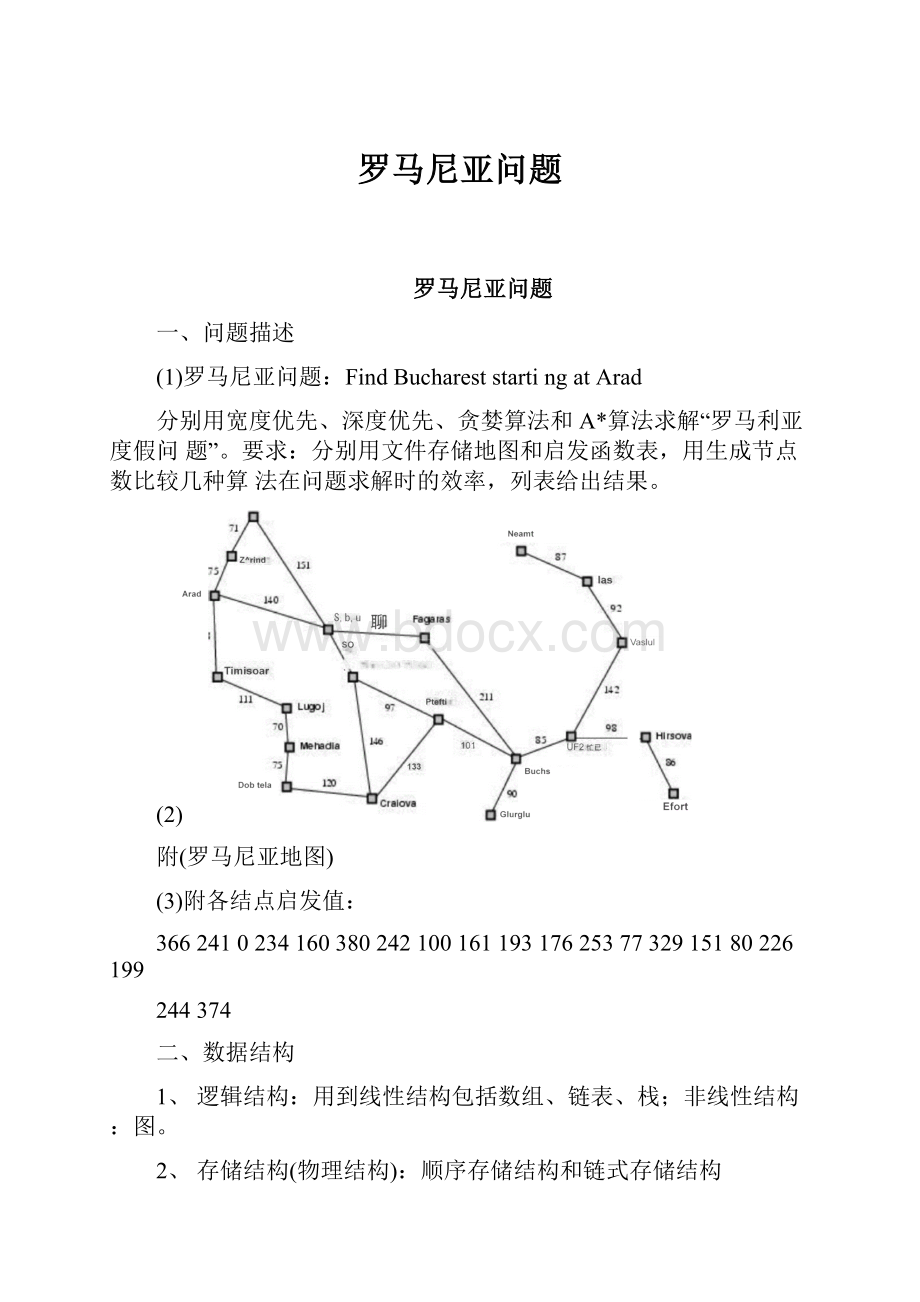
罗马尼亚问题
罗马尼亚问题
一、问题描述
(1)罗马尼亚问题:
FindBuchareststartingatArad
分别用宽度优先、深度优先、贪婪算法和A*算法求解“罗马利亚度假问题”。
要求:
分别用文件存储地图和启发函数表,用生成节点数比较几种算法在问题求解时的效率,列表给出结果。
(2)
附(罗马尼亚地图)
(3)附各结点启发值:
36624102341603802421001611931762537732915180226199
244374
二、数据结构
1、逻辑结构:
用到线性结构包括数组、链表、栈;非线性结构:
图。
2、存储结构(物理结构):
顺序存储结构和链式存储结构
(1)启发函数表采用顺序存储结构数组data[20].存储,从文件中读入:
for(n=0;n<20;n++)
{
fscanf(fp1,"%d",&data[n]);
}
⑵图采用二维数组map[]存储,从文件中读入:
for(i=0;i<20;i++)
{
for(j=0;j<20;j++)
{
fscanf(fp2,"%d",&map[i][j]);
}
(3)宽度优先的fringe表采用链式存储结构存储,且每一个结点为一个包含结点序号、h、g、f值等的结构体;
(4)深度优先的fringe表采用顺序栈存储,且每一个结点为一个包含结点序号、h、g、f值等的结构体;
(5)贪婪算法和A*算法采用结构体数组存储。
3、数据的运算:
抽象数据类型
(1)定义
typedefstructfringe
{
intstate;//存储点序号信息
intg;//g值
inth;//h值
intf;//f值
intk;〃标记是否已扩展
}FringeType;
(2)运算:
检索、插入、删除等运算
(3)表示:
每一个数据元素就是一个记录。
它包括学生的结点序号信息、g值、h
值、f值等数据项,在解决实际应用问题时把每个记录当作一个基本单位进行访问和处理。
三、算法思想
1、宽度优先
(1)算法描述:
从Arad结点出发,判断是否为目标结点,若否,宽度优先搜索系统地探寻与该结点相连的结点,算法首先搜索和Arad距离为k的所有顶点,然
后再去搜索和Arad距离为k+l的其他顶点,找出并存进待扩展结点表,等待扩展,每次先判断待扩展结点表是否为空,若否则从待扩展结点表中取出一个结点进行扩展,并将扩展后的结点存进该表,若是,则返回失败。
该算法同时能生成一棵根为Arad且包括所有可达顶点的宽度优先树。
宽度优先算法一直通过已找到和未找到顶点之间的边界向外扩展。
通过为每个顶点着色(白色、灰色和黑色)。
算法开始前所有顶点都是白色,随着搜索的进行,各顶点会逐渐被着色。
在搜索中第一次碰到,着灰色,然后是灰色。
因此,灰色和黑色顶点都已被发现,灰色顶点与一些白色顶点相邻接,它们代表着已找到和未找到顶点之间的边界。
在宽度优先搜索中,我用到单链表来存储待扩展结点表
(2)伪代码实现:
while(fringe[]!
=NULL)
takeoutu€fringe[]do
coloru;
while(u工goal)
do
expandu;
BFS
{
for(1-20循环)
{
if(有路径存在)
{
新生成结点;
BFSnode++;
}
}
取链表的第一个结点;
if(为goal)
{returnBFSnode;}elseif(不为goal)
{
BFS();//递归调用
}
returnBFSnode;}
putsuccessors
end;
end;
(3)算法评价:
宽度优先是完备的(如果分支因子有限的话),所以说,在任何情况下宽度优先都能找到一个解。
此外,最坏的情况是,当目标结点是第d层的最后一个被扩展的结点时。
时间复杂度:
厂_二,(b为分支因子,d为深度)
空间复杂度:
所存储的节点的个数。
2、深度优先
(1)算法描述:
深度优先搜索是一种每次都要达到被搜索结构的叶结点的搜索方法,直到不能
再深入为止,然后返回到另一个结点,继续对该结点进行深搜。
当有目标结点出现时,返回目标结点,搜索结束;否则,若待扩展结点表已空,且未找到目标结点,则返回失败,停止搜索。
同样,深度优先搜索从Arad结点出发,判断是否为目标结点,若否,探寻与该结点相连的结点,算法首先搜索一条分支上的所有顶点,然后再去搜索和Arad的其它分支结点,找出并存进待扩展结点表,等待扩展,每次先判断待扩展结点表是否为空,若否,则从待扩展结点表中取出一个结点进行扩展,并将扩展后的结点存进该表,若是,则返回失败。
该算法同时能生成一棵根为Arad且包括所有可达顶点的深度优先树。
在深度优先搜索中,我用到堆栈来存储待扩展结点表。
(2)伪代码实现
while(fringe[]!
=NULL)
takeoutu€fringe[]
do
coloru;
while(u工goal)
do
expandu;
DFS()
{
for(1-20循环)
{
if(有路径存在)
{
新生成结点;
DFSnode++;
}
}
出堆栈;
if(是目标结点)
{
returnDFSnode;}
else
{
DFS();//递归调用
}
returnDFSnode;
}
putsuccessors(DFS)infringe[];
end;
end;
(3)算法评价:
不是完备的(除非查找空间是有限的)。
同时,也不能找到最优解。
时间复杂度:
厂、
空间复杂度:
!
"^(b为分支因子,m为深度,仅有一枝需要存储)
3、贪婪算法
(1)算法描述:
贪婪算法是指,在对问题求解时,总是做出在当前看来是最好的选择。
贪婪算法不从整体最优上加以考虑,所做出的仅是在某种意义上的局部最优解。
贪婪
算法不是对所有问题都能得到整体最优解,但对范围相当广泛的许多问题他能产生整体最优解或者是整体最优解的近似解。
在解决罗马尼亚度假问题时,贪婪算法通过比较每个待扩展结点的h值,即启
发函数生成的到目标结点的启发函数值,选取一个最小的,来确定当前要扩展的结点,并将生成的结点放进fringe结点表。
在贪婪算法中,我用到结构体数组存储待扩展结点表。
(2)伪代码实现:
while(fringe[]!
=NULL)
takeoutu€fringe[]
do
coloru;
while(u丰goal)
do
expandu;
greedy()
{for(1-20循环)
{
if(有路径)
{
新生成结点
GNode++;
}
}
for(循环)
{
if(比较h值大小)
{
找出最小的h值结点;
}
}if(离目标的实际值!
=0)
{
greedy();//递归调用
}
returnGNode;//生成结点数
}
putsuccessors(greedy)infringe[];
end;
end;
(3)算法评价
不是完备的。
同时,找到的解也不一定是最优解。
时间复杂度:
^一(b代表分支数,m为深度)
空间复杂度:
㈠一)
4、A*算法
(1)算法描述:
A*算法用公式表示为:
f(n)=g(n)+h(n),其中f(n)是从初始点经由结
点n到目标点的估价函数;g(n)是在状态空间中从初始节点到n节点的实
际代价,h(n)是从n到目标节点最佳路径的估计代价。
A*能找到最优解的条件,关键在于估价函数h(n)的选取;若估价值<
实际值,则能保证得到最优解。
(2)伪代码实现:
while(fringe[]!
=NULL)
takeoutu€fringe[]
do
coloru;
while(u工goal)
do
expandu;
Astar()
{
for(循环)
{
if(有路径存在0)
{
新生成结点;
ASNode++;
}
}
for(循环)
{
if(f值比min小)
{
找出最f值最小的结点扩展;
}
}
for(循环)
{
if(为目标结点)
{
returnASNode;
}
}
Sstar();//递归调用
returnASNode;
}
putsuccessors(Astar)infringe[];
end;
end;
(3)算法评价:
完备的,能够找到最优解;时间复杂度:
扩展节点的数目;空间复杂度:
所有生成的结点。
四、运行结果:
宽度优先、深度优先、贪婪算法、A*算法:
五、比较结论:
通过比较,DFS和Greedy搜索生成的结点数目最少,为9个,效率最
高;BFS生成的结点数目最多,为19个,效率最低。
但是DFS、BFS和
Greedy搜索找到的都不一定最优解,只有A*算法具有完备性且始终找到的
都是最优解。
宽度优先虽然是完备的(如果分支因子有限的话),在任何情况下宽度优先都能找到一个解,但是,它找到的第一个解并非最优的,此外,最坏的情况是,当目标结点是第d层的最后一个被扩展的结点时,它将耗费大量的时
间。
宽度优先时间复杂度—一"一-二n(b为分支因子,d为深度);空间复杂度为所存储的节点的个数。
DFS不是完备的(除非查
找空间是有限的),同时,它也不能找到最优解。
深度优先的时间复杂度:
';
空间复杂度:
。
(加+1)(b为分支因子,m为深度,仅有一枝需要存储)。
贪婪算法不是完备的。
同时,它找到的解也不一定是最优解。
其时间复杂度:
更
(b代表分支数,m为深度);空间复杂度为空二L)。
所以只有A*算法是完备的,且能够找到最优解;其时间复杂度:
扩展节点的数目;空间复杂度:
所有生成的结点。
综合来看,DFS和贪婪算法的效率较高,但解并非最优,而A*算法的效率稍逊色,但解为最优;而BFS搜索则效率最低,且不一定为最优解。
n皇后问题
一、问题描述:
(1)n皇后问题:
在n*n格的国际象棋上摆放n个皇后,使其不能互相攻击,即任意两个皇后都不能处于同一行、同一列或同一斜线上,
(2)分别用回溯法(递归)、爬山法和GA算法求解n皇后问题。
要求:
输入n,并用运行时间比较几种算法在相同规模的问题时的求解效率。
列表给出结果。
二、数据结构
1、逻辑结构:
用到线性结构包括数组queenList[col]等。
2、存储结构(物理结构):
顺序存储结构。
3、数据的运算:
(1)表示:
(queenList[col],col)表示(row,col)的皇后
(2)运算:
检索、插入、删除等运算
三、算法思想:
1、回溯法
(1)算法描述:
回溯法是一种选优搜索法,按选优条件向前搜索,以达到目标。
但当探索到某一步时,发现原先选择并不优或达不到目标,就退回一步重新选择,这种走不通就退回再走的技术为回溯法。
(2)伪代码实现:
基本思想是:
从一条路往前走,能进则进,不能进则退回来,换一条路
再试。
对于n皇后问题,第一步按照顺序放一个皇后,然后第二步符合要
求放第2个皇后,如果没有符合位置符合要求,那么就要改变第一个皇后
的位置,重新放第2个皇后的位置,直到找到符合条件的位置就可以了,
在目标状态终止。
(3)算法评价
回溯法在皇后数目较小的,很占优势,它的速度非常的快,但随着皇后数目的增加,回溯法显得很不实用,在n=28时,用回溯法已不能较好的解
决n皇后问题。
2、爬山法
(1)算法描述:
爬山法是指从当前的节点开始,和周围的邻居节点的值进行比较。
如果当
前节点是最大的,那么返回当前节点,作为最大值(既山峰最高点);反之就用最高的邻居节点来,替换当前节点,从而实现向山峰的高处攀爬的目的。
如此循环直到达到最高点。
每次都选择是与目标结点启发函数值最小的那个结点,经过迂回前进,最终达
到解决问题的总目标。
如果我们把目标函数的几何图形看成一个山峰,那么点的
直接移动就像人在爬山,选择方向,逐步向山顶移动。
爬山法需要建立一个描述数据库变化的单极值函数,且使极值对应目标状态;选取使函数值增长最大的那条规则作用于数据库;重复上步,直到没有规则使函数值继续增长。
爬山法是一种局部搜索算法,也属一种启发式方法。
但它一般只能得到局部最优,并且这种解还依赖于起始点的选取。
它是一种解多变量无约束最优化问题的一类方法,通过点的直接移动产生的目标值有所改善的点,经过这样的移动,逐
步到达使目标函数最优的点。
在爬山法中,h表示相互攻击的皇后的对数,用它来生成启发函数。
(2)伪代码实现:
爬山函数(问题)是局部极大值的一种状态返回
输入问题,一个问题
局部变量:
当前,一个节点。
邻居,一个节点。
当前生成节点(初始状态[问题])
循环做
邻居一个价值最高当前的继任者
如果值[邻居]W价值[当前],然后返回状态[当前]
当前邻居
(3)算法评价
爬山法的缺点:
会出现山脊、高原,86%的时间会卡住;但是爬山算法较简单,在皇后的个数较多时体现出来效率最高,处理多约束大规模问题时往往不能得到较好的解。
3、遗传算法
(1)算法描述:
遗传算法(GeneticAlgorithm)是模拟物进化论的自然选择和遗传学机理的生物进化过程的计算模型,是一种通过模拟自然进化过程搜索最优解的方法。
对于一个求函数最大值的优化问题,首先初始化,包括种群的大小,编码的方案,遗传的代数,变异的概率,等等;然后进行选择操作;接着是将选择的个体进行交叉;然后再进行选择,并将选择的个体进行变异;最后就是更新最优值了。
(2)伪代码实现:
函数GA(总群,最适合的FN)返回一个个体
输入:
人口,个体
最适合的FN,—个函数,它决定了个体素质循环
新—种群「空的集合
从1到大小(人口)做i次
X随机选择(人口,最适合的FN)
丫随机选择(人口,最适合的FN)
孩子再生(X,丫)
(随机概率小),那么孩子变异(孩子)
孩子添加到新—种群
人口「新—种群
直到有个体适合足够或足够的时间耗完返回最佳个体
大概分为:
初始化、选择运算、不停的交叉运算、终止计算。
(3)算法评价
遗传算法优点是能很好的处理约束,能很好的跳出局部最优,最终得到全局最优解,全局搜索能力强;缺点是收敛较慢,局部搜索能力较弱,运行时间长,且容易受参数的影响。
四、运行结果:
n=10时;
1、回溯法:
请输入呈后的个数:
m
4E
4F
4f-
*
«■
-ME-
*
■w
q
*
*
-Mr
M-
*
*
■w
*
Mr
w-
W
tW
w
*
*
*
*
寵
4E-
w-
q
*-
«■
*
*
*
M-
*
*
q
*
<1
-it
普
*
*
*
*
*
*
-H-
*
总共用时为土
秒
2、爬山法
3、遗传算法:
请输入星后个数:
10
:
*****务g*总共用吋为:
1-406000秒
n=20时;
1、回溯法:
请输入皇后的个数|刑
□
«-
«-«■
*
ee
*
*
*
*
*
#
*
*
*
*E-
K
«■
«■
M
g*
*
*
*
*
共
M
M
Mr
-K-
*7
"Nr
44
*
q
w-
Hfr
it
ft
M
M
<
蕃
w-
*
*
«7
*Q
■M"
*
*
*
M
M
*
-M-
*
*
*
«E
■Mr
«>
■
**
44
M>
共
<
<
K
*
*
«
«
*
*
*
w*
#
«E
W
*
«F
q
*
*
*
*41-
■M
M-
#E
無
-H-
q
*
*
w
«W
*
菁
it
W
«r
普
W
q
*
・
W
«
*
«F
«■开
■M"
*
*
*
M
9
*
*
9f
*
-M-
*
"Mr
#
MM
»
*
*
*
4>t
q
4t
»
*
*
M
*M
M
#
M
M
M
餐
w
w
w
«
*
*
Mr
*4e
■M"
*
q
M
-M-
*
*
*
-M-
注
*
Mr
M
««
餐
餐
餐
Mr
«-
w
«
«
*
*
*
4F*
-M-
if
HE
普
it
ie
w
*
*
q
W
*
*
**
q
*
共
*
*
*
-se
*
*
*
It
*
Mr
"W
W
#
«e
(1
«e
w
■
H
w
*
*
*
*
4F
*
共
q
*
*
*
*
*
*
*
*
*M
*
*
q
*
*
»
w
w
■w
#
it
*
*
-Hr
M
»
M
M
*
M-
*
«r
群
普
w
M
*
*
*4t
-M"
*
*
q
*
■M-
*
*
*
*
*
总共用时划fl.750B00秒
2、爬山法
(I
M-
>WA呈后的
*務務
n数;
20
*
#
■W
**
*
it
w
#44
*
*
■
*
*
(I
*
*
■M"
*
*
*
*
**
*
*
*
-M-
«E
*
«-
*
q
餐
*
餐4*
*
*
4t
«
M
W
*
瞬
■M"
#
*
-K-
衽
瞬
*
»
M"
*■
«■
*
*M
*e
■#E
d*
it
*lr
(I
池
*
h
H
*em
*
Mr
M
*
w
q
w
*
*
*
*
*
*
*
<1
*
«-
«■
聲
M-
M
■M
*
*
■M"
*
葺
-K
■*
-H-
q
*
*
*
*
«■
#
■it
務
*«
«■
*
«■
ft
q
W
*
MM
M
M
W
iM
W
W
»
»
盖
*
*
*
*
q
*
*
*
*
*
*
*e
«E-
«■
«■
M
4t
餐
44-
M
■M
*
*
#
*
*
q
*
-fet
-H-
社
*
*
*
*
«t
■W
«■
*
*e
It
«■
J*
普
<
»
*
*
*4
«
«
«
»
»
*
*
*
*
*
«■
q
**
«■
*
*
*
-M-
«■
«r
前£
4*4*44
**帝
0.640000
1
q*
-K
Q
*
■M
*
*
4f-
3、遗传算法:
请输入星后个数:
20
*
*
*
*
*
*
*
*
*
*
-M-
*
*
-M
q
-M-
*
*
*
«■
■Mr
at
■M-
#
#-
*
兴
■K
M-
*
*
M
W
M*
<1
W
菁
»
«
M
菁
*
W
W
*
*
■W
■w
q
*
畫
*
*
*
■W
4E
*
-M
*
■w
*
*
■M-
*
*
池
*
-M-
■M-
■M-
*
*
q
*
«
斗
餐
Mr
*
Q
«b
M
w-
w
w
W
Mr
W
w-
q
#
w
W
44
*
#
*
4f-
«e
*
*
#
背
*
社
-K
*F
*
-M-
-M-
*
«■
■W
«■
*
*
«
*
q
*
4E-
*
*
W
*
-M-
-M-
*
铢
M-
-W
-M-
#
*
4*
q
M
*
«
W
«
q
4»
4
M
*
*
M
*
w
q
科
it
#
幵
*
*F
幵
«
*
*
*
*
*
*
*
*
*
*
*
*
q
-M
44


- 配套讲稿:
如PPT文件的首页显示word图标,表示该PPT已包含配套word讲稿。双击word图标可打开word文档。
- 特殊限制:
部分文档作品中含有的国旗、国徽等图片,仅作为作品整体效果示例展示,禁止商用。设计者仅对作品中独创性部分享有著作权。
- 关 键 词:
- 罗马尼亚 问题
 冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 《 岁婴幼儿教养方案》.docx
《 岁婴幼儿教养方案》.docx
-
《分数混合运算》导学案模板.docx
-
《管理学概论》案例分析作业48122第8组.docx
-
《全职高手》手游每日答题答案162题.docx
-
《手影游戏》教案.docx
-
《夏洛的网》读书笔记15篇.docx
-
《《宝莱坞生死恋》观后感》.docx
-
《父亲的病》读后感.docx
-
《仙人掌》大班教案.docx
-
《浙江省建筑业企业资质管理实施办法》.docx
-
1一年级看图写话图片.docx
-
3汽车整车气动声学风洞风噪试验车内风噪测量方法0330报批稿1.docx
-
《北师大资深教授顾明远做主题发言》.docx
-
《第27届飞天奖颁奖词》.docx
-
《悲惨世界》读书心得范文.docx
-
《登革热演练方案》.docx
-
《怀孕40周每周详解》最新完整版.docx
-
《建设工程施工管理》真题及答案.docx
-
《雷雨》教案1.docx
-
《模具制造工》培训大纲.docx
-
《社区医疗活动方案》.docx
-
《首届诺贝尔奖颁发》教案.docx
-
《移动通信技术》实验教学大纲186教学文案.docx
-
1纤维的种类特性性能.docx
-
3口腔执业医师综合笔试习题.docx
-
4章制药习地训练题目.docx
-
8中医养生保健技术规范穴位贴敷.docx
-
20种空调常见故障判断与维修.docx
-
201X年暑假机关会计社会实践报告.docx
-
500td光伏污水处理改造工程设计方案.docx
-
APP管理端概述说明.docx
-
《保护心脏》第二课时教学设计.docx
-
双语班三年级汉语上册第10课教案.docx
-
开展巾帼建功系列活动总结汇报精选多篇.docx
-
仁爱英语九年级上下册unit 3topic3汇编.docx
-
人工挖孔桩监理细则.docx
-
三元催化器清洗.docx
-
色彩解构在服装色彩搭配中的运用研究.docx
-
税务职业规划书.docx
-
抗菌药物的临床应用试题及答案.docx
-
手机计算器ti89圆弧段放样测量程序.docx
-
三年级下册《面积的含义》说课.docx
-
双语班三年级汉语上册第10课教案.docx
-
抗菌药物的临床应用试题及答案.docx
-
人教版八年级数学上册分式方程专项练习题50.docx
-
三年级上同步阅读1.docx
-
山东大学qpsk monte carlo 仿真实验报告DOC.docx
-
四川省二级注册建造师继续教育管理暂行办法.docx
-
客户关系管理案例库.docx
-
人教版思品七下《防患于未然》同步测试.docx
-
山东人民出版社小学四年级品德与社会上册教案.docx
