 数据挖掘Apriori算法Word格式文档下载.docx
数据挖掘Apriori算法Word格式文档下载.docx
- 文档编号:22406207
- 上传时间:2023-02-03
- 格式:DOCX
- 页数:20
- 大小:24.30KB
数据挖掘Apriori算法Word格式文档下载.docx
《数据挖掘Apriori算法Word格式文档下载.docx》由会员分享,可在线阅读,更多相关《数据挖掘Apriori算法Word格式文档下载.docx(20页珍藏版)》请在冰豆网上搜索。
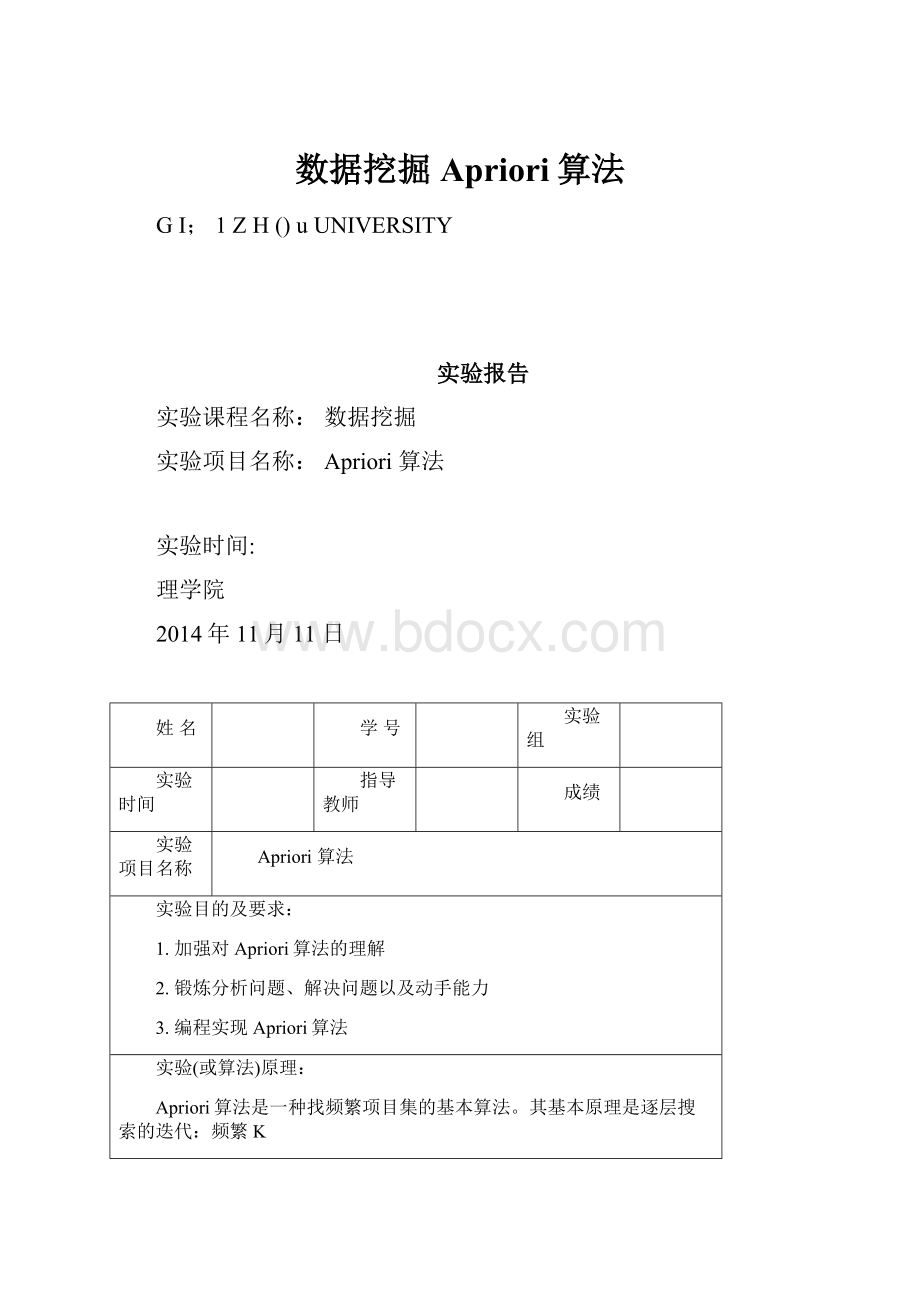
⑷for所有事务t€Ddobegin
(5)Ct=subset(Ck,t);
〃t中所包含的候选
(6)for所有候选c€Ctdo
(7)c.count++;
(8)end
(9)Lk={c€Ck|c.count>
minsupp}
(10)end
(11)key=ULk;
Apriori-gen函数:
1]Apriori候选产生函数Apriori-gen的参数Lk-1,即所有大型(k-1)项目集的集合。
匕返回所有大型k项目集的集合的一个超集(Superset)。
首先,在Jion(连接)步骤,我们把Lk-1和Lk-1相连接以获得候选的最终集合的一个超集Ck:
(1)insertintoCk
(2)selectp[1],p[2],……,p[k-1],q[k-1]
(3)fromLk-1p,Lk-1q
⑷wherep[1]=q[1],……,p[k-2]=q[k-2],p[k-1]<
q[k-
接着,在Prune(修剪)步骤,我们将删除所有的项目集c€Ck,如果c的一些k-1子
学生所在学院:
专业:
统计学
班级:
集不在Lk-1中,为了说明这个产生过程为什么能保持完全性,要注意对于Lk中的任
何有最小支持度的项目集,任何大小为k-1的子集也必须有最小支持度。
因此,如果
我们用所有可能的项目扩充Lk-1中的每个项目集,然后删除所有k-1子集不在Lk-1中的项目集,那么我们就能得到Lk中项目集的一个超集。
上面的合并运算相当于用数据库中所有项目来扩展Lk-1;
如果删除扩展项目集的第k-1
个项目后得到的k-1项目集不在Lk-1中,则删除该扩展项目集。
条件
P[k-1]<
q[k-1]保证不会出现相同的扩展项。
因此,经过合并运算,Ck>
Lh类似
原因在删除运算中,删除Ck中其k-1子项目集不在Lk-1中的项目集,同样没有删除包含在Lk中的项目集。
(1)for所有项目集c€Ckdo
⑵for所有c的(k-1)子集sdo
(3)if(sgLk-1)then
⑷从Ck中删除c
例如:
L3为{{123},{124},{134},{135},{234}}。
Jion步骤之后,C4为{{1234},{1345}}。
Prune步骤将删除项集{1345},因为项集{145}不在L3中。
Subset函数:
候选项目集Ck存储在一棵Hash树中。
Hash树的一个节点包含了项集的一个链表(一个叶节点)或包含了一个Hash表(一个内节点)。
在内节点中,Hash表的每个Bucket都指向另一个节点。
Hash树的根的深度定义为1。
在深度d的一个内节点指向深度d+1的节点。
项目集存储在叶子中。
要加载一个项目集c时,从根开始向下直到一个叶子。
在深度为d的一个内节点上,要决定选取哪个分枝,可以对此项目集的第d个项目使
用一个Hash函数,然后跟随相应Bucket中的指针。
所有的节点最初都创建成叶节点。
当一个叶节点中项集数量超过某个指定的阈值时,此叶节点就转为一个内节点。
从根节点开始,Subset函数寻找所有包含在某个事务t中的候选,方法如下:
若处于一个叶子,就寻找此叶子中的哪些项目集是包括在t中的,并对它们附加引用指向答
案集合。
若处于一个内节点,而且是通过Hash项目i从而到达此节点的,那么就对t
中i之后的每个项目进行Hash,并对相应Bucket中的节点递归地应用这个过程。
对于
根节点,就对t中的每个项目进行Hash。
尽管Apriori算法已经可以压缩候选数据项集Ck,但是对于频繁项集尤其是2维的候选数据项集产生仍然需要大量的存储空间。
也就是说对于2维的候选数据项集,Apriori算法的剪枝操作几乎不起任何作用。
1维高频数据项集L1的规模是0(n),则2维候选数据项集的规模将达到0(n2)。
如果我们考虑一般情况,即在没有支持度的情况下1维高频数据项集L1的规模是103,则2维候选数据项集的规模C2将达到C100O5X105.这种空间复杂度以指数形式的增长,使得这个经典的算法的执行效率很难让人满意.Apriori算法的两大缺点就是产生大量的候选集,以及需重复扫描数据
库。
实验硬件及软件平台:
Windows7VisualC++6.0
实验内容(包括实验具体内容、算法分析、源代码等等):
#include<
iostream>
string>
#include<
vector>
map>
#include<
algorithm>
usingnamespacestd;
classApriori
{
public:
Apriori(size_tis=0,unsignedintmv=0)
item_size=is;
min_value=mv;
}
〃~Apriori(){};
voidgetltem();
map<
vector<
unsignedint>
find_freitem();
〃求事务的频繁项
〃连接连个k-1级频繁项,得到第k级频繁项
string>
unsignedint>
apri_gen(unsignedintK,map<
K_item);
//展示频繁项集
voidshowAprioriltem(unsignedintK,map<
unsignedint>
showmap);
private:
int,vector<
>
item;
//存储所有最开始的事务及其项
K_item;
〃存储频繁项集
size_titem_size;
〃事务数目
unsignedintmin_value;
〃最小阈值
};
voidApriori:
:
getltem()〃用户输入最初的事务集
intci=item_size;
for(inti=0;
i<
ci;
i++)
stringstr;
vector<
temp;
cout<
<
"
请输入第"
i+1<
个事务的项集(wangend):
;
while(cin>
str&
&
str!
="
wang"
)
temp.push_back(str);
sort(temp.begin(),temp.end());
pair<
map<
int,vector<
iterator,bool>
ret=item.insert(make_pair(i+1,temp));
if(!
ret.second)
--i;
你输入的元素已存在!
请重新输入!
"
endl;
运行结果如下:
"
endl;
unsignedint>
Apriori:
find_freitem()
unsignedinti=1;
boolisEmpty=false;
iteratormit;
for(mit=item.begin();
mit!
=item.end();
mit++)
vec=mit->
second;
if(vec.size()!
=0)
break;
if(mit==item.end())〃事务集为空
isEmpty=true;
事务集为空!
程序无法进行..."
empty;
returnempty;
while
(1)
K_itemTemp=K_item;
K_item=apri_gen(i++,K_item);
if(K_itemTemp==K_item)
i=UINTMAX;
//判断是否需要进行下一次的寻找
pre_K_item=K_item;
size_tKitemsize=K_item.size();
//存储应该删除的第K级频繁项集,不能和其他K级频繁项集构成第K+1级项集的集合
if(Kitemsize!
=1&
i!
=1)
iterator>
eraseVecMit;
iteratorpre_K_item」t1=pre_K_item.begin(),
pre_K_item」t2;
while(pre_K_item」t1!
=pre_K_item.end())
iteratormit=pre_K_item_it1;
boolisExist=true;
vec1;
vec1=pre_K_item」t1->
first;
vec11(vec1.begin(),vec1.end()-1);
while(mit!
vec2;
vec2=mit->
vec22(vec2.begin(),vec2.end()-1);
if(vec11==vec22)
++mit;
if(mit==pre_K_item.end())
isExist=false;
if(!
isExist&
pre_K_item」t1!
=pre_K_item.end())eraseVecMit.push_back(pre_K_item_it1);
〃该第K级频繁项应该删除
++pre_K_item_it1;
size_teraseSetSize=eraseVecMit.size();
if(eraseSetSize==Kitemsize)
else
iteratorcurrentErs=eraseVecMit.begin();
while(currentErs!
=eraseVecMit.end())〃删除所有应该删除的第K级频繁项
iteratoreraseMit=*currentErs;
K_item.erase(eraseMit);
++currentErs;
if(Kitemsize==1)
showAprioriltem(i,K_item);
returnK_item;
apri_gen(unsignedintK,map<
unsigned
int>
K_item)
if(1==K)//求候选集C1
size_tc1=item_size;
iteratormapit=item.begin();
vec;
string,unsignedint>
c1_itemtemp;
while(mapit!
=item.end())//将原事务中所有的单项统计出来
temp=mapit->
iteratorvecit=temp.begin();
while(vecit!
=temp.end())
string,unsignedint>
iterator,bool>
ret=
c1_itemtemp.insert(make_pair(*vecit++,1));
++ret.first->
++mapit;
iteratoritem_it=c1_itemtemp.begin();
c1_item;
while(item」t!
=c1」temtemp.end())//构造第一级频繁项集
if(item_it->
second>
=min_value)
temp.push_back(item_it->
first);
c1_item.insert(make_pair(temp,item_it->
second));
++item」t;
returnc1_item;
showAprioriltem(K-1,K_item);
iteratorck_item」t1=K_item.begin(),ck_item」t2;
ck_item;
while(ck_item」t1!
=K_item.end())
ck_item」t2=ck_item」t1;
++ck_item_it2;
iteratormit=ck_item_it2;
//取当前第K级频繁项与其后面的第K级频繁项集联合,但要注意联合条件
//联合条件:
连个频繁项的前K-1项完全相同,只是第K项不同,然后两个联合生成
第K+1级候选频繁项
while(mit!
vec,vec1,vec2;
vec1=ck_item_it1->
iteratorvit1,vit2;
vit1=vec1.begin();
vit2=vec2.begin();
while(vit1<
vec1.end()&
vit2<
vec2.end())
stringstrl=*vit1;
stringstr2=*vit2;
++vit1;
++vit2;
if(K==2||stri==str2)
if(viti!
=veci.end()&
vit2!
=vec2.end())
vec.push_back(str1);
if(vitl==vecl.end()&
vit2==vec2.end())
--vit1;
--vit2;
stringstr1=*vit1;
if(str1>
str2)
vec.push_back(str2);
iteratorbase_item=item.begin();
unsignedintAcount=0;
while(base_item!
=item.end())//统计该K+1级候选项在原事务集出现次数{
unsignedintcount=0,mincount=UINT_MAX;
vv=base_item->
iteratorvecit,bvit;
for(vecit=vec.begin();
vecit<
vec.end();
vecit++)
stringt=*vecit;
count=0;
for(bvit=vv.begin();
bvit<
vv.end();
bvit++)
if(t==*bvit)
count++;
}mincount=(count<
mincount?
count:
mincount);
if(mincount>
=1&
mincount!
=UINTMAX)
Acount+=mincount;
++base_item;
if(Acount>
=min_value&
Acount!
sort(vec.begin(),vec.end());
//该第K+1级候选项为频繁项,插入频繁项集
ck_item.insert(make_pair(vec,Acount));
ret.second)
{ret.first->
second+=Acount;
++ck_item_it1;
if(ck_item.empty())//该第K+1级频繁项集为空,说明调用结束,把上一级频繁项集返回
returnck_item;
showAprioriltem(unsignedintK,map<
showmap)
iteratorshowit=showmap.begin();
if(K!
=UINT_MAX)
endl<
第"
K<
级频繁项集为:
最终的频繁项集为:
项集"
\t"
频率"
while(showit!
=showmap.end())
vec=showit->
iteratorvecit=vec.begin();
{"
=vec.end())
*vecit<
++vecit;
}"
\t"
showit->
second<
++showit;
unsignedintparseNumber(constchar*str)//对用户输入的数字进行判断和转换{
if(str==NULL)
return0;
unsignedintnum=0;
size_tlen=strlen(str);
for(size_ti=0;
len;
num*=10;
if(str[i]>
='
O'
&
str[i]<
=9)
num+=str[i]-'
returnnum;
voidmain()
//Aprioria;
unsignedintitemsize=0;
unsignedintmin;
do
请输入事务数:
char*str=newchar;
cin>
str;
itemsize=parseNumber(str);
if(itemsize==0)
请输入大于0正整数!


- 配套讲稿:
如PPT文件的首页显示word图标,表示该PPT已包含配套word讲稿。双击word图标可打开word文档。
- 特殊限制:
部分文档作品中含有的国旗、国徽等图片,仅作为作品整体效果示例展示,禁止商用。设计者仅对作品中独创性部分享有著作权。
- 关 键 词:
- 数据 挖掘 Apriori 算法
 冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 1212中级汽车维修工考试试题三.docx
1212中级汽车维修工考试试题三.docx
-
333教育综合.docx
-
204届毕业生基础知识考试试题 混凝土结构设计 试题.docx
-
100以内加减运算练习题.docx
-
101软件开发工程师JAVA初级考试样卷课件word版本.docx
-
CNN代码理解.docx
-
CPA审计第4章审计抽样下载版讲解.docx
-
hr培训管理系统.docx
-
318安通科科长岗位责任制.docx
-
2044施工现场环境污染的防治措施.docx
-
12371党务平台操作手册.docx
-
Catia百格线生成宏复习过程.docx
-
725kV及以上电压等级支柱瓷绝缘子运行规范.docx
-
1144甑底链板机说明书.docx
-
100个著名初等数学问题.docx
-
201X中学寒假工作计划范文.docx
-
111 生物的特征 练习 人教版七年级上册生物.docx
-
110KV变电所设计变压器翻译.docx
-
9920第二学期学校工作总结.docx
-
0911二级技能解答.docx
-
33415设计说明书正文.docx
-
311教育学基础综合大纲.docx
-
201浙江普通高校招生选考科目考试地理试题和答案解析.docx
-
C语言程序的设计实验实验指导书及答案.docx
-
272相似三角形的性质和判定.docx
-
ACCAHA不稳定型心绞痛和非ST段抬高心肌梗死治疗指南修订版摘要.docx
-
baosteel标准对照 外标含量.docx
-
M1模拟练习题.docx
-
ARM体系课程设计实验报告.docx
-
Android面试题整理.docx
-
gaoer.docx
-
CPⅢ测设方案.docx
-
UnitWhatshouldIdo000002.docx
-
VxWorks启动过程描述.docx
-
XX乡镇综合文化站建设规划项目可行性研究报告.docx
-
新增硕士专业学位授权点基本条件.docx
-
信息技术应用研修计划.docx
-
物业管理知识100问.docx
-
绚烂的视觉插画 创新时代 网供稿 插画欣赏.docx
-
学考 遗传的染色体学说伴性遗传.docx
-
西交《建筑制图》在线作业.docx
-
西游记》中的教育思想.docx
-
学年四川省广安市邻水县高一下学期第一次月考英语试题.docx
-
夏天坐月子 夏季坐月子有哪些注意事项.docx
-
县委政法委20xx年工作汇报材料.docx
-
压风自救系统管理制度.docx
-
盐的运输问题.docx
-
新版小学五年级英语下册全教案课程带反思.docx
-
新版外研社六年级上册英语一年级起点课文文本M15编辑版.docx
-
苏教版四年级语文下册全册教案表格式.docx
-
四年级课外阅读练习精选30题 II.docx
