 遗传算法及优化问题重要有代码Word文档下载推荐.docx
遗传算法及优化问题重要有代码Word文档下载推荐.docx
- 文档编号:21021878
- 上传时间:2023-01-27
- 格式:DOCX
- 页数:18
- 大小:84.25KB
遗传算法及优化问题重要有代码Word文档下载推荐.docx
《遗传算法及优化问题重要有代码Word文档下载推荐.docx》由会员分享,可在线阅读,更多相关《遗传算法及优化问题重要有代码Word文档下载推荐.docx(18页珍藏版)》请在冰豆网上搜索。
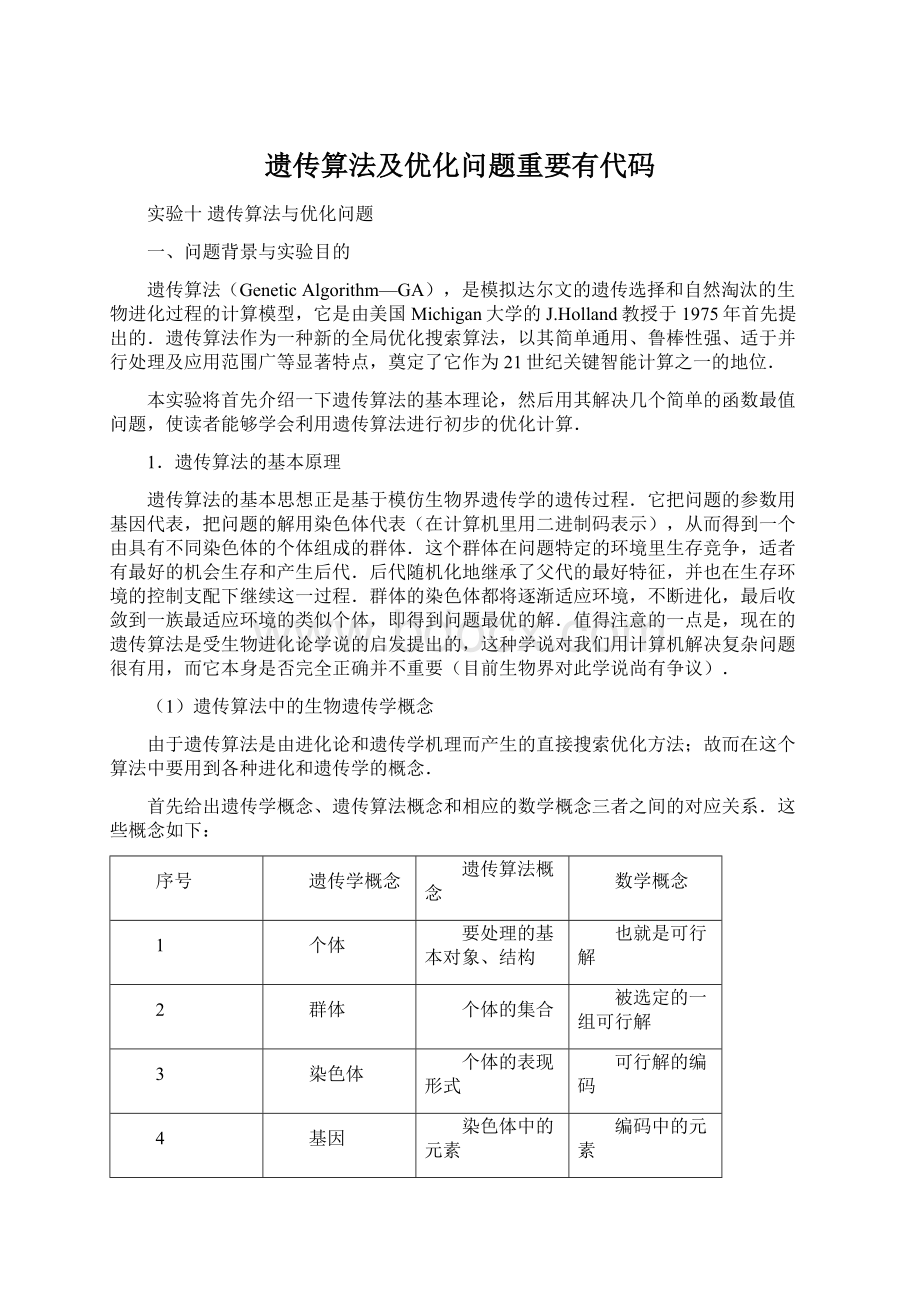
适应值
个体对于环境的适应程度,或在环境压力下的生存能力
可行解所对应的适应函数值
7
种群
被选定的一组染色体或个体
根据入选概率定出的一组可行解
8
选择
从群体中选择优胜的个体,淘汰劣质个体的操作
保留或复制适应值大的可行解,去掉小的可行解
9
交叉
一组染色体上对应基因段的交换
根据交叉原则产生的一组新解
10
交叉概率
染色体对应基因段交换的概率(可能性大小)
闭区间[0,1]上的一个值,一般为0.65~0.90
11
变异
染色体水平上基因变化
编码的某些元素被改变
12
变异概率
染色体上基因变化的概率(可能性大小)
开区间(0,1)内的一个值,一般为0.001~0.01
13
进化、
适者生存
个体进行优胜劣汰的进化,一代又一代地优化
目标函数取到最大值,最优的可行解
(2)遗传算法的步骤
遗传算法计算优化的操作过程就如同生物学上生物遗传进化的过程,主要有三个基本操作(或称为算子):
选择(Selection)、交叉(Crossover)、变异(Mutation).
遗传算法基本步骤主要是:
先把问题的解表示成“染色体”,在算法中也就是以二进制编码的串,在执行遗传算法之前,给出一群“染色体”,也就是假设的可行解.然后,把这些假设的可行解置于问题的“环境”中,并按适者生存的原则,从中选择出较适应环境的“染色体”进行复制,再通过交叉、变异过程产生更适应环境的新一代“染色体”群.经过这样的一代一代地进化,最后就会收敛到最适应环境的一个“染色体”上,它就是问题的最优解.
下面给出遗传算法的具体步骤,流程图参见图1:
第一步:
选择编码策略,把参数集合(可行解集合)转换染色体结构空间;
第二步:
定义适应函数,便于计算适应值;
第三步:
确定遗传策略,包括选择群体大小,选择、交叉、变异方法以及确定交叉概率、变异概率等遗传参数;
第四步:
随机产生初始化群体;
第五步:
计算群体中的个体或染色体解码后的适应值;
第六步:
按照遗传策略,运用选择、交叉和变异算子作用于群体,形成下一代群体;
第七步:
判断群体性能是否满足某一指标、或者是否已完成预定的迭代次数,不满足则返回第五步、或者修改遗传策略再返回第六步.
图1一个遗传算法的具体步骤
遗传算法有很多种具体的不同实现过程,以上介绍的是标准遗传算法的主要步骤,此算法会一直运行直到找到满足条件的最优解为止.
2.遗传算法的实际应用
例1:
设
,求
.
注:
这是一个非常简单的二次函数求极值的问题,相信大家都会做.在此我们要研究的不是问题本身,而是借此来说明如何通过遗传算法分析和解决问题.
在此将细化地给出遗传算法的整个过程.
(1)编码和产生初始群体
首先第一步要确定编码的策略,也就是说如何把
到2这个区间内的数用计算机语言表示出来.
编码就是表现型到基因型的映射,编码时要注意以下三个原则:
完备性:
问题空间中所有点(潜在解)都能成为GA编码空间中的点(染色体位串)的表现型;
健全性:
GA编码空间中的染色体位串必须对应问题空间中的某一潜在解;
非冗余性:
染色体和潜在解必须一一对应.
这里我们通过采用二进制的形式来解决编码问题,将某个变量值代表的个体表示为一个{0,1}二进制串.当然,串长取决于求解的精度.如果要设定求解精度到六位小数,由于区间长度为
,则必须将闭区间
分为
等分.因为
所以编码的二进制串至少需要22位.
将一个二进制串(b21b20b19…b1b0)转化为区间
内对应的实数值很简单,只需采取以下两步(Matlab程序参见附录4):
1)将一个二进制串(b21b20b19…b1b0)代表的二进制数化为10进制数:
2)
对应的区间
内的实数:
例如,一个二进制串a=<
1000111>
表示实数0.637197.
=(1000111)2=2288967
二进制串<
0000000000000000000000>
,<
1111111>
,则分别表示区间的两个端点值-1和2.
利用这种方法我们就完成了遗传算法的第一步——编码,这种二进制编码的方法完全符合上述的编码的三个原则.
首先我们来随机的产生一个个体数为4个的初始群体如下:
pop
(1)={
<
0011110>
,%%a1
1000010>
,%%a2
0000000>
,%%a3
0010101>
}%%a4(Matlab程序参见附录2)
化成十进制的数分别为:
pop
(1)={1.523032,0.574022,-0.697235,0.247238}
接下来我们就要解决每个染色体个体的适应值问题了.
(2)定义适应函数和适应值
由于给定的目标函数
在
内的值有正有负,所以必须通过建立适应函数与目标函数的映射关系,保证映射后的适应值非负,而且目标函数的优化方向应对应于适应值增大的方向,也为以后计算各个体的入选概率打下基础.
对于本题中的最大化问题,定义适应函数
,采用下述方法:
式中
既可以是特定的输入值,也可以是当前所有代或最近K代中
的最小值,这里为了便于计算,将采用了一个特定的输入值.
若取
,则当
时适应函数
;
当
由上述所随机产生的初始群体,我们可以先计算出目标函数值分别如下(Matlab程序参见附录3):
f[pop
(1)]={1.226437,1.318543,-1.380607,0.933350}
然后通过适应函数计算出适应值分别如下(Matlab程序参见附录5、附录6):
取
,
g[pop
(1)]={2.226437,2.318543,0,1.933350}
(3)确定选择标准
这里我们用到了适应值的比例来作为选择的标准,得到的每个个体的适应值比例叫作入选概率.其计算公式如下:
对于给定的规模为n的群体pop={
},个体
的适应值为
,则其入选概率为
由上述给出的群体,我们可以计算出各个个体的入选概率.
首先可得
然后分别用四个个体的适应值去除以
,得:
P(a1)=2.226437/6.478330=0.343675%%a1
P(a2)=2.318543/6.478330=0.357892%%a2
P(a3)=0/6.478330=0%%a3
P(a4)=1.933350/6.478330=0.298433%%a4(Matlab程序参见附录7)
(4)产生种群
计算完了入选概率后,就将入选概率大的个体选入种群,淘汰概率小的个体,并用入选概率最大的个体补入种群,得到与原群体大小同样的种群(Matlab程序参见附录8、附录11).
要说明的是:
附录11的算法与这里不完全相同.为保证收敛性,附录11的算法作了修正,采用了最佳个体保存方法(elitistmodel),具体内容将在后面给出介绍.
由初始群体的入选概率我们淘汰掉a3,再加入a2补足成与群体同样大小的种群得到newpop
(1)如下:
newpop
(1)={
}%%a4
(5)交叉
交叉也就是将一组染色体上对应基因段的交换得到新的染色体,然后得到新的染色体组,组成新的群体(Matlab程序参见附录9).
我们把之前得到的newpop
(1)的四个个体两两组成一对,重复的不配对,进行交叉.(可以在任一位进行交叉)
011110>
,<
交叉得:
010>
01010001000010>
011011>
0000010>
通过交叉得到了四个新个体,得到新的群体jchpop
(1)如下:
jchpop
(1)={
}
这里采用的是单点交叉的方法,当然还有多点交叉的方法,不过有些烦琐,这里就不着重介绍了.
(6)变异
变异也就是通过一个小概率改变染色体位串上的某个基因(Matlab程序参见附录10).
现把刚得到的jchpop
(1)中第3个个体中的第9位改变,就产生了变异,得到了新的群体pop
(2)如下:
pop
(2)={
}
然后重复上述的选择、交叉、变异直到满足终止条件为止.
(7)终止条件
遗传算法的终止条件有两类常见条件:
(1)采用设定最大(遗传)代数的方法,一般可设定为50代,此时就可能得出最优解.此种方法简单易行,但可能不是很精确(Matlab程序参见附录1);
(2)根据个体的差异来判断,通过计算种群中基因多样性测度,即所有基因位相似程度来进行控制.
3.遗传算法的收敛性
前面我们已经就遗传算法中的编码、适应度函数、选择、交叉和变异等主要操作的基本内容及设计进行了详细的介绍.作为一种搜索算法,遗传算法通过对这些操作的适当设计和运行,可以实现兼顾全局搜索和局部搜索的所谓均衡搜索,具体实现见下图2所示.
图2均衡搜索的具体实现图示
应该指出的是,遗传算法虽然可以实现均衡的搜索,并且在许多复杂问题的求解中往往能得到满意的结果,但是该算法的全局优化收敛性的理论分析尚待解决.目前普遍认为,标准遗传算法并不保证全局最优收敛.但是,在一定的约束条件下,遗传算法可以实现这一点.
下面我们不加证明地罗列几个定理或定义,供读者参考(在这些定理的证明中,要用到许多概率论知识,特别是有关马尔可夫链的理论,读者可参阅有关文献).
定理1如果变异概率为
,交叉概率为
,同时采用比例选择法(按个体适应度占群体适应度的比例进行复制),则标准遗传算法的变换矩阵P是基本的.
定理2标准遗传算法(参数如定理1)不能收敛至全局最优解.
由定理2可以知道,具有变异概率
以及按比例选择的标准遗传算法是不能收敛至全局最最优解.我们在前面求解例1时所用的方法就是满足定理1的条件的方法.这无疑是一个令人沮丧的结论.
然而,庆幸的是,只要对标准遗传算法作一些改进,就能够保证其收敛性.具体如下:
我们对标准遗传算法作一定改进,即不按比例进行选择,而是保留当前所得的最优解(称作超个体).该超个体不参与遗传.
最佳个体保存方法(elitistmodel)的思想是把群体中适应度最高的个体不进行配对交叉而直接复制到下一代中.此种选择操作又称复制(copy).DeJong对此方法作了如下定义:
定义设到时刻t(第t代)时,群体中a*(t)为最佳个体.又设A(t+1)为新一代群体,若A(t+1)中不存在a*(t),则把a*(t)作为A(t+1)中的第n+1个个体(其中,n为群体大小)(Matlab程序参见附录11).
采用此选择方法的优点是,进化过程中某一代的最优解可不被交叉和变异操作所破坏.但是,这也隐含了一种危机,即局部最优个体的遗传基因会急速增加而使进化有可能限于局部解.也就是说,该方法的全局搜索能力差,它更适合单峰性质的搜索空间搜索,而不是多峰性质的空间搜索.所以此方法一般都与其他选择方法结合使用.
定理3具有定理1所示参数,且在选择后保留当前最优值的遗传算法最终能收敛到全局最优解.
当然,在选择算子作用后保留当前最优解是一项比较复杂的工作,因为该解在选择算子作用后可能丢失.但是定理3至少表明了这种改进的遗传算法能够收敛至全局最优解.有意思的是,实际上只要在选择前保留当前最优解,就可以保证收敛,定理4描述了这种情况.
定理4具有定理1参数的,且在选择前保留当前最优解的遗传算法可收敛于全局最优解.
例2:
,编码长度为5,采用上述定理4所述的“在选择前保留当前最优解的遗传算法”进行.
此略,留作练习.
二、相关函数(命令)及简介
本实验的程序中用到如下一些基本的Matlab函数:
ones,zeros,sum,size,length,subs,double等,以及for,while等基本程序结构语句,读者可参考前面专门关于Matlab的介绍,也可参考其他数学实验章节中的“相关函数(命令)及简介”内容,此略.
三、实验内容
上述例1的求解过程为:
群体中包含六个染色体,每个染色体用22位0—1码,变异概率为0.01,变量区间为
,取Fmin=
,遗传代数为50代,则运用第一种终止条件(指定遗传代数)的Matlab程序为:
[Count,Result,BestMember]=Genetic1(22,6,'
-x*x+2*x+0.5'
-1,2,-2,0.01,50)
执行结果为:
Count=
50
Result=
1.03161.03161.03161.03161.03161.0316
1.49901.49901.49901.49901.49901.4990
BestMember=
1.0316
1.4990
图2例1的计算结果
(注:
上图为遗传进化过程中每一代的个体最大适应度;
而下图为目前为止的个体最大适应度——单调递增)
我们通过Matlab软件实现了遗传算法,得到了这题在第一种终止条件下的最优解:
取1.0316时,
当然这个解和实际情况还有一点出入(应该是
取1时,
),但对于一个计算机算法来说已经很不错了.
我们也可以编制Matlab程序求在第二种终止条件下的最优解.此略,留作练习.实践表明,此时的遗传算法只要经过10代左右就可完成收敛,得到另一个“最优解”,与前面的最优解相差无几.
四、自己动手
1.用Matlab编制另一个主程序Genetic2.m,求例1的在第二种终止条件下的最优解.
提示:
一个可能的函数调用形式以及相应的结果为:
[Count,Result,BestMember]=Genetic2(22,6,'
-1,2,-2,0.01,0.00001)
13
1.03921.03921.03921.03921.03921.0392
1.49851.49851.49851.49851.49851.4985
1.0392
1.4985
可以看到:
两组解都已经很接近实际结果,对于两种方法所产生的最优解差异很小.可见这两种终止算法都是可行的,而且可以知道对于例1的问题,遗传算法只要经过10代左右就可以完成收敛,达到一个最优解.
2.按照例2的具体要求,用遗传算法求上述例2的最优解.
3.附录9子程序Crossing.m中的第3行到第7行为注解语句.若去掉前面的%号,则程序的算法思想有什么变化?
4.附录9子程序Crossing.m中的第8行至第13行的程序表明,当Dim
(1)>
=3时,将交换数组Population的最后两行,即交换最后面的两个个体.其目的是什么?
5.仿照附录10子程序Mutation.m,修改附录9子程序Crossing.m,使得交叉过程也有一个概率值(一般取0.65~0.90);
同时适当修改主程序Genetic1.m或主程序Genetic2.m,以便代入交叉概率.
6.设
,要设定求解精度到15位小数.
五、附录
附录1:
主程序Genetic1.m
function[Count,Result,BestMember]=Genetic1(MumberLength,MemberNumber,FunctionFitness,MinX,MaxX,Fmin,MutationProbability,Gen)
Population=PopulationInitialize(MumberLength,MemberNumber);
globalCount;
globalCurrentBest;
Count=1;
PopulationCode=Population;
PopulationFitness=Fitness(PopulationCode,FunctionFitness,MinX,MaxX,MumberLength);
PopulationFitnessF=FitnessF(PopulationFitness,Fmin);
PopulationProbability=Probability(PopulationFitnessF);
[Population,CurrentBest,EachGenMaxFitness]=Elitist(PopulationCode,PopulationFitness,MumberLength);
EachMaxFitness(Count)=EachGenMaxFitness;
MaxFitness(Count)=CurrentBest(length(CurrentBest));
whileCount<
Gen
NewPopulation=Select(Population,PopulationProbability,MemberNumber);
Population=NewPopulation;
NewPopulation=Crossing(Population,FunctionFitness,MinX,MaxX,MumberLength);
NewPopulation=Mutation(Population,MutationProbability);
PopulationFitness=Fitness(Population,FunctionFitness,MinX,MaxX,MumberLength);
PopulationFitnessF=FitnessF(PopulationFitness,Fmin);
PopulationProbability=Probability(PopulationFitnessF);
Count=Count+1;
[NewPopulation,CurrentBest,EachGenMaxFitness]=Elitist(Population,PopulationFitness,MumberLength);
EachMaxFitness(Count)=EachGenMaxFitness;
;
MaxFitness(Count)=CurrentBest(length(CurrentBest));
end
Dim=size(Population);
Result=ones(2,Dim
(1));
fori=1:
Dim
(1)
Result(1,i)=Translate(Population(i,:
),MinX,MaxX,MumberLength);
Result(2,:
)=PopulationFitness;
BestMember(1,1)=Translate(CurrentBest(1:
MumberLength),MinX,MaxX,MumberLength);
BestMember(2,1)=CurrentBest(MumberLength+1);
closeall
subplot(211)
plot(EachMaxFitness)
subplot(212)
plot(MaxFitness)
【程序说明】主程序Genetic1.m包含了8个输入参数:
(1)MumberLength:
表示一个染色体位串的二进制长度.(例1中取22)
(2)MemberNumber:
表示群体中染色体的个数.(例1中取6个)
(3)FunctionFitness:
表示目标函数,是个字符串,因此用表达式时,用单引号括出.(例1中是
)
(4)MinX:
变量区间的下限.(例1中是
中的)
(5)MaxX:
变量区间的上限.(例1中是
中的2)
(6)Fmin:
定义适应函数过程中给出的一个目标函数的可能的最小值,由操作者自己给出.(例1中取Fmin=
(7)MutationProbability:
表示变异的概率,一般都很小.(例1中取0.01)
(8)Gen:
表示遗传的代数,也就是终止程序时的代数.(例1中取50)
另外,主程序Genetic1.m包含了3个输出值:
Count表示遗传的代数;
Result表示计算的结果,也就是最优解;
BestMember表示最优个体及其适应值.
附录2:
子程序PopulationInitialize.m
functionPopulation=PopulationInitialize(MumberLength,MemberNumber)
Temporary=rand(MemberNumber,MumberLength);
Population=(Temporary>
=0.5*ones(size(Temporary)));
【程序说明】子程序PopulationInitialize.m用于产生一个初始群体.这个初始群体含有MemberNumber个染色体,每个染色体有MumberLength个基因(二进制码).
附录3:
子程序Fitness.m
f


- 配套讲稿:
如PPT文件的首页显示word图标,表示该PPT已包含配套word讲稿。双击word图标可打开word文档。
- 特殊限制:
部分文档作品中含有的国旗、国徽等图片,仅作为作品整体效果示例展示,禁止商用。设计者仅对作品中独创性部分享有著作权。
- 关 键 词:
- 遗传 算法 优化 问题 重要 代码
 冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 铝散热器项目年度预算报告.docx
铝散热器项目年度预算报告.docx
-
牛津上海版通用小学英语三年级上册Unit 12同步练习2II 卷.docx
-
论我国私营企业员工激励机制.docx
-
人教版五年级品德与社会上册全册教案.docx
-
开学啦国旗下讲话稿三分钟.docx
-
露天采矿学复习题.docx
-
六年级英语教师年度考核个人总结.docx
-
某路站综合体项PC吊装施工方案.docx
-
人教版九年级历史上册期末考试试题一套.docx
-
隆昌妇幼保健院.docx
-
芦二矿抽采达标中长期规划.docx
-
看拼音写词语.docx
-
模拟磁盘调度算法系统的设计毕业设计.docx
-
每周一条名言警句或一首诗词.docx
-
棉花膜下滴灌示范工程设计总结报告.docx
-
九年级化学教案第十单元酸和碱教案新人教版.docx
-
宁波市水资源公报.docx
-
农业实用技术培训工作意见与农业局上半年工作总结范例两篇汇编.docx
-
平行线的判定.docx
-
内部会计管理制度11成本核算制度.docx
-
盘扣式脚手架支撑方案.docx
-
旅游规划模板.docx
-
煤矿大本大专毕业设计大采高综采工作面作业规程.docx
-
美学选择题整理课件资料.docx
-
名家论腹泻慢性肠炎.docx
-
宁夏银川市第一中学学年高一上学期期中考试地理试题解析解析版.docx
-
年产吨精密纤维纸项目建设建议书.docx
-
农技推广中心工作总结.docx
-
彭宇案的法逻辑批判.docx
-
宁夏仕奇房产网发布份房地产交易情况.docx
-
项目推荐书智能温控节能系统.docx
-
区县节日期间加强消防安全讲话稿与区发改委领导班子述职述廉报告汇编.docx
-
最新届高考英语 Unit24 Society 北师大版选修8 精品.docx
-
马聪敏 汇编实验报告.docx
-
企业工作计划4篇.docx
-
山东省日照青山学校学年高一份月考英语试题.docx
-
版中国金属表面处理及热处理加工行业发展研究报告.docx
-
最新自查报告范本模板人力社保局防腐败机制建设自查报告.docx
-
个人表现自评描述.docx
-
淘宝网全新正品金士顿商城公然卖假货.docx
-
信访条例知识竞赛题附答案.docx
-
学校安全教育主题.docx
-
六年级英语下册Recycle.docx
-
傅雷家书读后感800字.docx
-
护士资格考点精华总结.docx
-
《教育心理学》复习提纲汇总.docx
-
学校扫盲工作总结.docx
-
网络经济的超边际分析网络经济对经济学的挑战.docx
-
设备安装工程环境因素识别评价表.docx
-
部门自检自查报告精选6篇.docx
-
阳泉市示范高中沉降观测施工方案.docx
