 支持向量机及Python代码实现Word下载.docx
支持向量机及Python代码实现Word下载.docx
- 文档编号:22750658
- 上传时间:2023-02-05
- 格式:DOCX
- 页数:28
- 大小:474.06KB
支持向量机及Python代码实现Word下载.docx
《支持向量机及Python代码实现Word下载.docx》由会员分享,可在线阅读,更多相关《支持向量机及Python代码实现Word下载.docx(28页珍藏版)》请在冰豆网上搜索。
i=1,...,n
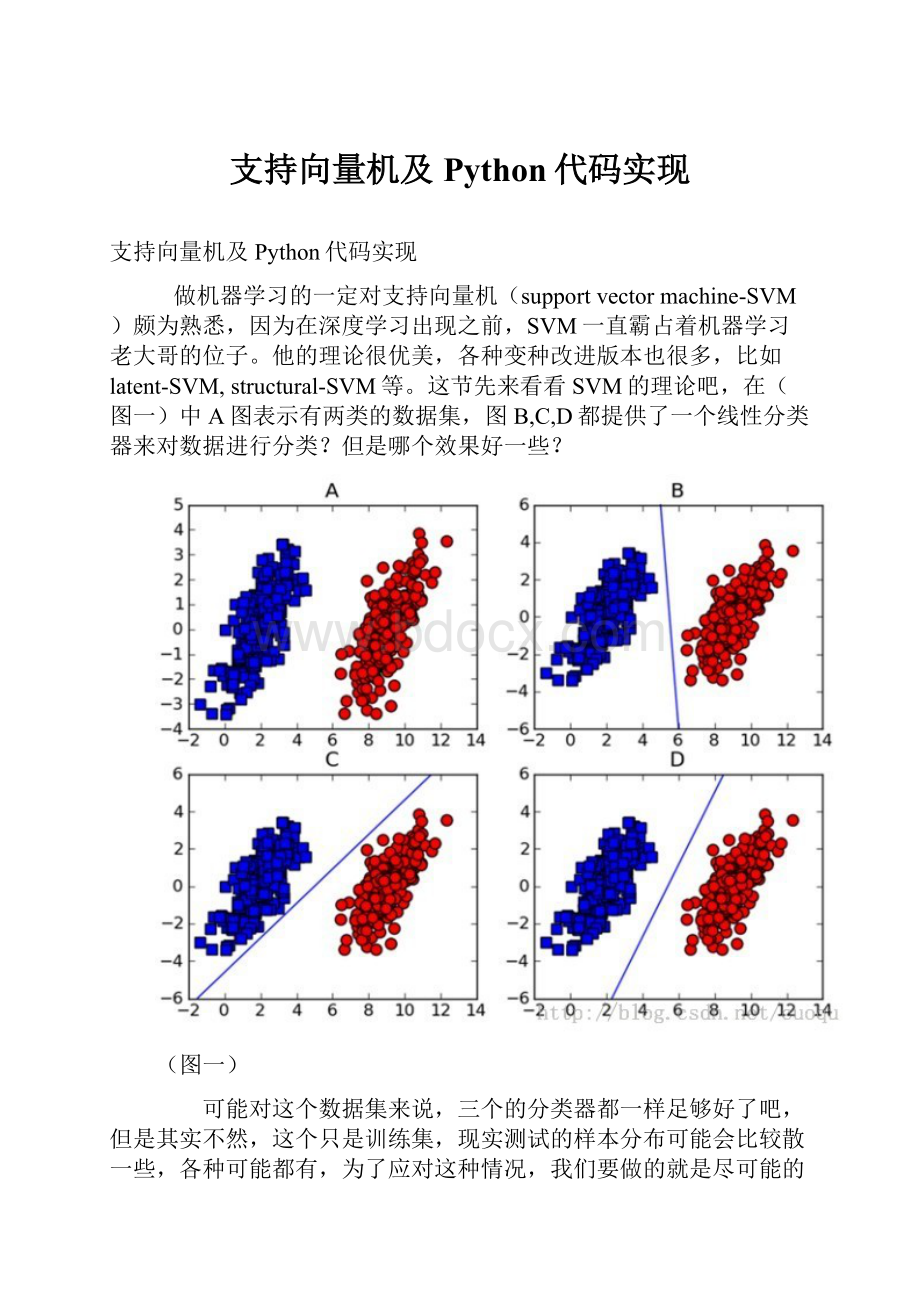
(iii)有不等式约束的优化问题,可以写为:
s.t.g_i(x)<
=0;
i=1,...,n
h_j(x)=0;
j=1,...,m
对于第(i)类的优化问题,常常使用的方法就是Fermat定理,即使用求取f(x)的导数,然后令其为零,可以求得候选最优值,再在这些候选值中验证;
如果是凸函数,可以保证是最优解。
对于第(ii)类的优化问题,常常使用的方法就是拉格朗日乘子法(LagrangeMultiplier),即把等式约束h_i(x)用一个系数与f(x)写为一个式子,称为拉格朗日函数,而系数称为拉格朗日乘子。
通过拉格朗日函数对各个变量求导,令其为零,可以求得候选值集合,然后验证求得最优值。
对于第(iii)类的优化问题,常常使用的方法就是KKT条件。
同样地,我们把所有的等式、不等式约束与f(x)写为一个式子,也叫拉格朗日函数,系数也称拉格朗日乘子,通过一些条件,可以求出最优值的必要条件,这个条件称为KKT条件。
而(公式三)很明显符合第二类优化方法,因此可以使用拉格朗日乘子法来对其求解,在求解之前,我们先对(公式四)做个简单的变换。
最大化||W||的导数可以最小化||W||或者W’W,如(公式四)所示:
(公式四)
套进拉格朗日乘子法公式得到如(公式五)所示的样子:
(公式五)
在(公式五)中通过拉格朗日乘子法函数分别对W和b求导,为了得到极值点,令导数为0,得到
然后把他们代入拉格朗日乘子法公式里得到(公式六)的形式:
(公式六)
(公式六)后两行是目前我们要求解的优化函数,现在只需要做个二次规划即可求出alpha,二次规划优化求解如(公式七)所示:
(公式七)
通过(公式七)求出alpha后,就可以用(公式六)中的第一行求出W。
到此为止,SVM的公式推导基本完成了,可以看出数学理论很严密,很优美,尽管有些同行们认为看起枯燥,但是最好沉下心来从头看完,也不难,难的是优化。
二次规划求解计算量很大,在实际应用中常用SMO(Sequentialminimaloptimization)算法,SMO算法打算放在下节结合代码来说。
参考文献:
[1]machinelearninginaction.PeterHarrington
[2]LearningFromData.YaserS.Abu-Mostafa
上节基本完成了SVM的理论推倒,寻找最大化间隔的目标最终转换成求解拉格朗日乘子变量alpha的求解问题,求出了alpha即可求解出SVM的权重W,有了权重也就有了最大间隔距离,但是其实上节我们有个假设:
就是训练集是线性可分的,这样求出的alpha在[0,infinite]。
但是如果数据不是线性可分的呢?
此时我们就要允许部分的样本可以越过分类器,这样优化的目标函数就可以不变,只要引入松弛变量
即可,它表示错分类样本点的代价,分类正确时它等于0,当分类错误时
,其中Tn表示样本的真实标签-1或者1,回顾上节中,我们把支持向量到分类器的距离固定为1,因此两类的支持向量间的距离肯定大于1的,当分类错误时
肯定也大于1,如(图五)所示(这里公式和图标序号都接上一节)。
(图五)
这样有了错分类的代价,我们把上节(公式四)的目标函数上添加上这一项错分类代价,得到如(公式八)的形式:
(公式八)
重复上节的拉格朗日乘子法步骤,得到(公式九):
(公式九)
多了一个Un乘子,当然我们的工作就是继续求解此目标函数,继续重复上节的步骤,求导得到(公式十):
(公式十)
又因为alpha大于0,而且Un大于0,所以0<
alpha<
C,为了解释的清晰一些,我们把(公式九)的KKT条件也发出来(上节中的第三类优化问题),注意Un是大于等于0:
推导到现在,优化函数的形式基本没变,只是多了一项错分类的价值,但是多了一个条件,0<
C,C是一个常数,它的作用就是在允许有错误分类的情况下,控制最大化间距,它太大了会导致过拟合,太小了会导致欠拟合。
接下来的步骤貌似大家都应该知道了,多了一个C常量的限制条件,然后继续用SMO算法优化求解二次规划,但是我想继续把核函数也一次说了,如果样本线性不可分,引入核函数后,把样本映射到高维空间就可以线性可分,如(图六)所示的线性不可分的样本:
(图六)
在(图六)中,现有的样本是很明显线性不可分,但是加入我们利用现有的样本X之间作些不同的运算,如(图六)右边所示的样子,而让f作为新的样本(或者说新的特征)是不是更好些?
现在把X已经投射到高维度上去了,但是f我们不知道,此时核函数就该上场了,以高斯核函数为例,在(图七)中选几个样本点作为基准点,来利用核函数计算f,如(图七)所示:
(图七)
这样就有了f,而核函数此时相当于对样本的X和基准点一个度量,做权重衰减,形成依赖于x的新的特征f,把f放在上面说的SVM中继续求解alpha,然后得出权重就行了,原理很简单吧,为了显得有点学术味道,把核函数也做个样子加入目标函数中去吧,如(公式十一)所示:
(公式十一)
其中K(Xn,Xm)是核函数,和上面目标函数比没有多大的变化,用SMO优化求解就行了,代码如下:
[python]
viewplaincopy
1.def
smoPK(dataMatIn,
classLabels,
C,
toler,
maxIter):
#full
Platt
SMO
2.
oS
=
optStruct(mat(dataMatIn),mat(classLabels).transpose(),C,toler)
3.
iter
0
4.
entireSet
True;
alphaPairsChanged
5.
while
(iter
<
maxIter)
and
((alphaPairsChanged
>
0)
or
(entireSet)):
6.
7.
if
entireSet:
#go
over
all
8.
for
i
in
range(oS.m):
9.
+=
innerL(i,oS)
10.
"
fullSet,
iter:
%d
i:
%d,
pairs
changed
%d"
%
(iter,i,alphaPairsChanged)
11.
1
12.
else:
non-bound
(railed)
alphas
13.
nonBoundIs
nonzero((oS.alphas.A
*
(oS.alphas.A
C))[0]
14.
nonBoundIs:
15.
16.
non-bound,
17.
18.
False
#toggle
entire
set
loop
19.
elif
(alphaPairsChanged
==
0):
True
20.
iteration
number:
21.
return
oS.b,oS.alphas
下面演示一个小例子,手写识别。
(1)收集数据:
提供文本文件
(2)准备数据:
基于二值图像构造向量
(3)分析数据:
对图像向量进行目测
(4)训练算法:
采用两种不同的核函数,并对径向基函数采用不同的设置来运行SMO算法。
(5)测试算法:
编写一个函数来测试不同的核函数,并计算错误率
(6)使用算法:
一个图像识别的完整应用还需要一些图像处理的只是,此demo略。
完整代码如下:
1.from
numpy
import
2.from
time
sleep
4.def
loadDataSet(fileName):
dataMat
[];
labelMat
[]
fr
open(fileName)
line
fr.readlines():
lineArr
line.strip().split('
\t'
)
dataMat.append([float(lineArr[0]),
float(lineArr[1])])
labelMat.append(float(lineArr[2]))
dataMat,labelMat
13.def
selectJrand(i,m):
j=i
#we
want
to
select
any
J
not
equal
(j==i):
j
int(random.uniform(0,m))
19.def
clipAlpha(aj,H,L):
aj
H:
H
22.
L
aj:
23.
24.
25.
26.def
smoSimple(dataMatIn,
27.
dataMatrix
mat(dataMatIn);
mat(classLabels).transpose()
28.
b
0;
m,n
shape(dataMatrix)
29.
mat(zeros((m,1)))
30.
31.
32.
33.
range(m):
34.
fXi
float(multiply(alphas,labelMat).T*(dataMatrix*dataMatrix[i,:
].T))
+
35.
Ei
-
float(labelMat[i])#if
checks
an
example
violates
KKT
conditions
36.
((labelMat[i]*Ei
-toler)
(alphas[i]
C))
toler)
0)):
37.
selectJrand(i,m)
38.
fXj
float(multiply(alphas,labelMat).T*(dataMatrix*dataMatrix[j,:
39.
Ej
float(labelMat[j])
40.
alphaIold
alphas[i].copy();
alphaJold
alphas[j].copy();
41.
(labelMat[i]
!
labelMat[j]):
42.
max(0,
alphas[j]
alphas[i])
43.
min(C,
C
44.
45.
alphas[i]
C)
46.
47.
L==H:
L==H"
;
continue
48.
eta
2.0
dataMatrix[i,:
]*dataMatrix[j,:
].T
]*dataMatrix[i,:
dataMatrix[j,:
49.
0:
eta>
=0"
50.
-=
labelMat[j]*(Ei
Ej)/eta
51.
clipAlpha(alphas[j],H,L)
52.
(abs(alphas[j]
alphaJold)
0.00001):
moving
enough"
53.
labelMat[j]*labelMat[i]*(alphaJold
alphas[j])#update
by
the
same
amount
as
54.
#the
update
is
oppostie
direction
55.
b1
Ei-
labelMat[i]*(alphas[i]-alphaIold)*dataMatrix[i,:
labelMat[j]*(alphas[j]-alphaJold)*dataMatrix[i,:
56.
b2
Ej-
labelMat[j]*(alphas[j]-alphaJold)*dataMatrix[j,:
57.
(0
(C
alphas[i]):
58.
alphas[j])
alphas[j]):
59.
(b1
b2)/2.0
60.
61.
62.
63.
64.
65.
b,alphas
66.
67.def
kernelTrans(X,
A,
kTup):
#calc
kernel
transform
data
a
higher
dimensional
space
68.
shape(X)
69.
K
70.
kTup[0]=='
lin'
:
X
A.T
#linear
71.
rbf'
72.
73.
deltaRow
X[j,:
]
A
74.
K[j]
deltaRow*deltaRow.T
75.
exp(K/(-1*kTup[1]**2))
#divide
NumPy
element-wise
matrix
like
Matlab
76.
raise
NameError('
Houston
We
Have
Problem
--
\
77.
That
Kernel
recognized'
78.
79.
80.class
optStruct:
81.
def
__init__(self,dataMatIn,
#
Initialize
structure
with
parameters
82.
self.X
dataMatIn
83.
self.labelMat
classLabels
84.
self.C


- 配套讲稿:
如PPT文件的首页显示word图标,表示该PPT已包含配套word讲稿。双击word图标可打开word文档。
- 特殊限制:
部分文档作品中含有的国旗、国徽等图片,仅作为作品整体效果示例展示,禁止商用。设计者仅对作品中独创性部分享有著作权。
- 关 键 词:
- 支持 向量 Python 代码 实现
 冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 《JAVA编程基础》课程标准软件16级.docx
《JAVA编程基础》课程标准软件16级.docx
-
《分数的初步认识》.docx
-
《金属钠的性质与应用》教学设计.docx
-
《蚕妇》.docx
-
《会计》教材Word版第14章非货币性资产交换.docx
-
《与朱元思书》教学案例及反思.docx
-
《小壁虎借尾巴 》教案.docx
-
1第一部分 辅导员岗位基本知识.docx
-
09年CFO复习题.docx
-
2G1计算书.docx
-
17 古诗五首夜雨寄北一等奖教案.docx
-
240T15mw机组整体启动方案解析.docx
-
485总线设计方案加上位机扩展.docx
-
Aspose Word模板使用总结.docx
-
CDMA掉话分析.docx
-
C++新闻信息管理系统.docx
-
《HSE管理体系的策划与运行》.docx
-
c语言改错题及答案.docx
-
CMS7000使用说明资料.docx
-
《财经法规与会计职业道德》模拟卷考试试题及答案资料.docx
-
《大众传播媒介的更新》教案2.docx
-
《教育知识与能力》中学版全国教师资格考试复习资料教学教材.docx
-
EPC施工组织设计1.docx
-
ERP在服装行业的信息化应用可行性研究报告.docx
-
《项羽之死》教案人教版高二选修教学设计.docx
-
《公共关系实务》总复习资料.docx
-
FLUKE744过程校准仪经典实例免费给大家会让你未来的道路更通达.docx
-
《护士条例》试题.docx
-
2F男鞋统装规范84.docx
-
4测试用例修复方法与工具.docx
-
MC尼龙轮项目可行性研究报告.docx
-
Weblogic Server系统管理手册.docx
-
小学老师个人研修总结文档格式.docx
-
小学三年级上数学全部练习题Word格式文档下载.docx
-
线上线下商品配送系统设计文档格式.docx
-
中考化学试题分项版解析汇编第01期专题52化学方程Word格式.docx
-
整理吸气式烟雾探测火灾报警系统设计施工及验收规范DBJ01622Word格式.docx
-
湘教版二年级下册音乐教案全Word文档格式.docx
-
小学一般现在时和现在进行时练习题和答案Word格式文档下载.docx
-
太阳能灯具与普通灯具比较Word文件下载.docx
-
质量保证措施Word格式.docx
-
小学五年级数学教育工作心得总结最新Word格式文档下载.docx
-
淘宝大秒系统设计详解Word下载.docx
-
新人教版四年级语文下册期末练习题及答案2套Word文档格式.docx
-
小学生好词积累100个Word文件下载.docx
-
小学英语课堂教学流程Word格式文档下载.docx
-
消防安全管理制度以及消防安全检查记录Word文件下载.docx
-
天津市公需课国家和天津市十三五规划纲要解读答案003Word格式.docx
-
小学中秋活动方案Word文件下载.docx
-
小学生综合素质评价Word格式文档下载.docx
-
销售个人述职报告范文4篇Word下载.docx
