 云平台系统架构设计文档v2.docx
云平台系统架构设计文档v2.docx
- 文档编号:23536449
- 上传时间:2023-05-18
- 格式:DOCX
- 页数:17
- 大小:1.46MB
云平台系统架构设计文档v2.docx
《云平台系统架构设计文档v2.docx》由会员分享,可在线阅读,更多相关《云平台系统架构设计文档v2.docx(17页珍藏版)》请在冰豆网上搜索。
云平台系统架构设计文档v2
云平台系统架构设计文档
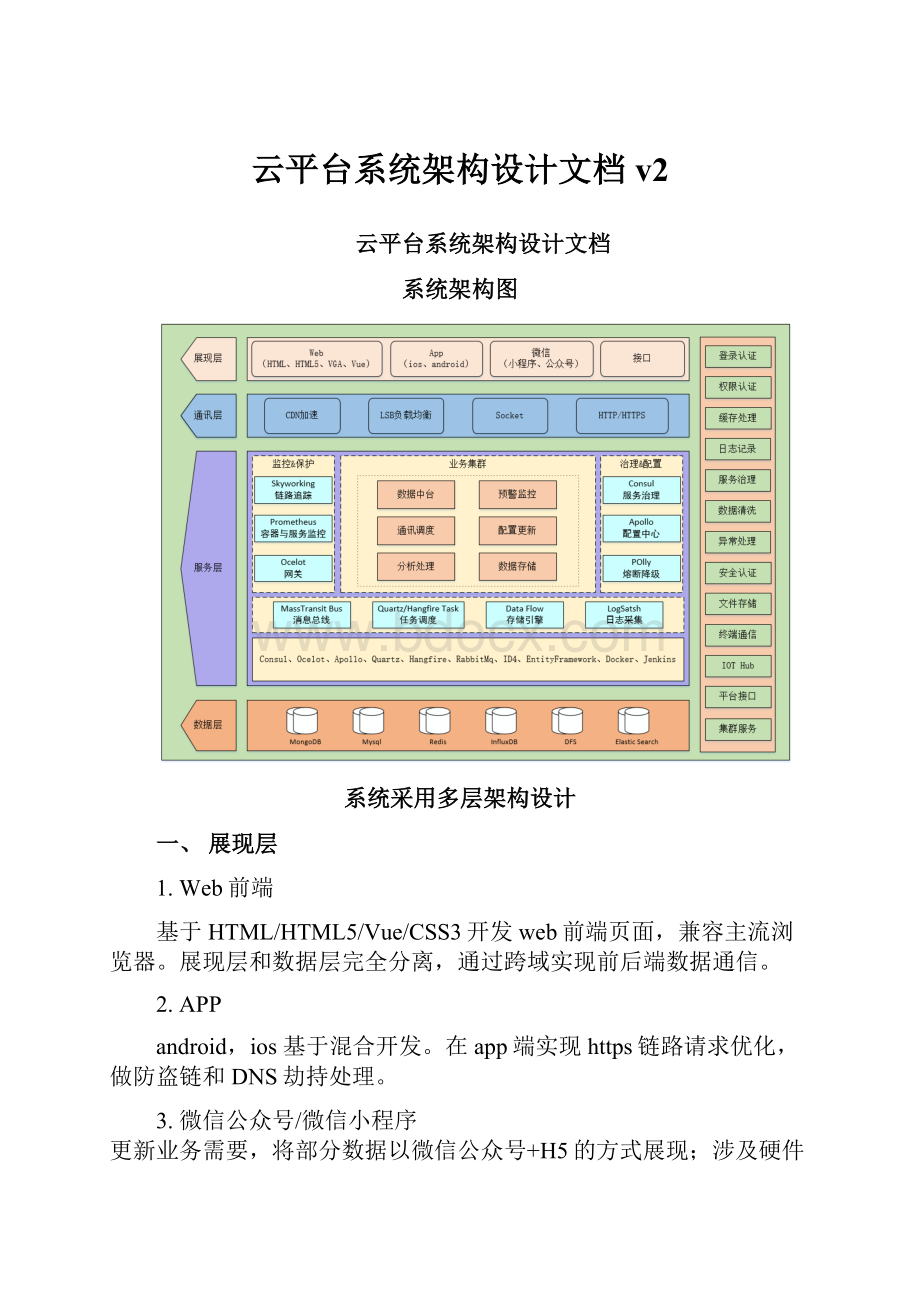
系统架构图
系统采用多层架构设计
一、展现层
1.Web前端
基于HTML/HTML5/Vue/CSS3开发web前端页面,兼容主流浏览器。
展现层和数据层完全分离,通过跨域实现前后端数据通信。
2.APP
android,ios基于混合开发。
在app端实现https链路请求优化,做防盗链和DNS劫持处理。
3.微信公众号/微信小程序
更新业务需要,将部分数据以微信公众号+H5的方式展现;涉及硬件设备控制功能的系统部分模块采用微信小程序,增加用户操作体验和访问便捷性。
4.接口服务
基于特定业务,提供标准接口,对外提供数据服务。
二、通讯层
1.基于阿里云CDN实现静态数据加速;
2.基于阿里云SLB,实现服务器负载均衡;
3.基于TCP/HTTP/HTTPS三种通信方式,实现前后端数据通信;
三、服务层
微服务是可以独立部署、水平扩展、独立访问(或者有独立的数据库)的服务单元,提倡将单一应用程序划分成一组小的服务,服务之间互相协调、互相配合,为用户提供最终价值。
每个服务运行在其独立的进程中,服务与服务间采用轻量级的通信机制互相沟通(RESTfulAPI)。
每个服务都围绕着具体的业务进行构建,并且能够被独立地部署到生产环境、类生产环境等。
应尽量避免统一的、集中式的服管理机制,对具体的一个服务而言,应根据业务上下文,选择合适的语言、工具对其进行构建。
相关的组件包括如下:
1.Consul
consul是一个服务管理软件。
支持多数据中心下,分布式高可用的,服务发现和配置共享。
consul支持健康检查,允许存储键值对。
一致性协议采用Raft算法,用来保证服务的高可用。
成员管理和消息广播采用GOSSIP协议,支持ACL访问控制。
●服务注册:
一个服务将其位置信息在“中心注册节点”注册的过程。
该服务一般会将它的主机IP地址以及端口号进行注册,有时也会有服务访问的认证信息,使用协议,版本号,以及关于环境的一些细节信息。
●服务发现:
服务发现可以让一个应用或者组件发现其运行环境以及其它应用或组件的信息。
用户配置一个服务发现工具就可以将实际容器跟运行配置分离开。
2.Ocelot
Ocelot是一个功能强大的开源的API网关,包括了:
路由、请求聚合、服务发现、认证、鉴权、限流熔断、并内置了负载均衡器与ServiceFabric、ButterflyTracing集成。
3.Hangfire
Hangfire是一个开放源代码框架,可创建,处理和管理后台作业,支持各种后台任务-短期运行和长期运行,CPU密集型和I/O密集型,一次配置可以持续运行。
优点:
●支持各种常见的任务类型
●持久化保存任务、队列、统计信息
●重试机制
●多语言支持
●支持任务取消
●支持按指定JobQueue处理任务
●服务器端工作线程可控,即job执行并发数控制
●分布式部署,支持高可用
●良好的扩展性,如支持IOC、HangfireDashboard授权控制、持久化存储
4.Exceptionless
Exceptionless专注于提供实时错误和日志报告。
主要包括:
错误通知、智能分组异常、详细错误报告堆栈跟踪、支持离线、UI查看重要错误和确定优先级、仪表板上的统计信息和趋势、对异常标记为已修复,监视回归、将事件标记为关键等。
基于ElasticSearch做到快速检索日志与异常信息。
5.Apollo
Apollo(阿波罗)是携程框架部门研发的分布式配置中心,能够集中化管理应用不同环境、不同集群的配置,配置修改后能够实时推送到应用端,并且具备规范的权限、流程治理等特性,适用于微服务配置管理场景。
支持4个维度管理Key-Value格式的配置:
●application(应用)
●environment(环境)
●cluster(集群)
●namespace(命名空间)
服务端基于SpringBoot和SpringCloud开发,打包后可以直接运行,不需要额外安装Tomcat等应用容器。
Java客户端不依赖任何框架,能够运行于所有Java运行时环境,同时对Spring/SpringBoot环境也有较好的支持。
.Net客户端不依赖任何框架,能够运行于所有.Net运行时环境。
6.MassTransitBus
MassTransit免费开源分布式应用程序框架,可以轻松创建利用基于消息的松耦合异步通信的应用程序和服务,以提高可用性,可靠性和可伸缩性。
使用RabbitMQ,AzureServiceBus,ActiveMQ和AmazonSQS/SNS部署解决方案保证数据传输流动性。
强大的消息模式,包括消息使用者,持久性Sagas和事件驱动的状态机,以及基于路由清单的带补偿的分布式事务。
处理消息序列化,标头,代理拓扑,消息路由,异常,重试,并发,连接和管理使用者生命周期。
以此保证数据一致性
7.Skyworking
SkyWalking的核心是数据分析和度量结果的存储平台,通过HTTP或gRPC方式向SkyWalkingCollecter提交分析和度量数据,SkyWalkingCollecter对数据进行分析和聚合,存储到Elasticsearch、H2、MySQL、TiDB等其一即可,最后我们可以通过SkyWalkingUI的可视化界面对最终的结果进行查看。
8.Prometheus
Prometheus采用Pull方式获取监控信息,并提供了多维度的数据模型和灵活的查询接口。
不仅可以通过静态文件配置监控对象,还支持自动发现机制,能通过Kubernetes、Consl、DNS等多种方式动态获取监控对象。
在数据采集方面,借助Go语音的高并发特性,单机Prometheus可以采取数百个节点的监控数据;在数据存储方面,随着本地时序数据库的不断优化,单机Prometheus每秒可以采集一千万个指标,支持远程存储存储大量的历史监控数据。
四、数据层
1.MongoDB
分布式文件存储的数据库,存储非结构化、关联性弱的业务数据。
如,控制器下发的指令数据,监测设备收集的传感器数据,同时与ElasticSearch做双介质存储;
2.Mysql
高可用关系型数据库,读写分离,存储事务性数据,以及关联性将强的数据。
如,配置、用户、租户等SaaS化数据;
3.Redis
高性能的key-value数据库,主从同步。
存储实时数据,缓存数据。
如:
监测设备收集的实时最新传感器数据;
4.InfluxDB
开源时序型数据库,存储系统监控数据;
5.DFS
分布式文件存储,存储文件,包含文件处理与时间戳控制;
6.ElasticSearch
基于Lucene的开源分布式多用户全文搜索引擎,是当前流行的企业级搜索引擎。
设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
如:
PB级数据存储,实现监测设备收集的传感器数据历史数据存储。
安全认证设计
一、用户密码认证
采用双token的方式完成jwt。
其中accessToken用于用户身份认证。
refreshToken用于当accessToken失效时重新生成。
1.用户登录
2.token认证访问(accessToken有效)
3.token认证访问(accessToken失效,refreshToken有效)
4.accessToken和refreshToken都失效
二、客户端认证
客户端向认证服务器进行身份认证,并要求颁发一个访问令牌。
日志系统设计
日志集中化管理,采用ELK解决方案。
通过Logstash去收集每台服务器日志文件,然后按定义的正则模板过滤后传输到Rabbitmq,然后由另一个Logstash从Rabbitmq读取日志存储到Elasticsearch中创建索引,最后通过Kibana展示给开发者或运维人员进行分析。
这样大大提升了运维线上问题的效率。
●Elasticsearch:
是个开源分布式搜索引擎,提供搜集、分析、存储数据三大功能。
它的特点有:
分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。
●Logstash:
主要是用来日志的搜集、分析、过滤日志的工具,支持大量的数据获取方式。
一般工作方式为c/s架构,client端安装在需要收集日志的主机上,server端负责将收到的各节点日志进行过滤、修改等操作在一并发往elasticsearch上去。
●Kibana:
一个开源和免费的工具,Kibana可以为Logstash和ElasticSearch提供的日志分析友好的Web界面,可以帮助汇总、分析和搜索重要数据日志。
缓存处理设计
采用Memory内存与Redis分布式缓存结合设计方案,建立Redis高可用主从集群,微服务集群中的单体应用同时使用Memory和Redis,需要更新缓存时,由缓存处理中心更新Redis分布式集群缓存,并推送更新消息至企业总线,使用企业总线进行通知微服务集群内部节点进行Memory内存缓存刷新。
一、Redis分布式缓存
分布式缓存选取方案:
1.高性能
变化少、变化频率低、请求频率高的数据查询出来后放入分布式缓存,二次查询直接请求缓存即可。
应用场景:
数据字典数据量较大,基本不会发生变化,每次请求数据库查询则会降低数据库对其他操作的读写性能,直接放入缓存中则可以快速响应,释放数据库性能压力。
2.高并发
高QPS场景适用,有效释放系统线程与网络压力,通过响应速度提高并发。
应用场景:
数据字典高并发访问,十万级并发轻松应对。
3.数据的持久化
可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用
Redis分布式集群优点
●没有中心节点,客户端与Redis节点直连,不需要中间代理层;
●数据可以被分片存储,每个节点保存一部分数据,互不相通,某个节点挂掉可能丢失数据,所以要为每个节点设置冗余节点;
●管理方便,后续可以自行添加或删除节点;
二、Memory缓存
Memory缓存选举方案:
1.更高性能
获取缓存数据不通过网络请求,针对大数据量,减少网络因素对缓存获取产生的影响,性能更高。
应用场景:
应用私有缓存数据。
数据清洗设计
采用云原生处理方案,根据调度规则按时间、周期、数据量进行数据清洗,根据不同数据场景使用不同的数据清洗处理方案。
一、缺失数据处理方案
1.直接删除(Deletedirectly)
使用场景:
适用于数据样本较大的情况,数据样本较小时,可能会影响最终的分析结果。
2.估算(Estimation)
使用场景:
●数据分布均匀:
使用均值法/众数法进行填充
●数据分布倾斜,使用中位数填充
3.插补法(Interpolationmethod)
使用场景:
●随机插补法:
从数据总体中随机抽取某几个样本代替缺失数据。
●多重填补法:
包含m个插补值的向量代替每一个缺失值的过程,要求m大于等于20。
m个完整数据集合能从插补向量中创建。
●热平台插补:
在非缺失数据集中找到一个与缺失值所在样本相似的样本,利用其中的观测值对缺失值进行插补。
二、异常数据处理方案
1.不处理(Donotdealwith)
使用场景:
允许存在异常值,算法对异常值不敏感时,则可以不处理;
2.平均值替代(Averageoverride)
使用场景:
不允许存在异常值,利用平均值来代替异常值,损失信息小,简单高效。
3.视为缺失值(Consideredmissingvalues)
使用场景:
不允许存在异常值,将异常值视为缺失值来处理,采用处理缺失值的方法来处理异常值
三、重复数据处理方案
1.去重(Duplicateremoval)
使用场景:
数据值完全相同的多条数据记录,数据标识也完全相同。
直接去重即可。
2.噪音处理
使用场景:
数据中存在着错误或异常(偏离期望值)的数据。
解决方案:
分箱法
分箱方法:
●等深分箱法:
按记录行数分箱,每箱具有相同的记录数
●等宽分箱法:
每个箱的区间范围是一个常量,根据区间范围分箱
分箱数据平滑处理:
●均值平滑:
对同一箱值中的数据求平均值,箱内的数据用平均值代替。
●中位数平滑:
取中位数,箱内数据用中位数来代替。
●边界平滑:
箱中的最大和最小值同样被视为边界。
箱中的每一个值被最近的边界值替换。
通讯调度设计
分布式调度中心负责调度通讯调度任务,通讯调度任务接收企业总线与瞬时通讯消息与数据库中存储的长期通讯消息,将消息下发存储到Redis分布式缓存,终端上线后,终端通信服务则从Redis集群中拉取待下发消息,消息下发收到成功反馈后,则将通信状态写入Redis中,通过企业总线通知通讯调度任务,触发内部通讯状态同步规则,将Redis与DB进行历史消息下发状态同步。
报警监控设计
报警监控中心负责接收数据,并进行报警规则分析匹配,然后选择性进行推送。
持续集成设计
持续集成的目的,就是让产品可以快速迭代,同时还能保持高质量。
软件的新版本通过评审后,自动部署到生产环境。


- 配套讲稿:
如PPT文件的首页显示word图标,表示该PPT已包含配套word讲稿。双击word图标可打开word文档。
- 特殊限制:
部分文档作品中含有的国旗、国徽等图片,仅作为作品整体效果示例展示,禁止商用。设计者仅对作品中独创性部分享有著作权。
- 关 键 词:
- 平台 系统 架构 设计 文档 v2
 冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 《公务员财产申报制度》.docx
《公务员财产申报制度》.docx
-
《儿童口腔病学》汇总题库集.docx
-
《建筑施工组织与管理》教案教学内容.docx
-
《班委选举细则》.docx
-
《光伏组件监造技术标准》.docx
-
《年终表彰大会讲话稿 表彰大会致辞稿》.docx
-
《听颖师弹琴》《李凭箜篌引》分别鉴赏及对比鉴赏加练习人教版高一选修.docx
-
《鹬》分镜头脚本.docx
-
5套打包宜昌市小学四年级语文上期中考试单元测试题及答案.docx
-
16开纸田字格word字帖模板.docx
-
315食品安全活动策划书.docx
-
CFG桩基础施工方案详解.docx
-
08人机工程学中英文资料外文翻译文献.docx
-
《读古典名著口百味人生》获奖精品省优获奖教案 部编版语文精品.docx
-
《功课很重要》教案1学习资料.docx
-
《冷拼工艺》教案.docx
-
《唐人街探案3》电影观后感《唐人街探案3》心得作文5篇.docx
-
《C语言程序设计》习题.docx
-
《幼儿园课程游戏化的实践研究》.docx
-
4现场管理档案.docx
-
13级西医专业基础综合测评答.docx
-
100部校园电影全.docx
-
CAD制图标准.docx
-
《分数除法一.docx
-
edb72192ac02de80d4d8d15abe23482fb5da0291.docx
-
H236车联网资料路尚行业版OMP操作手册服务商0618.docx
-
jarlasscon门机.docx
-
《百分百责任学习心得》.docx
-
《管理学基础》习题18章单凤儒.docx
-
《旅游专业日语》课程实施方案.docx
-
《铁路旅客运输服务》学习指导书.docx
-
《预算会计》课程标准.docx
-
雷锋心得体会范文.docx
-
4字网名大全500个.docx
-
税收.docx
-
民法学课程教学大纲.docx
-
数控论文铣削盖板类零件的加工1.docx
-
上海地铁车站值班员理论考试习题集qwq.docx
-
李大钊与北京大学.docx
-
机耕道路施工组织设计Word最新版.docx
-
连串平行及连串反应的等温优化参考模板.docx
-
医用耗材招标中标确认表.docx
-
基于某TDOA原理计算信号源位置的算法探讨.docx
-
七年级上册人教版政治知识点doc.docx
-
计生条例.docx
-
临电建筑工程临时用电经典计算两种方法均有.docx
-
冀教版小学数学一年级上册口算试题卡全册.docx
-
汽配行业分析报告.docx
-
国际货运代理考试业务真题及答案.docx
-
沈阳市东北育才学校学年高一上学期第二次阶段考试政治试题 Word版含答案.docx
-
浅谈重庆苏宁物流存在的问题及对策之欧阳索引创编.docx
