 数据结构编程题Word文档格式.docx
数据结构编程题Word文档格式.docx
- 文档编号:22638875
- 上传时间:2023-02-05
- 格式:DOCX
- 页数:25
- 大小:89.43KB
数据结构编程题Word文档格式.docx
《数据结构编程题Word文档格式.docx》由会员分享,可在线阅读,更多相关《数据结构编程题Word文档格式.docx(25页珍藏版)》请在冰豆网上搜索。
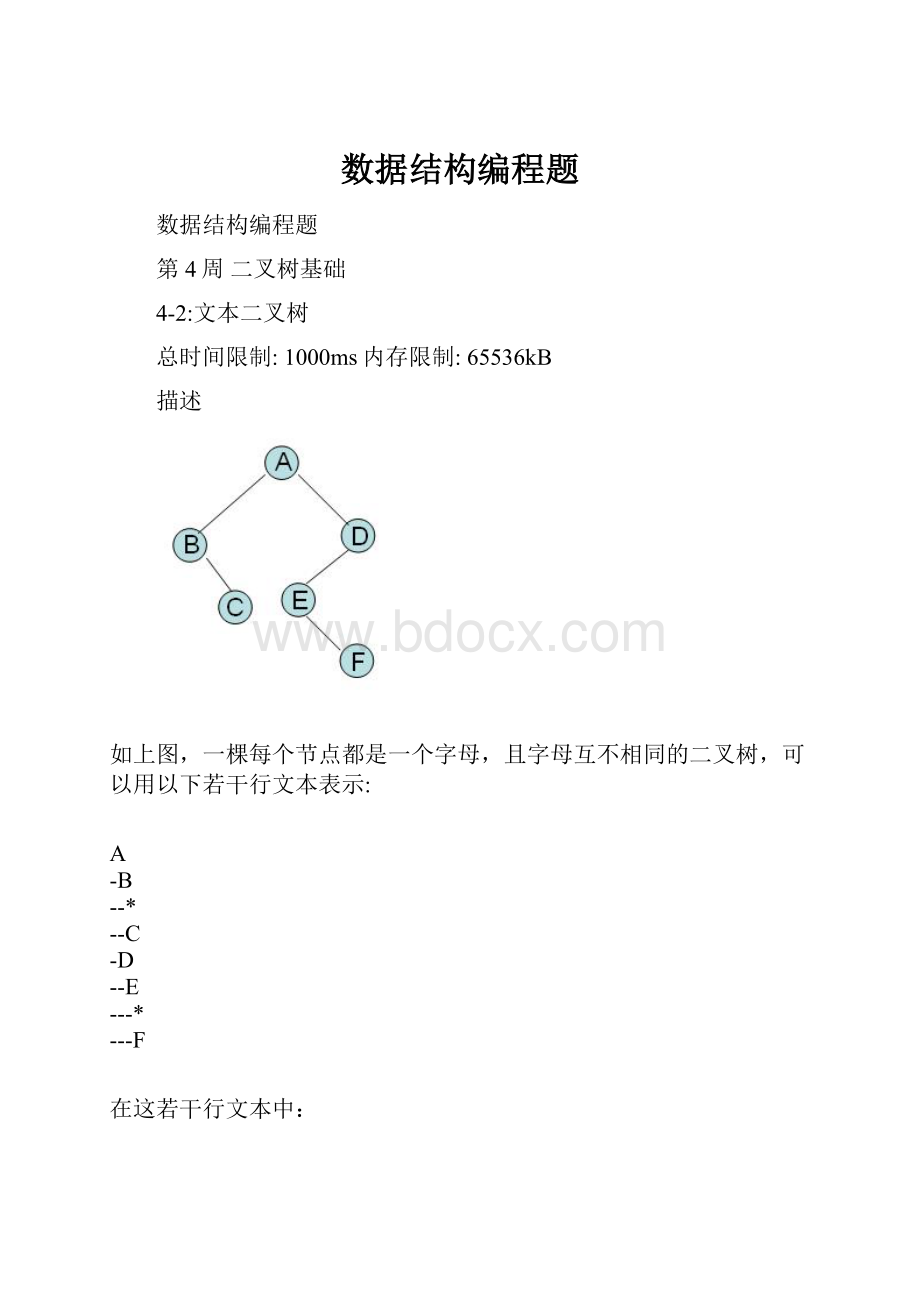
一行。
由输入中的中根序列和后根序列重建的二叉树的前根序列。
样例输入
953267
932675
596732
4-4:
表达式·
表达式树·
表达式求值
众所周知,任何一个表达式,都可以用一棵表达式树来表示。
例如,表达式a+b*c,可以表示为如下的表达式树:
+
/\
a*
bc
现在,给你一个中缀表达式,这个中缀表达式用变量来表示(不含数字),请你将这个中缀表达式用表达式二叉树的形式输出出来。
输入分为三个部分。
第一部分为一行,即中缀表达式。
中缀表达式可能含有小写字母代表变量(a-z),也可能含有运算符(+、-、*、/、小括号),不含有数字,也不含有空格。
第二部分为一个整数n,表示中缀表达式的变量数。
第三部分有n行,每行格式为C x,C为变量的字符,x为该变量的值。
输出分为三个部分,第一个部分为该表达式的逆波兰式,即该表达式树的后根遍历结果。
占一行。
第二部分为表达式树的显示,如样例输出所示。
如果该二叉树是一棵满二叉树,则最底部的叶子结点,分别占据横坐标的第1、3、5、7……个位置(最左边的坐标是1),然后它们的父结点的横坐标,在两个子结点的中间。
如果不是满二叉树,则没有结点的地方,用空格填充(但请略去所有的行末空格)。
每一行父结点与子结点中隔开一行,用斜杠(/)与反斜杠(\)来表示树的关系。
/出现的横坐标位置为父结点的横坐标偏左一格,\出现的横坐标位置为父结点的横坐标偏右一格。
也就是说,如果树高为m,则输出就有2m-1行。
第三部分为一个整数,表示将值代入变量之后,该中缀表达式的值。
需要注意的一点是,除法代表整除运算,即舍弃小数点后的部分。
同时,测试数据保证不会出现除以0的现象。
a+b*c
3
a2
b7
c5
abc*+
a*
37
第5周二叉树应用
5-1:
实现堆结构
3000ms内存限制:
定义一个数组,初始化为空。
在数组上执行两种操作:
1、增添1个元素,把1个新的元素放入数组。
2、输出并删除数组中最小的数。
使用堆结构实现上述功能的高效算法。
第一行输入一个整数t,代表测试数据的组数。
对于每组测试数据,第一行输入一个整数n,代表操作的次数。
每次操作首先输入一个整数type。
当type=1,增添操作,接着输入一个整数u,代表要插入的元素。
当type=2,输出删除操作,输出并删除数组中最小的元素。
1<
=n<
=100000。
每次删除操作输出被删除的数字。
2
5
11
12
13
4
15
17
1
提示
每组测试数据的复杂度为O(nlgn)的算法才能通过本次,否则会返回TLE(超时)
需要使用最小堆结构来实现本题的算法
5-2:
二叉搜索树
1024kB
二叉搜索树在动态查表中有特别的用处,一个无序序列可以通过构造一棵二叉搜索树变成一个有序序列,构造树的过程即为对无序序列进行排序的过程。
每次插入的新的结点都是二叉搜索树上新的叶子结点,在进行插入操作时,不必移动其它结点,只需改动某个结点的指针,由空变为非空即可。
这里,我们想探究二叉树的建立和序列输出。
只有一行,包含若干个数字,中间用空格隔开。
(数字可能会有重复)
输出一行,对输入数字建立二叉搜索树后进行前序周游的结果。
41467334500169724478358962464705145281827961491995942827436
41467334169145281358464436500478491724705962827961942995
5-3:
Huffman编码树
构造一个具有n个外部节点的扩充二叉树,每个外部节点Ki有一个Wi对应,作为该外部节点的权。
使得这个扩充二叉树的叶节点带权外部路径长度总和最小:
Min(W1*L1+W2*L2+W3*L3+…+Wn*Ln)
Wi:
每个节点的权值。
Li:
根节点到第i个外部叶子节点的距离。
编程计算最小外部路径长度总和。
对于每组测试数据,第一行输入一个整数n,外部节点的个数。
第二行输入n个整数,代表各个外部节点的权值。
2<
=N<
=100
输出最小外部路径长度总和。
123
1135
9
17
仅考查huffman树的建立,数据范围小,可以不需要使用堆结构.
不过鼓励使用第一题实现的堆来寻找最小和次小元素。
第6周树与森林
6-1:
物质分解记录
60000ms内存限制:
131064kB
对物质分解记录的结构进行统计分析。
例如:
给出一份物质分解记录。
Material_1
{
Material_2
Material_3
Material_4
Material_5
{
Material_6
Material_7
}
Material_8
}
Material_9
Material_10
Material_11
Material_l3
Material_7
Material_13
上述记录的含义是,Material_1分解为Material_2、Material_9和Material_10,Material_2又分解为Material_3、Material_4、Material_5和Material_8。
以此类推,大括号外书写特定物质名称,括号内表示此特定物质分解出来的子物质名称,每个子物质还可再分解。
现输入一个物质名称R,要求输出所有和物质R在记录中属于同一层次且位置在R之后的物质名称。
比如R=“Material_1”,则应该输出“Material_11”;
比如R=“Material_9”,则应该输出“Material_10”
如果R在代码中出现了多次,则以其第一次出现为准,即仅输出与第一次出现的R属于同一层次且位置在R之后的语句内容。
比如R=“Material_2”,则应该输出
Material_9
输入包含多组数据。
第一行是物质分解记录的份数,仅用一个整数表示。
从第二行开始,每组数据包括物质分解记录和所需查找的物质R两部分,物质分解记录样式如描述中所示,R的内容和物质分解记录之间有一行空行,下一份记录与上一个R之间有两行空行。
若输入!
则表示输入结束。
为简单起见,物质分解记录中每一行的内容为“{”或者“}”或者一个物质名称,不会有其他情况(比如空行)出现。
同时每行文字前不会有任何缩进。
物质名称是英文字母、数字和下划线组成的字符串。
对每组数据输出一行,如果R在记录中找到,则输出所有与R在同一层次且位置在R之后的物质名称,名称之间无需添加空格,紧密连接即可;
否则输出No。
若R是其所在层次中最后一个物质,则输出"
"
即输出一个空字符。
Material_4
Material_6
Material_8
Material_20
!
Material_9Material_10
No
读入数据时,需采用如下方式进行读取。
例:
若要读取一行输入内容,则
cin.getline(line,lineSize,'
\n'
);
sscanf(line,"
%s"
tmp);
其中line和tmp为数组指针,类型为char*,linesize为line所指向的数组的规模,为int型。
所需读取的内容最终是存储在tmp数组中。
之后如需对读取的内容进行操作,就对tmp进行操作即可,读到空行时tmp长度即为0。
采用其他方法读取可能会出现WA以及RE,TLE。
6-2:
树的转换
5000ms内存限制:
我们都知道用“左儿子右兄弟”的方法可以将一棵一般的树转换为二叉树,如:
00
/|\/
123===>
1
/\\
452
43
\
5
现在请你将一些一般的树用这种方法转换为二叉树,并输出转换前和转换后树的高度。
输入包括多行,最后一行以一个#表示结束。
每行是一个由“u”和“d”组成的字符串,表示一棵树的深度优先搜索信息。
比如,dudduduudu可以用来表示上文中的左树,因为搜索过程为:
0Downto1Upto0Downto2Downto4Upto2Downto5Upto2Upto0Downto3Upto0。
你可以认为每棵树的结点数至少为2,并且不超过10000。
对于每棵树,按如下格式输出转换前和转换后树的高度:
Treet:
h1=>
h2
其中t是树的编号(从1开始),h1是转换前树的高度,h2是转换后树的高度。
dudduduudu
ddddduuuuu
dddduduuuu
dddduuduuu
#
Tree1:
2=>
4
Tree2:
5=>
Tree3:
4=>
Tree4:
6-3:
宗教信仰
世界上有许多宗教,你感兴趣的是你学校里的同学信仰多少种宗教。
你的学校有n名学生(0<
n<
=50000),你不太可能询问每个人的宗教信仰,因为他们不太愿意透露。
但是当你同时找到2名学生,他们却愿意告诉你他们是否信仰同一宗教,你可以通过很多这样的询问估算学校里的宗教数目的上限。
你可以认为每名学生只会信仰最多一种宗教。
输入包括多组数据。
每组数据的第一行包括n和m,0<
=m<
=n(n-1)/2,其后m行每行包括两个数字i和j,表示学生i和学生j信仰同一宗教,学生被标号为1至n。
输入以一行n=m=0作为结束。
对于每组数据,先输出它的编号(从1开始),接着输出学生信仰的不同宗教的数目上限。
109
14
16
18
19
110
104
23
45
48
58
00
Case1:
Case2:
7
6-4:
电话号码
给你一些电话号码,请判断它们是否是一致的,即是否有某个电话是另一个电话的前缀。
比如:
Emergency911
Alice97625999
Bob91125426
在这个例子中,我们不可能拨通Bob的电话,因为Emergency的电话是它的前缀,当拨打Bob的电话时会先接通Emergency,所以这些电话号码不是一致的。
第一行是一个整数t,1≤t≤40,表示测试数据的数目。
每个测试样例的第一行是一个整数n,1≤n≤10000,其后n行每行是一个不超过10位的电话号码。
对于每个测试数据,如果是一致的输出“YES”,如果不是输出“NO”。
911
97625999
91125426
113
12340
123440
12345
98346
NO
YES
第7周图
7-1:
我爱北大
“红楼飞雪,一时英杰……”耳边传来了那熟悉的歌声。
而这,只怕是我最后一次听到这个声音了。
想当年,我们曾经怀着豪情壮志,许下心愿,走过静园,走过一体,走过未名湖畔的每个角落。
想当年,我们也曾慷慨高歌,瞻仰民主与科学,瞻仰博雅塔顶,那百年之前的遗韵。
没错,我爱北大,我爱这个校园。
然而,从当我们穿上学位服的那一刻起,这个校园,就再也不属于我。
它只属于往事,属于我的回忆。
没错,这,是我在北大的最后一日。
此时,此景,此生,此世,将刻骨难忘。
再也没有了图书馆自习的各种纷纭,再也没有了运动场上的挥汗如雨,有的,只是心中永远的不舍,与牵挂。
夜,已深。
人,却不愿离去。
天边有一颗流星划过,是那般静,宁谧。
忍不住不回头,我的眼边,有泪光,划过。
这时候,突然有一位路人甲从你身旁出现,问你:
从XX到XX怎么走?
索性,就让我再爱你一次。
因为,北大永远在你心中。
北大的地图,永远在你的心中。
轻手挥扬,不带走一分云彩。
第一个部分有P+1行,第一行为一个整数P,之后的P行表示北大的地点。
第二个部分有Q+1行,第一行为一个整数Q,之后的Q行每行分别为两个字符串与一个整数,表示这两点有直线的道路,并显示二者之间的矩离(单位为米)。
第三个部分有R+1行,第一行为一个整数R,之后的R行每行为两个字符串,表示需要求的路线。
p<
30,Q<
50,R<
20
输出有R行,分别表示每个路线最短的走法。
其中两个点之间,用->
(矩离)->
相隔
6
XueYiShiTang
CanYinZhongXin
XueWuShiTang
XueYiXiaoBaiFang
BaiNianJiangTang
GongHangQuKuanJi
XueYiShiTangCanYinZhongXin80
XueWuShiTangCanYinZhongXin40
XueYiShiTangXueYiXiaoBaiFang35
XueYiXiaoBaiFangXueWuShiTang85
CanYinZhongXinGongHangQuKuanJi60
GongHangQuKuanJiBaiNianJiangTang35
XueYiXiaoBaiFangBaiNianJiangTang
XueYiXiaoBaiFang->
(35)->
XueYiShiTang->
(80)->
CanYinZhongXin->
(60)->
GongHangQuKuanJi->
很O疼的一道题。
。
说出不少伤感事啊。
两个最短路的算法都是可以用的,可以视情况选择你习惯的那个算法。
7-2:
宝昌县长要修路
10000kB
宝昌县长意气风发,他决定整修之前县里的道路。
县里的道路很多,但维护费用昂贵。
具体如图A所示。
线段上面的数据表示两个节点之间的所需要的维修费用,现在需要对乡村进行道路优化,最基本的要求是将所有的村庄节点都要联通起来,并且要求每月的维护费用最小。
比如优化后的图如B所示。
第一行只包含一个表示村庄个数的数n,n不大于26,并且这n个村庄是由大写字母表里的前n个字母表示。
接下来的n-1行是由字母表的前n-1个字母开头。
最后一个村庄表示的字母不用输入。
对于每一行,以每个村庄表示的字母开头,然后后面跟着一个数字,表示有多少条道路可以从这个村到后面字母表中的村庄。
如果k是大于0,表示该行后面会表示k条道路的k个数据。
每条道路的数据是由表示连接到另一端村庄的字母和每月维修该道路的花费组成。
维修费用是正整数的并且小于100。
该行的所有数据字段分隔单一空白。
该公路网将始终连接所有的村庄。
该公路网将永远不会超过75条道路。
没有任何一个村庄会有超过15条的道路连接到其他村庄(之前或之后的字母)。
在下面的示例输入,数据是与上面的地图相一致的。
输出是一个整数,表示每个数据集中每月维持道路系统连接到所有村庄所花费的最低成本。
A2B12I25
B3C10H40I8
C2D18G55
D1E44
E2F60G38
F0
G1H35
H1I35
216
考虑看成最小生成树问题,注意输入表示。
7-3:
拓扑排序
10000ms内存限制:
1000kB
给出一个图的结构,输出其拓扑排序序列,要求在同等条件下,编号小的顶点在前
若干行整数,第一行有2个数,分别为顶点数v和弧数a,接下来有a行,每一行有2个数,分别是该条弧所关联的两个顶点编号
若干个空格隔开的顶点构成的序列(用小写字母)
68
32
35
64
65
v1v3v2v6v4v5
7-4:
地震之后
130000kB
2008年地震之后,坚强县受灾严重,该县通信线路也收到了致命的打击,县总部为了能够及时的向各村的发送消息,命令小强去解决一下这个问题。
小强经过调查发现,为了能够快速的实现通信,当务之急是能够建立起一条从总部可以向各个村单向发送信息的通信系统。
由于灾后情况紧急,不是每一个村之间都能够快速的建立起通信线路,只有有限的村比如村A和村B间可以建立单向的从A向B发送信息的通信线路,小强现在的问题就是要找出一个合适的方案,使从总部发送出的信息能够通到各村,而用的总的通信线路是最短的(毕竟情况危急,物质短缺)。
输入包括多组的测试数据。
对于每一组测试数据:
1、第一行包括两个整数N(1<
=100),M(M<
<
=10000),N表示通信网络中村子的数量,M表示在这些村子中,可以有M条通信线路建起来。
2、接下来N行,每行两个整数xi,yi,代表着这个村子的X轴,Y轴的坐标(xi,yi)
3、接下来M行,每行两个整数c1(1<
=c1<
=N),c2(1<
=c2<
=N),代表着从村c1到村c2可以建一个单向线路。
注:
两村之间的直线段距离(通信线路长度),即为两点间的欧式距离。
县总部所在的村假设都在编号为1的村。
输入以文件终止为结束。
对于每一组的测试数据,输出完全的一行,值为最短的总长度,结果保留两位小数。
如果不能建立一个单向的临时网络,输出"
NO"
.
46
36
34
720
31
43
10
41
19.49


- 配套讲稿:
如PPT文件的首页显示word图标,表示该PPT已包含配套word讲稿。双击word图标可打开word文档。
- 特殊限制:
部分文档作品中含有的国旗、国徽等图片,仅作为作品整体效果示例展示,禁止商用。设计者仅对作品中独创性部分享有著作权。
- 关 键 词:
- 数据结构 编程
 冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 1212中级汽车维修工考试试题三.docx
1212中级汽车维修工考试试题三.docx
-
333教育综合.docx
-
204届毕业生基础知识考试试题 混凝土结构设计 试题.docx
-
100以内加减运算练习题.docx
-
101软件开发工程师JAVA初级考试样卷课件word版本.docx
-
CNN代码理解.docx
-
CPA审计第4章审计抽样下载版讲解.docx
-
hr培训管理系统.docx
-
318安通科科长岗位责任制.docx
-
2044施工现场环境污染的防治措施.docx
-
12371党务平台操作手册.docx
-
Catia百格线生成宏复习过程.docx
-
725kV及以上电压等级支柱瓷绝缘子运行规范.docx
-
1144甑底链板机说明书.docx
-
100个著名初等数学问题.docx
-
201X中学寒假工作计划范文.docx
-
111 生物的特征 练习 人教版七年级上册生物.docx
-
110KV变电所设计变压器翻译.docx
-
9920第二学期学校工作总结.docx
-
0911二级技能解答.docx
-
33415设计说明书正文.docx
-
311教育学基础综合大纲.docx
-
201浙江普通高校招生选考科目考试地理试题和答案解析.docx
-
C语言程序的设计实验实验指导书及答案.docx
-
272相似三角形的性质和判定.docx
-
ACCAHA不稳定型心绞痛和非ST段抬高心肌梗死治疗指南修订版摘要.docx
-
baosteel标准对照 外标含量.docx
-
M1模拟练习题.docx
-
ARM体系课程设计实验报告.docx
-
Android面试题整理.docx
-
gaoer.docx
-
CPⅢ测设方案.docx
-
苯肼醛.docx
-
二项式定理学案及课后作业答案.docx
-
春节的作文600字八篇模板.docx
-
春季开学典礼国旗下发言稿.docx
-
第16届亚运会九龙湖高尔夫球会场馆清洁服务标准.docx
-
车辆行车事故故障应急预案.docx
-
部编版一年级上册语文全册总复习资料.docx
-
部编人教版三年级语文下册第11课《赵州桥》精品教案+同步习题.docx
-
崇川中学教师招聘考试真题含答案及部分解析.docx
-
法律权威思修课同名16616.docx
-
道路景观整治提升项目可行性研究报告.docx
-
福建省泉州市五年级下学期语文期中考试试题.docx
-
大型歌舞晚会策划文案.docx
-
大学生社会实践心得体会多篇1.docx
-
党风廉政建设形势分析会上的讲话1.docx
-
第二十届天原杯复赛试题及参考答案.docx
-
地下室监理细则.docx
-
高考平行志愿.docx
-
电能表.docx
