 hanlp中文分词器解读.docx
hanlp中文分词器解读.docx
- 文档编号:25191858
- 上传时间:2023-06-06
- 格式:DOCX
- 页数:94
- 大小:2.81MB
hanlp中文分词器解读.docx
《hanlp中文分词器解读.docx》由会员分享,可在线阅读,更多相关《hanlp中文分词器解读.docx(94页珍藏版)》请在冰豆网上搜索。
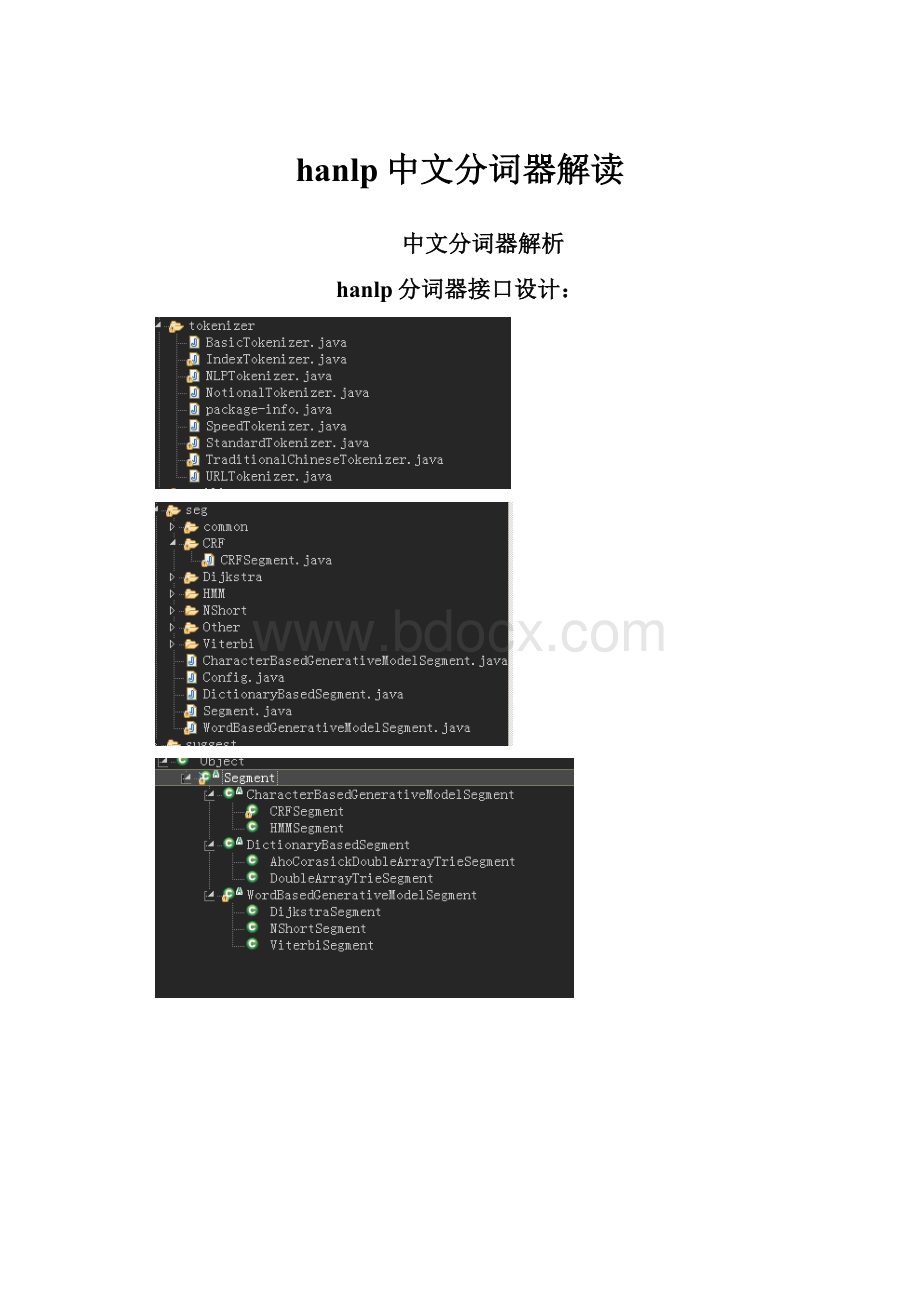
hanlp中文分词器解读
中文分词器解析
hanlp分词器接口设计:
提供外部接口:
分词器封装为静态工具类,并提供了简单的接口
标准分词
标准分词是最常用的分词器,基于HMM-Viterbi实现,开启了中国人名识别和音译人名识别,调用方法如下:
List
System.out.println(termList);
∙HanLP.segment 其实是对 StandardTokenizer.segment 的包装。
/**
*分词
*
*@paramtext文本
*@return切分后的单词
*/
publicstaticList
{
returnStandardTokenizer.segment(text.toCharArray());
}
/**
*创建一个分词器
*这是一个工厂方法
*与直接new一个分词器相比,使用本方法的好处是,以后HanLP升级了,总能用上最合适的分词器
*@return一个分词器
*/
publicstaticSegmentnewSegment()
{
returnnewViterbiSegment();//Viterbi分词器是目前效率和效果的最佳平衡
}
publicclassStandardTokenizer
{
/**
*预置分词器
*/
publicstaticfinalSegmentSEGMENT=HanLP.newSegment();
/**
*分词
*@paramtext文本
*@return分词结果
*/
publicstaticList
{
returnSEGMENT.seg(text.toCharArray());
}
/**
*分词
*@paramtext文本
*@return分词结果
*/
publicstaticList
{
returnSEGMENT.seg(text);
}
/**
*切分为句子形式
*@paramtext文本
*@return句子列表
*/
publicstaticList
{
returnSEGMENT.seg2sentence(text);
}
}
publicstaticSegmentnewSegment()
{
returnnewViterbiSegment();//Viterbi分词器是目前效率和效果的最佳平衡
}
/**
*Viterbi分词器
*也是最短路分词,最短路求解采用Viterbi算法
*
*@authorhankcs
*/
publicclassViterbiSegmentextendsWordBasedGenerativeModelSegment
NLP分词
NLP分词 NLPTokenizer 会执行全部命名实体识别和词性标注。
,调用方法如下:
List
System.out.println(termList);
∙NLP分词 NLPTokenizer 会执行全部命名实体识别和词性标注。
∙所以速度比标准分词慢,并且有误识别的情况。
publicclassNLPTokenizer
{
/**
*预置分词器
*/
publicstaticfinalSegmentSEGMENT=HanLP.newSegment().enableNameRecognize(true).enableTranslatedNameRecognize(true).enableJapaneseNameRecognize(true).enablePlaceRecognize(true).enableOrganizationRecognize(true).enablePartOfSpeechTagging(true);
publicstaticList
{
returnSEGMENT.seg(text);
}
/**
*分词
*@paramtext文本
*@return分词结果
*/
publicstaticList
{
returnSEGMENT.seg(text);
}
/**
*切分为句子形式
*@paramtext文本
*@return句子列表
*/
publicstaticList
{
returnSEGMENT.seg2sentence(text);
}
}
索引分词
索引分词 IndexTokenizer 是面向搜索引擎的分词器,能够对长词全切分,另外通过 term.offset 可以获取单词在文本中的偏移量。
调用方法如下:
List
for(Termterm:
termList)
{
System.out.println(term+"["+term.offset+":
"+(term.offset+term.word.length())+"]");
}
publicclassIndexTokenizer
{
/**
*预置分词器
*/
publicstaticfinalSegmentSEGMENT=HanLP.newSegment().enableIndexMode(true);
publicstaticList
{
returnSEGMENT.seg(text);
}
/**
*分词
*@paramtext文本
*@return分词结果
*/
publicstaticList
{
returnSEGMENT.seg(text);
}
/**
*切分为句子形式
*@paramtext文本
*@return句子列表
*/
publicstaticList
{
returnSEGMENT.seg2sentence(text);
}
}
繁体分词
繁体分词 TraditionalChineseTokenizer 可以直接对繁体进行分词,输出切分后的繁体词语。
调用方法如下:
List
");
System.out.println(termList);
/**
*繁体中文分词器
*
*@authorhankcs
*/
publicclassTraditionalChineseTokenizer
{
/**
*预置分词器
*/
publicstaticSegmentSEGMENT=HanLP.newSegment();
privatestaticList
{
if(text.length()==0)returnCollections.emptyList();
LinkedList
StringBuildersbSimplifiedChinese=newStringBuilder(text.length());
booleanequal=true;
for(ResultTerm
tsList)
{
if(term.label==null)term.label=term.word;
elseif(term.label.length()!
=term.word.length())equal=false;
sbSimplifiedChinese.append(term.label);
}
StringsimplifiedChinese=sbSimplifiedChinese.toString();
List
if(equal)
{
intoffset=0;
for(Termterm:
termList)
{
term.word=text.substring(offset,offset+term.length());
term.offset=offset;
offset+=term.length();
}
}
else
{
Iterator
Iterator
ResultTerm
intoffset=0;
while(termIterator.hasNext())
{
Termterm=termIterator.next();
term.offset=offset;
if(offset>tsTerm.offset+tsTerm.word.length())tsTerm=tsIterator.next();
if(offset==tsTerm.offset&&term.length()==tsTerm.label.length())
{
term.word=tsTerm.word;
}
elseterm.word=SimplifiedChineseDictionary.convertToTraditionalChinese(term.word);
offset+=term.length();
}
}
returntermList;
}
publicstaticList
{
List
for(Stringsentence:
SentencesUtil.toSentenceList(text))
{
termList.addAll(segSentence(sentence));
}
returntermList;
}
/**
*分词
*
*@paramtext文本
*@return分词结果
*/
publicstaticList
{
returnsegment(CharTable.convert(text));
}
/**
*切分为句子形式
*
*@paramtext文本
*@return句子列表
*/
publicstaticList
{
List
{
for(Stringsentence:
SentencesUtil.toSentenceList(text))
{
resultList.add(segment(sentence));
}
}
returnresultList;
}
}
极速词典分词
极速分词是词典最长分词,速度极其快,精度一般。
调用方法如下:
Stringtext="江西鄱阳湖干枯,中国最大淡水湖变成大草原";
System.out.println(SpeedTokenizer.segment(text));
longstart=System.currentTimeMillis();
intpressure=1000000;
for(inti=0;i { SpeedTokenizer.segment(text); } doublecostTime=(System.currentTimeMillis()-start)/(double)1000; System.out.printf("分词速度: %.2f字每秒",text.length()*pressure/costTime); ∙在i7上跑出了2000万字每秒的速度。 ∙使用的算法是 《AhoCorasick自动机结合DoubleArrayTrie极速多模式匹配》 /** *极速分词,基于DoubleArrayTrie实现的词典分词,适用于“高吞吐量”“精度一般”的场合 *@authorhankcs */ publicclassSpeedTokenizer { /** *预置分词器 */ publicstaticfinalSegmentSEGMENT=newDoubleArrayTrieSegment(); publicstaticList { returnSEGMENT.seg(text.toCharArray()); } /** *分词 *@paramtext文本 *@return分词结果 */ publicstaticList { returnSEGMENT.seg(text); } /** *切分为句子形式 *@paramtext文本 *@return句子列表 */ publicstaticList { returnSEGMENT.seg2sentence(text); } } 接下来介绍的分词器是由用户动态创建,使用场景不常见的分词器。 N-最短路径分词 N最短路分词器 NShortSegment 比最短路分词器( DijkstraSegment )慢,但是效果稍微好一些,对命名实体识别能力更强。 调用方法如下: SegmentnShortSegment=newNShortSegment().enableCustomDictionary(false).enablePlaceRecognize(true).enableOrganizationRecognize(true); SegmentshortestSegment=newViterbiSegment().enableCustomDictionary(false).enablePlaceRecognize(true).enableOrganizationRecognize(true); String[]testCase=newString[]{ "刘喜杰石国祥会见吴亚琴先进事迹报告团成员", }; for(Stringsentence: testCase) { System.out.println("N-最短分词: "+nShortSegment.seg(sentence)+"\n最短路分词: "+shortestSegment.seg(sentence)); } ∙一般场景下最短路分词的精度已经足够,而且速度比N最短路分词器快几倍,请酌情选择。 /** *N最短分词器 * *@authorhankcs */ publicclassNShortSegmentextendsWordBasedGenerativeModelSegment /** *最短路径分词 *@authorhankcs */ publicclassDijkstraSegmentextendsWordBasedGenerativeModelSegment { CRF分词 基于CRF模型和BEMS标注训练得到的分词器。 调用方法如下: Segmentsegment=newCRFSegment(); segment.enablePartOfSpeechTagging(true); List System.out.println(termList); for(Termterm: termList) { if(term.nature==null) { System.out.println("识别到新词: "+term.word); } } publicclassCRFSegmentextendsCharacterBasedGenerativeModelSegment 动态创建和配置 在上面的例子中,一些工具类包装了配置好的分词器。 HanLP同时支持用户动态创建分词器和配置分词器。 创建分词器 既可以用new创建,也可以用工具类创建,推荐后者,可以应对未来的版本升级。 通过new关键字 分词器是Java对象,可以用传统的new关键字创建任意的分词器。 ViterbiSegment 也是最短路分词,最短路求解采用Viterbi算法: Segmentsegment=newViterbiSegment() DijkstraSegment 依然是最短路分词,最短路求解采用Dijkstra算法: Segmentsegment=newDijkstraSegment() ∙DijkstraSegment比ViterbiSegment慢一点,但是调试信息更加丰富。 NShortSegment N最短分词器: Segmentsegment=newNShortSegment() ∙算法很美,速度很慢。 AhoCorasickSegment 使用AhoCorasickDoubleArrayTrie实现的最长分词器: Segmentsegment=newAhoCorasickSegment() ∙应该是速度最快的词典分词了。 CRFSegment 基于CRF的分词器: Segmentsegment=newCRFSegment() ∙应用场景不多。 通过HanLP.newSegment 通过此工厂方法得到的是当前版本速度和效果最平衡的分词器: Segmentsegment=HanLP.newSegment(); 推荐用户始终通过工具类HanLP调用,这么做的好处是,将来HanLP升级后,用户无需修改调用代码。 配置分词器 所有分词器都是 Segment 的子类, Segment 提供以下配置接口: /** *设为索引模式 * *@return */ publicSegmentenableIndexMode(booleanenable) /** *开启词性标注 *@paramenable *@return */ publicSegmentenablePartOfSpeechTagging(booleanenable) /** *开启人名识别 *@paramenable *@return */ publicSegmentenableNameRecognize(booleanenable) /** *开启地名识别 *@paramenable *@return */ publicSegmentenablePlaceRecognize(booleanenable) /** *开启机构名识别 *@paramenable *@return */ publicSegmentenableOrganizationRecognize(booleanenable) /** *是否启用用户词典 * *@paramenable */ publicSegmentenableCustomDictionary(booleanenable) /** *是否启用音译人名识别 * *@paramenable */ publicSegmentenableTranslatedNameRecognize(booleanenable) /** *是否启用日本人名识别 * *@paramenable */ publicSegmentenableJapaneseNameRecognize(booleanenable) /** *是否启用偏移量计算(开启后Term.offset才会被计算) *@paramenable *@return */ publicSegmentenabl


- 配套讲稿:
如PPT文件的首页显示word图标,表示该PPT已包含配套word讲稿。双击word图标可打开word文档。
- 特殊限制:
部分文档作品中含有的国旗、国徽等图片,仅作为作品整体效果示例展示,禁止商用。设计者仅对作品中独创性部分享有著作权。
- 关 键 词:
- hanlp 中文 分词 解读
 冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 《初级会计实务》试题题库大全及答案详解.docx
《初级会计实务》试题题库大全及答案详解.docx
-
《管理学》习题教材15章.docx
-
《教育学》读后感范文精选6篇.docx
-
《林教头风雪山神庙》练习题.docx
-
《企业文化》期末复习应考指南央专.docx
-
《数据结构》知识题汇编09第九章排序试题.docx
-
《偷影子的人》读后感集合15篇.docx
-
《幼儿园工作规程》.docx
-
《残疾人证》管理办法.docx
-
《故事》教学反思.docx
-
《Java语言学习知识程序设计》复习资料汇编.docx
-
《短文两篇》课堂实录.docx
-
《基于MATLAB的信号与系统实验指导》编程练习试题doc.docx
-
《昆虫记》好词好句大全.docx
-
《木棉树》阅读答案.docx
-
《区间信号自动控制》练习册答案.docx
-
《山东省中小学教师职称评审表》高级教师一级教师二级教师专用A4纸正反面打印按页码装订许知忠.docx
-
《安娜卡列尼娜》读后感.docx
-
《繁星春水》读后感15篇.docx
-
《苏州市市级示范物业管理项目服务质量评价标准》 doc.docx
-
《采薇》教案.docx
-
《假如给我三天光明》阅读测试题有答案.docx
-
《小学数学教师》读书笔记精选多篇.docx
-
《给幼儿教师的一把钥匙》读书笔记.docx
-
《劳动法》教案设计.docx
-
《综合基础知识》必看考点《刑法》含答案.docx
-
《建筑构造》考试试题及答案精华.docx
-
3套打包北师大版四年级下册英语期末单元测试题解析版.docx
-
《雷锋的微笑》观后感.docx
-
《女人故事》电视栏目策划方案1.docx
-
7万多车对比分解.docx
-
《调皮的日子》题库.docx
-
作文指导《生活中的传统文化》文档格式.docx
-
智慧城管解决方案文档格式.docx
-
室内大型儿童游乐场项目可行性综合分析报告Word文档格式.docx
-
幼儿园小班上学期教师个人工作总结Word文档下载推荐.docx
-
路基施工专项方案 超全Word文件下载.docx
-
送温暖感谢信文档格式.docx
-
中国共产党廉洁自律准则起施行Word文件下载.docx
-
小学六年级仿写句子集锦Word文档下载推荐.docx
-
眼科英文缩写对照表Word文档格式.docx
-
探析融资租赁资产证券化法律问题Word格式文档下载.docx
-
中国红歌会经典红歌100首歌曲曲目下载Word文件下载.docx
-
中学生元宵节灯谜大全及答案 元宵节猜灯谜文档格式.docx
-
英语词汇学期末考试题库Word文档格式.docx
-
小学数学三年级下册全册教案模板Word下载.docx
-
一次性帮你解决毕业论文的所有排版问题Word下载.docx
-
中学体育优秀说课稿Word文件下载.docx
-
新变电站综合自动化验收标准Word下载.docx
-
重庆市高级高三上一诊文科综合试题及答案免费下载Word文件下载.docx
-
一碗阳春面教案Word格式文档下载.docx
