 J数据库查询语言Word格式.docx
J数据库查询语言Word格式.docx
- 文档编号:21013035
- 上传时间:2023-01-26
- 格式:DOCX
- 页数:21
- 大小:293.67KB
J数据库查询语言Word格式.docx
《J数据库查询语言Word格式.docx》由会员分享,可在线阅读,更多相关《J数据库查询语言Word格式.docx(21页珍藏版)》请在冰豆网上搜索。
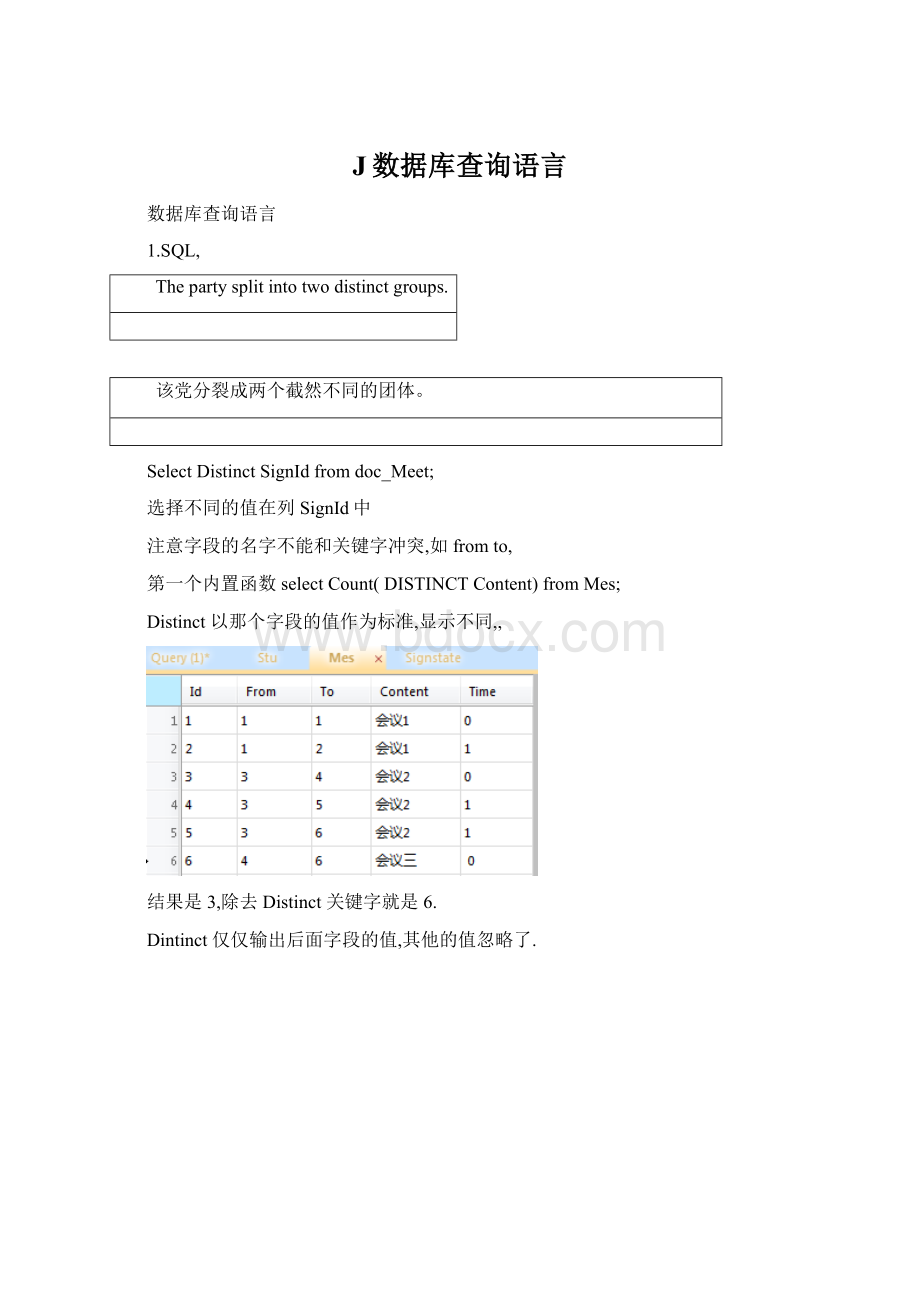
默认是从小到大,descending从大到小
等同于orderbySalesDESC.,,,
Like关键字,同inbetween平行,表示模糊查询,
“A_B”表示匹配三个字符,开头结尾是A,B
此时无法匹配,会”议”2
要匹配它时候注意用单引号
尽量在表格中不要填入单双引号
WhereContentlike'
%会'
表示任意以会字结尾的
;
'
%会%'
中间是”会”字的
会%'
,,,,打头的
下划线匹配一个字符
我们选择数据总是以列的值作为参考,计数是计算行的总数,函数也是计算符合条件的
Max(),Min(),Count(),AVG(平均值),SUM()最大最小值,
还支持运算符,+-*/,对于字符串也支持一些运算.
下面看分组,groupby,表示依照值的内容若相同则列为一组,
SelectCount(Content)
groupbyContent
orderbyid;
分了五组,前4个id两两行一组,后因为内容不同各自三组,依照id排序,发现我们的返回的是一个系列的值,因为有很多个Content,,,,,,人为的将表,打散为若干个行,但是表头不变,
如果有很多表的Content表的值为null那么就统一的算一个因为null==null
Groupby有一个原则就是select后面的所有列中没有使用聚合函数的列,必须出现在groupby后面!
排除了哪些使用聚合函数的字段名字,其他的都作为分组标准
一个query.config的一条查询语句是:
使用了链接就可能出现多条主键id,如果主表记录和附表是一对多关系。
<
queryid="
file.signCount"
field="
DISTINCTdoc_File.Id,COUNT(doc_File.Id)ascount"
orderby="
-doc_File.CreateTime"
allowedOrderbyColumns="
doc_File.CreateTime"
>
!
[CDATA[
INNERJOINdoc_SigningONdoc_File.Id=doc_Signing.ObjId
WHEREdoc_Signing.Type=0anddoc_File.Creatorid='
$!
jc.username'
groupbydoc_File.Id,doc_File.CreateTime
]]>
/query>
可以发现orderby字段也要出现在我们的groupby中,distinct关键字是为了防止多个doc_Signing.ObjId
对应一个doc_File.Id,,,那么最终内联的结果就是出现了多个Id
看到两个96,一条公文产生多个签收条目。
比如我想知道一个班级同龄人的个数,那么
Selectage,Count(id)as同龄人个数fromStu
groupbyage
as 表示显示的列名字,是个临时的名字
where子句的作用是在对查询结果进行分组前,将不符合条件的行去掉,(去行)
,select可以去掉你不想看到的列,在分组之前过滤数据,(择列)
having子句的作用是赛选满足条件的组,再分组之后过滤数据,条件中经常包含聚合函数,使用having条件显示特定的组,也可以使用多个分组标准进行分组,groupby又优先于orderby
如果我们想要找出同龄人数超过三个的
Selectage,count(id)as同龄个数fromStu
havingCount(age)>
2,,,只看超过两个以上同龄人
每当age的值相同就会并为一组,统计每组的count(id)个数,有多少个不同的age就会产生多少个不同行,
Select SignId,Count(ID)AS unsignNum from Signing
gruop by SingnId
where IsSign=0
order by id;
如果我们表的名字不理想,可以使用别名,就是from后面加一个名字就是别名
SelectStudent.age,count(id)as同龄个数
fromStuStudent
groupbyStudent.age
havingCount(Student.age)>
2
也可以链接两个表的时候字段重名的冲突,一个表的时候也可以定义别名但是不使用
之前的as也是表示别名的意思.
用字段链接两个表;
select*
fromSignStatEs,stustu
wheres.MesID=stu.ID
这里就是左边的MesId和stu.Id的相连接,发现总的列数是两个表的和,猪八戒出现两次,因为MesId的3出现了两次,
selectCount(*)关联后表的总行数
fromSignStates,stustu
关联表后所有age不同的个数用
selectCount(distinctage)age的不同个数
,三个43岁,一个12岁当然是2个,
selectCount(distinctage)age的不同个数,age
Select添加一个age表示同时显示列age,我们看到只是显示了一个值12岁,
统计的结果数目不应当和具体统计项目放在一起
如果where子句错误可能会产生笛卡尔链接
上述链接称为内连接,寻找两个表中字段值相同的行,
合成一张表,可以再where和form子句链接,
外部左链接:
是即使没有匹配左边的表的所有行也被输出,只不过右边的表的项目会产生null值,
fromSignState左边表
leftjoinstu右边表
onSignState.id=stu.id
SignState有四行,所以无论如何都会产生四行结果,
换成:
fromstu
leftjoinSignState
这里没有出错,左边表有6行,无论如何都用6行结果
右链接,right on 同样如此.
还有一个全连接表示,左右统统链接,full on
selectstu.sname+tea.tname
fromstu,tea
表示链接两个字符串,作为一个结果列
substring()获取子字符串,//1表示从第一个字符开始
Selectsubstring(Product.name,1,10)+”…”assortname
FromProduct
结果:
AliceMutt...
AniseedSy...
BostonCra...
Camembert...
Carnarvon...
Chai...
Chang...
rtrim()移除字符串的字头空白
ltrim()或者字尾的空白
使用innerjoin的方法,
FromtabA
InnerjointabB
ONtabA.name=tabB.id
用两个字段将两个表连接起来,符合where和having子句的那些两个表的字段(name和id)都相同的行会被返回.
连接三个表,,左边表是一个()
From(tabA
ONtabA.name=taB.id)
Innerjointab3
OntabA.name=tab3.id
四个表
From((tabA
OntabA.name=tab3.id)
Innerjointab4
OntabA.name=tab4.id
就是将on表.字段=表.字段加上括弧,一直到from前面
现在有四个表学生表,
课程表
课程号码,课程名字,老师的id
教师表
成绩表,id,学生号,课程号,分数
问题1.选出1,2号课程平均分高于70的学生的学号和姓名,
显然需要avg(score),还要关联两个表,这里必须使用groupby
用学号进行分组,
selectstuid,avg(score),stu.sname
fromscinnerjoinstuonstu.id=sc.stuid
wherecourseidin(1,2)
groupbystuid,stu.sname
havingavg(score)>
70
发现select用于选择显示的属性列,where用于赛选元组行,groupby会分开计算,,,,having对分组进行过滤,也就是最后的一个显示过滤
没有having将显示全部,
问题2
求所有学生学习的科目数,和总分情况
逆向思维,只不过在学生表中增加了两列,count(score)和count(sc.id),显然需要连接,Stu和SC表通过学生的id
selectstu.id,stu.sname,count(sc.id)as门数,sum(score)as总分
fromstuleftjoinsconstu.id=sc.stuid
groupbystu.id,stu.sname
左连接可以保证所有的人都有统计结果哪怕上官宇什么都没有选择,
having门数>
5,就可以将我们最后一个数据踢出
问题3
统计姓黄的老师或者教数学的老师的人数.:
只是一列
selectcount
(1)
fromtealeftjoincourseontea.id=course.teaid
whereTnamelike'
黄%'
orcourse.Cname='
数学'
问题4
查询没有上过”郭靖”老师课的学生的学号姓名(只是知道老师的名字不知道他带什么课程)
将老师和学生链接起来的是两张表,
成绩表中的SC.courseid关联到下面的
course.Id,,而下面的course.Teaid关联老师的主键
selectstu.id,stu.sname
fromstu
Whereidnotin(selectdistinct(sc.stuid)fromsc,course,teawheresc.courseid=course.idandcourse.teaid=tea.idandtea.tname='
郭靖'
)
用where子句就可以关联三个表,最终到达tea.Tname=’郭靖’
sc.courseid=course.idandcourse.teaid=tea.idandtea.tname='
因为SC表包含了我们想要的学生的主键id,只不过多次出现需要用distinct,,还可以在最后一个where子句中加入Sname!
=’刘涛’来限制最后表的结果,where子句是通过单元格的值来限制行的出现.
问题5
查询学过白老师教过的所有课程的学生的学号姓名,
:
从老师表中拿到白老师的id,在course表中查到teaid=白老师的所有主键,(一个课程号的集合)再回到SC表中的courseid,找到所有的stuid
Selectstu.id,stu.sname
Fromstu
Whereidin(A)
A=Selectdistinct(stuid)fromscwheresc.courseidin(selectcourse.idfromcourse,teawherecourse.teaid=tea.idandtea.tname='
白云霄'
注意标点符号从word中复制到db软件中会出现错误,记得看字体的颜色,
用两个嵌套的子查询,学生的id来自SC表,SC的课程号码courseid来自course表中teaid都指向白老师的哪些课程号.
问题6
查询1号课程成绩比2号成绩高的学生的学号,姓名
首先尝试着列出所有学生的一号和二号课程的成绩,
selectstu.id,stu.sname,(selectsc.scorefromscwheresc.stuid=stu.idandsc.courseid=1)asscore1,(selectsc.scorefromscwheresc.stuid=stu.idandsc.courseid=2)asscore2
两个select子句包含在第一个select语句中,就是添加了连个列
Selectstu.id.stu.sname,(select),(select)
其中这两个select子句必须返回一列值,分别代表各个学生的得分,这里还是循环迭代,取出每一个stu.id进入(select)子句中,匹配出一个符合条件的分数再返回.
再加上一句:
wherescore1>
score2
就搞定.如果要通过课程的名字来限定,那么就要根据Course表从cname确定id
andsc.courseidin(selectcourse.idfromcoursewhereame='
一个表中如果id和另一个属性列有同样的唯一性,那么他们是可以相互替代的,因为这是一个一对一的关系,通过”数学”二字检索出id
问题7
查出没学课程数目大于2个的学生的信息:
fromstu,sc
wherestu.id=sc.stuid
havingcount(sc.courseid)<
(selectcount(id)-2fromcourse)
用where链接两个表,以学号分组,统计数字,比较的数字也是一个统计数字,同时是一个表,一行一列的表,只有一个值
count(id)-2表示统计的结果可以参加运算,一个计数的条件来源于另一个计数的结果.
问题8
查询和3号学生所选课程完全一致的学生的学号和姓名:
selectstu.id,stu.sname,count(stu.id)
wherestu.id=sc.stuidandsc.courseidin(selectsc.courseidfromscwheresc.stuid=3)
havingcount(*)=(selectcount(*)fromscwheresc.stuid=3)
可以发现必须数字和内容都要对应,havingcount(*)表示统计每一组的总数,改成count
(1)也可以
问题9
查询各科成绩的最高和最低分.
selectss.courseidas课程id,ss.scoreas最高分
fromscasss
wheress.score=(selectmax(cc.score)fromscascc,stuwheress.courseid=cc.courseidandstu.id=cc.stuid
groupbycc.courseid)
orderby-最高分
ss.score=()这里是拿出依次对比,看看哪个分数和最分相同,
ss和cc是SC表的影子表,这里除了id可以唯一标示SC的元组,还有学生的stuid和课程courseid可以组合起来唯一的确定一个元组,当然要以课程分组,groupbycc.courseid
当执行ss.score=()时候,每次都会将表ss的一个元组带入到()中,
问题10什么是存储过程
存储过程(StoredProcedure)是在大型数据库系统中,一组为了完成特定功能的SQL语句集,经编译后存储在数据库中,用户通过指定存储过程的名字并给出参数(如果该存储过程带有参数)来执行它。
触发器的概念及作用
触发器是一种特殊类型的存储过程,它不同于我们前面介绍过的存储过程。
触发器主要是通过事件进行触发而被执行的,而存储过程可以通过存储过程名字而被直接调用。
当对某一表进行诸如Update、Insert、Delete这些操作时,SQLServer就会自动执行触发器所定义的SQL语句,从而确保对数据的处理必须符合由这些SQL语句所定义的规则。
触发器的主要作用就是其能够实现由主键和外键所不能保证的复杂的参照完整性和数据的一致性。
除此之外,触发器还有其它许多不同的功能:
(1)强化约束(Enforcerestriction)
触发器能够实现比CHECK语句更为复杂的约束。
(2)跟踪变化Auditingchanges
触发器可以侦测数据库内的操作,从而不允许数据库中未经许可的指定更新和变化。
(3)级联运行(Cascadedoperation)。
触发器可以侦测数据库内的操作,并自动地级联影响整个数据库的各项内容。
例如,某个表上的触发器中包含有对另外一个表的数据操作(如删除,更新,插入)而该操作又导致该表上触发器被触发。
(4)存储过程的调用(Storedprocedureinvocation)。
为了响应数据库更新,触发器可以调用一个或多个存储过程,甚至可以通过外部过程的调用而在DBMS(数据库管理系统)本身之外进行操作。
由此可见,触发器可以解决高级形式的业务规则或复杂行为限制以及实现定制记录等一些方面的问题。
例如,触发器能够找出某一表在数据修改前后状态发生的差异,并根据这种差异执行一定的处理。
此外一个表的同一类型(Insert、Update、Delete)的多个触发器能够对同一种数据操作采取多种不同的处理。
总体而言,触发器性能通常比较低。
当运行触发器时,系统处理的大部分时间花费在参照其它表的这一处理上,因为这些表既不在内存中也不在数据库设备上,而删除表和插入表总是位于内存中。
可见触发器所参照的其它表的位置决定了操作要花费的时间长短。
问题11使用trycatch捕获处理异常
假设出现主键重复异常,
begintry
insertintoStu(Id,SName)values(12,'
涛哥'
endtry
begincatch
PRINT'
出现异常'
SELECT
ERROR_NUMBER()ASErrorNumber,--错误代码
ERROR_SEVERITY()ASErrorSeverity,--错误级别
ERROR_STATE()ASErrorState,
ERROR_PROCEDURE()ASErrorProcedure,--错误
ERROR_LINE()ASErrorLine,--出错行号
ERROR_MESSAGE()ASErrorMessage;
--错误信息
endcatch
注意严重性为10或更低的错误被视为警告或信息性消息,TRY...CATCH块不处理此类错误。
如果一次要插入多条语句就需要如下所写
1.Value()后面加多个()
2.直接用select的结果插入到表中
insertintoStu(Id,SName)values(9,'
we'
),(10,'
er'
insertintoStu(Id,SName)
SelectTea.Id,Tea.TNamefromTea
whereId>
10
问题12Update更新数据
一次更新多个值updateTeasetTName='
就是他'
whereIdin(10,14,9)
就是在where做限定。
问题13删除字段,数据库定义语言,修改了表结构。
ALTERtableTeaDROPcolumnTNum
增加字段
altertabledocdsp
addTnumchar(200)
问题14用like搜索关键词百分号就需要转义
Mysql中
select*fromhome_feedwhereOriginalContentlike'
%\%%'
orderby-DateCreated
Sqlserver中
select*fromStuwhereSNamelike'
%[%]%'
其他关键字符如_?
等等同样处理。
问题15使用stuff函数合并字段
Stuff函数
问题16


- 配套讲稿:
如PPT文件的首页显示word图标,表示该PPT已包含配套word讲稿。双击word图标可打开word文档。
- 特殊限制:
部分文档作品中含有的国旗、国徽等图片,仅作为作品整体效果示例展示,禁止商用。设计者仅对作品中独创性部分享有著作权。
- 关 键 词:
- 数据库 查询 语言
 冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 如何打造酒店企业文化2刘田江doc.docx
如何打造酒店企业文化2刘田江doc.docx
-
律师提供著作权法律服务业务操作指引.docx
-
18秋福建师范大学《经济法》在线作业一.docx
-
施工现场危险源.docx
-
山东省潍坊市昌乐县学年七年级地理下学期期中学业质量评估试题.docx
-
新视野大学英语视听说教程第二版第一册完整答案.docx
-
精校版重庆市 初中毕业水平暨高中招生考试中考英语试题AB卷Word版含答案解析.docx
-
新视野大学英语视听说教程第二版第一册完整答案.docx
-
江苏省刘国钧中学1112学年高二语文上学期期末考前辅导试题卷苏教版会员独享.docx
-
山东省潍坊市昌乐县学年七年级地理下学期期中学业质量评估试题.docx
-
西安交通大学18年课程考试《管理会计》作业考核试题.docx
-
施工安全保证体系.docx
-
南开17秋学期《科学启蒙尔雅》在线作业2.docx
-
秋福师《大学英语1》在线作业二.docx
-
231695 北交《运输物流管理》在线作业2 15秋答案.docx
-
梁原学区安全管理工作实施方案.docx
-
环保管理台帐明细.docx
-
我国三大翻译证书考试概览.docx
-
东大17秋学期《大学英语二》在线作业31.docx
-
静态分析指标.docx
-
山东金瀚控股金瀚置业绩效考核指标库.docx
-
B0301A国际贸易.docx
-
人教版八年级数学上册同步练习试题及答案第11章《三角形》 同步练习及答案111.docx
-
秋福师《概率论》在线作业二.docx
-
17秋福师《高级英语阅读二》在线作业一.docx
-
西南大学17秋0764《工程建设监理》在线作业参考资料.docx
-
生活宝典之社会大转盘一.docx
-
专卖店管理.docx
-
100个CFO的八年之资金管理篇.docx
-
东北师范古代汉语三16秋在线作业2.docx
-
专业技术人员公共危机管理考试.docx
-
东大17秋学期《大学英语二》在线作业31.docx
-
pep英语三年级下册教案.docx
-
黑龙江省黑河市腾飞国际养生园项目可行性研究报告.docx
-
人教版七年级生物下册全册教案.docx
-
焊材选用指南.docx
-
202X送朋友新年元旦祝福语大全doc.docx
-
种植合作社蔬菜种植基地建设工程可行性研究报告.docx
-
仅有成本创新是不够的.docx
-
基于CPLD的移动通信调制编码技术的研究毕业设计报告.docx
-
北京版小学英语五年级上册教案单元21.docx
-
XX地区旧城改造发展工程规划项目可行性研究报告.docx
-
实用大棚水果蔬菜育苗基地建设项目研究可行性报告方案.docx
-
人教版小学三年级数学上册万以内的加法和减法口算题27.docx
-
湖南文艺出版社小学三年级音乐教案2.docx
-
S版语文二年级上册语文教案.docx
-
最新合同协议教师聘用合同二范本.docx
-
酒店集团餐饮管理手册餐饮部规范管理.docx
-
部编版六年级语文下册同步练习9那个星期天有答案.docx
-
市政工程施工组织设计投标书.docx
-
八年级历史上册 第六单元第20课社会生活的变化教案 人教新课标版.docx
