 Windows下使用Hadoop实例.docx
Windows下使用Hadoop实例.docx
- 文档编号:24369611
- 上传时间:2023-05-26
- 格式:DOCX
- 页数:18
- 大小:516.78KB
Windows下使用Hadoop实例.docx
《Windows下使用Hadoop实例.docx》由会员分享,可在线阅读,更多相关《Windows下使用Hadoop实例.docx(18页珍藏版)》请在冰豆网上搜索。
Windows下使用Hadoop实例
Windows下使用Hadoop实例
1.1Windows下使用Hadoop的环境配置
(1)安装Hadoop前,首先需要安装Cygwin
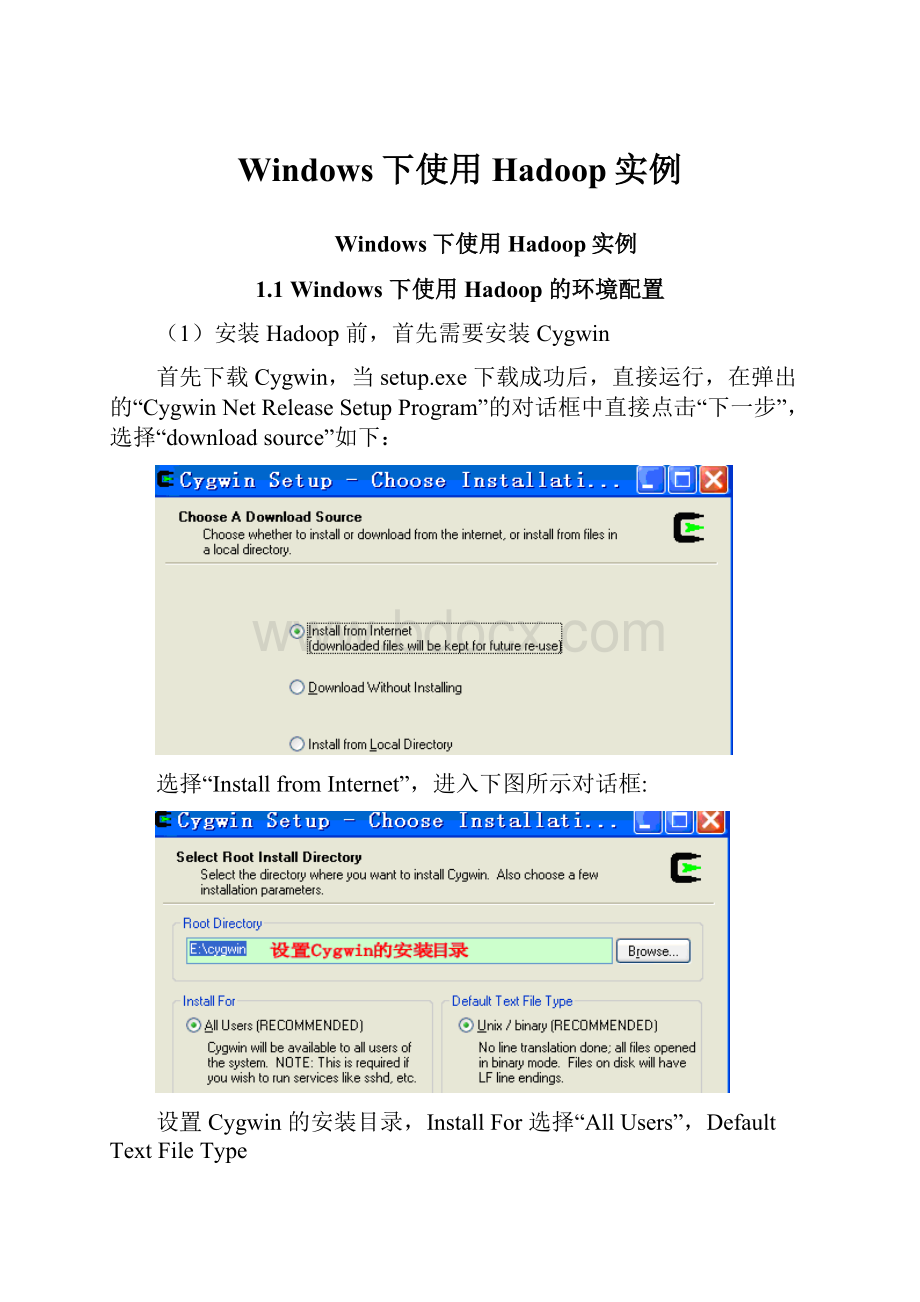
首先下载Cygwin,当setup.exe下载成功后,直接运行,在弹出的“CygwinNetReleaseSetupProgram”的对话框中直接点击“下一步”,选择“downloadsource”如下:
选择“InstallfromInternet”,进入下图所示对话框:
设置Cygwin的安装目录,InstallFor选择“AllUsers”,DefaultTextFileType
选择“Unix/binary”。
“下一步”之后,设置Cygwin安装包存放目录:
设置“InternetConnection”的方式,选择“DirectConnection”:
之后选择“Downloadsite”:
选择最好选.cn结尾的,若无可以随意选择,若安装失败可多尝试几个。
“下一步”之后,可能会弹出下图的“SetupAlert”对话框,直接“确定”即可。
在上图所示的对话框过程中,可能会弹出如下图所示的“SetupAlert”对话框,直接点击“确定”即可。
进入“SelectPackages”对话框,必须保证“NetCategory”下的“OpenSSL”被安装:
安装中需要选中Netcategory中的openssh,如下图所示:
如果还打算在eclipse上编译Hadoop,则还必须安装“BaseCategory”下的“sed”,如下图所示:
另外,安装“EditorsCategory”下的vim,以方便在Cygwin上直接修改配置文件;“DevelCategory”下的subversion建议安装,如下图所示:
安装完成后进行环境变量的配置。
(2)安装JDK
(3)配置Windows系统变量
新建系统变量CYGWIN,变量值为ntsectty
编辑系统变量里的Path变量,将JDK的bin目录、Cygwin的bin目录以及Cygwin的usr\bin目录加入到Path变量中。
新建系统变量JAVA_HOME,变量指向JRE安装目录。
(4)安装配置ssh
启动cygwin,执行命令:
$ssh-host-config。
当询问"Shouldprivilegeseparationbeused"时,输入no;当询问"Doyouwanttoinstallsshdasaservice?
"选yes;当提示"EnterthevalueofCYGWINforthedaemon:
[ntsec]"时,选择ntsec。
当看到“Havefun”时,一般表示sshd服务安装成功了。
输入命令$netstartsshd,启动SSH,或者在Windows服务项里启动CYGWINsshd。
然后执行$ssh-keygen来生成密钥对,然后一直回车键确定。
这样会把生产的密钥对保存在.ssh目录下。
使用命令将RSA公钥加入到公钥授权文件authorized_keys中:
$cd.ssh
$catid_rsa.pub>>authorized_keys
最后执行$sshlocalhost,就可以实现无需密码的SSH连接。
完成上述操作后,执行exit命令先退出Cygwin窗口。
执行sshlocalhost时,会有如下图所示的提示,输入yes,然后回车即可:
如果不是第一次执行则会出现如下对话框:
成功启动ssh服务。
1.2安装Hadoop
将Hadoop安装包(在此使用的是hadoop-0.20.2)解压到你自己选择的目录,然后需要修改hadoop的配置文件,它们位于conf子目录下,分别是hadoop-env.sh、core-site.xml、hdfs-site.xml和mapred-site.xml共四个文件。
1.2.1修改hadoop-env.sh
只需要将JAVA_HOME修改成JDK的安装目录即可,需要注意两点:
(1)JDK必须是1.6或以上版本;
(2)设置JDK的安装目录时,路径不能是Windows风格的目录例如:
C:
\Java\jdk1.6.0_22,而是LINUX风格:
/cygdrive/d/Program/Java/jdk1.6.0_22。
因此在hadoop-env.sh中设定JDK的安装目录:
exportJAVA_HOME=/cygdrive/c/Java/jdk1.6.0_22(注意删除-sun和export前面的注释“#”)
1.2.2修改core-site.xml
为简化core-site.xml配置,将src\core目录下的core-default.xml文件复制到conf目录下,并将core-default.xml文件名改成coresite.xml。
修改:
//localhost:
9000
1.2.3修改hdfs-site.xml
为简化hdfs-site.xml配置,将src\hdfs目录下的hdfs-default.xml文件复制到conf目录下,并将hdfs-default.xml文件名改成hdf-site.xml。
修改:
1.2.4修改mapred-site.xml
为简化mapred-site.xml配置,将src\mapred目录下的mapreddefault.xml文件复制到conf目录下,并将mapred-default.xml文件名改成mapred-site.xml。
修改:
9001
到此修改完成,然后启动hadoop。
1.3启动hadoop
在Cygwin中,进入hadoop的bin目录,运行./start-all.sh启动hadoop,在启动成功之后,可以执行./hadoopfs-ls/命令,查看hadoop的根目录,如下图所示:
首先我们要先启动sshd服务,然后登录:
然后启动hadoop:
我们可以验证是否启动成功:
有时在启动的时候会遇到一些问题,可能会出现
这时可能我们需要格式化,用命令:
./hadoopnamenode–format进行格式化。
至此,我们的Hadoop安装成功。
1.4Hadoop运行wordcount实例
运行WordCount实例。
在本地文件系统上建立input目录,放入若干文件,文件为由多个单词组成(单词由空格分隔)的文本。
将文件复制到HDFS的目录下,命名为input,并运行:
$bin/hadoopdfs-putinputinput
没有内容输出就说明上传至文件系统成功。
运行:
$bin/hadoopjarhadoop-0.19.2-examples.jarwordcountinputoutput
output为数据处理完成后输出目录,默认在Hadoop根目录下。
任务执行完,用以下命令查看分布式文件系统上数据处理的结果:
$bin/hadoopdfs-catoutput/*
至此,完成wordcount实例的运行。
1.5使用eclipse编写Hadoop应用程序
在此,用eclipse编写了一个简单的程序。
1)在eclipse下创建一个java工程DFSOperator,并创建相应的类。
2)配置编译参数
配置“BuildPath”,选中“DFSOperator”,单击右键,点击下图所示菜单“BuildPath->ConfigureBuildPath”,进入“JavaBuildPath”配置界面。
选择“Libraries”标签页,点击右侧的“AddExternalJAR”按钮,将安装好的“hadoop-0.20.2-core.jar”添加进来。
3)编辑源代码
4)编译生成jar包
右键“DFSOperator”项目,选择“BuildProject”,编译项目工程,编译“DFSOperator.java”后,生成下图所示的DFSOperator.class文件:
右键项目,选择“Export”,导出“JARfile”,也就是jar包。
然后将导出的jar文件上传到HadoopMaster节点。
5)运行
导出的jar文件放到hadoop的bin文件下,进入Hadoop的bin目录,用以下命令进行测试运行:
(1)ls:
查看当前目录,检查dfs_operator.jar是否存在;
(2)./hadoopfs-ls/:
查看Hadoop根目录下是否存在dfs_operator.txt文件;
(3)./hadoopjar./dfs_operator.jarDFSOperator:
运行dfs_operator.jar,以生成dfs_operator.txt文件;
(4)./hadoopfs-ls/:
再查看Hadoop根目录下是否存在dfs_operator.txt文件;
(5)./hadoopfs-cat/dfs_operator.txt:
检查dfs_operator.txt文件的内容。
该程序完成的功能简单,但从中可以学到如何在Windows下利用eclipse进行Hadoop编程。
1.6使用IBMMapReduceToolsforEclipse进行Hadoop编程(完成wordcount)
使用IBMMapReduceToolsforEclipse,使用这个Eclipseplugin可以简化开发和部署Hadoop并行程序的过程。
基于这个plugin,可以在Eclipse中创建一个HadoopMapReduce应用程序,并且提供了一些基于MapReduce框架的类开发的向导,可以打包成JAR文件,部署一个HadoopMapReduce应用程序到一个Hadoop服务器(本地和远程均可),可以通过一个专门的视图(perspective)查看Hadoop服务器、Hadoop分布式文件系统(DFS)和当前运行的任务的状态。
1)安装插件IBMMapReduceToolsforEclipse
安装插件,然后点击Eclipse主菜单上Windows->Preferences,然后在左侧选择HadoopHomeDirectory,设定Hadoop主目录:
2)创建MapReduceProject
点击Eclipse主菜单上File->New->Project,在弹出的对话框中选择MapReduceProject。
然后就可以一个普通的EclipseJavaproject那样,添加入Java类。
编码后导出jar包,与创建javaProject相同。
导出jar包后,在hadoop下运行。
至此完成wordcount。
IBMMapReducetools还提供了几个实用的向导(wizard)工具,帮助创建单独的Mapper类,Reducer类,MapReduceDriver类,在编写比较复杂的MapReduce程序时,将这些类独立出来是非常有必要的,也有利于在不同的计算任务中重用自己编写的各种Mapper类和Reducer类。


- 配套讲稿:
如PPT文件的首页显示word图标,表示该PPT已包含配套word讲稿。双击word图标可打开word文档。
- 特殊限制:
部分文档作品中含有的国旗、国徽等图片,仅作为作品整体效果示例展示,禁止商用。设计者仅对作品中独创性部分享有著作权。
- 关 键 词:
- Windows 使用 Hadoop 实例
 冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 《当代世界政治与经济》.docx
《当代世界政治与经济》.docx
-
《背起爸爸上学》观后感5篇精品模板.docx
-
《个人能力提升计划》.docx
-
《教务管理课程管理系统》系统分析实验报告docx.docx
-
《弟子规》全文带拼音.docx
-
《海底两万里》名著导读及检测试题教学内容.docx
-
《氓》导学案答案.docx
-
《吞食天地2诸葛孔明传》完全攻略.docx
-
《再见了母校》诗歌朗诵稿6篇范文.docx
-
《铸造工艺说明书》word版.docx
-
12Unit9TheDamnedHumanRace.docx
-
27魏利金主讲郑州关于举办建筑结构设计疑难问题及结构施工图设计及审图常见问题专题1.docx
-
《电力建设工程质量监督检查典型大纲》风力发电部分.docx
-
《和孩子划清界限》读书笔记.docx
-
《莫泊桑小说两篇》doc.docx
-
《网络设备安装配置与调试》试题B卷.docx
-
《安全生产技术》第一章第一节.docx
-
《高级计算机网络》课程综述.docx
-
《检验核医学》教学大纲.docx
-
《大学英语》第6段段落与课文翻译.docx
-
《构造地质学》作图题例题.docx
-
《流体力学与热工基础》教学大纲重点难点.docx
-
《索证索要制度》.docx
-
《中医临床护理学》试题库及答案六.docx
-
2汽车装配工艺及调试技术10页word.docx
-
5 草船借箭教案.docx
-
《管理会计》试题库选择.docx
-
《麻雀》教案.docx
-
《砼渗水整改措施》.docx
-
《语言学纲要》 叶蜚声徐通锵版复习.docx
-
《产品质量法》培训.docx
-
《工程招投标与合同管理》期末考试复习题及参考答案.docx
-
人教版九年级物理全册152电流和电路达标检测练习题.docx
-
小学一年级语文上册全部知识点归纳部编版.docx
-
直螺纹钢筋接头工艺标准.docx
-
1选出下列句子中成语使用正确的一项.docx
-
届第三单元 牛顿运动定律第4节 实验四 验证牛顿第二定律.docx
-
届黄冈市模拟及答题适应性考试英语扫描版含答案 145927.docx
-
金地集团营销案场标准服务流程指引.docx
-
精品文档大学C++期末考试题库及答案.docx
-
精撰XX商会网站平台建设及运营推广策划方案.docx
-
九州教育高考英语一轮特殊句式讲义.docx
-
我国医疗卫生现状和未来发展.docx
-
品质管理制度表格水下抛石单元工程质量评定表.docx
-
新人教版五年级数学下册第3单元《长方体和正方体》教学设计.docx
-
精编四年级数学上册口算题卡 30.docx
-
精品区城管工作总结工作总结格式范文.docx
-
餐饮管理餐饮场所消防安全管理规范.docx
-
高三英语二轮 备考抓分点透析专题2 形容词和副词.docx
-
广东省小学信息技术第三册上教案.docx
-
项目经理应知应会.docx
