 最新目标检测RCNN到SSD学习总结Word下载.docx
最新目标检测RCNN到SSD学习总结Word下载.docx
- 文档编号:19958893
- 上传时间:2023-01-12
- 格式:DOCX
- 页数:13
- 大小:480.24KB
最新目标检测RCNN到SSD学习总结Word下载.docx
《最新目标检测RCNN到SSD学习总结Word下载.docx》由会员分享,可在线阅读,更多相关《最新目标检测RCNN到SSD学习总结Word下载.docx(13页珍藏版)》请在冰豆网上搜索。
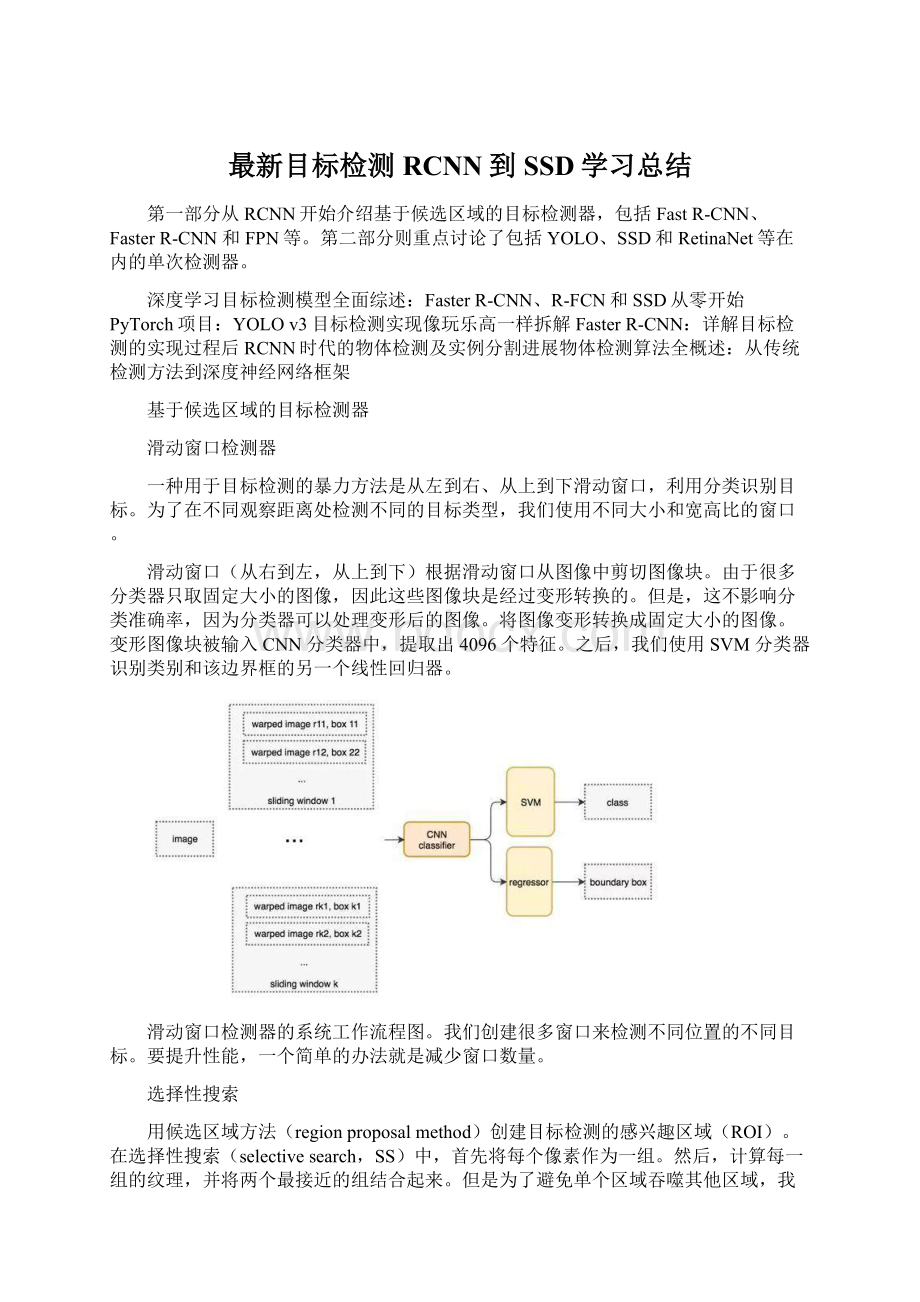
但是为了避免单个区域吞噬其他区域,我们首先对较小的组进行分组。
我们继续合并区域,直到所有区域都结合在一起。
下图第一行展示了如何使区域增长,第二行中的蓝色矩形代表合并过程中所有可能的ROI。
(作者为了保证能够划分的完全,对于相似度,作者提出了可以多样化的思路,不但使用多样的颜色空间(RGB,Lab,HSV等等),还有很多不同的相似度计算方法。
论文考虑了颜色、纹理、尺寸和空间交叠这4个参数)
R-CNN
R-CNN利用候选区域方法创建了约2000个ROI。
这些区域被转换为固定大小的图像,并分别馈送到卷积神经网络中。
该网络架构后面会跟几个全连接层,以实现目标分类并提炼边界框。
使用候选区域、CNN、仿射层来定位目标。
以下是R-CNN整个系统的流程图:
通过使用更少且更高质量的ROI,R-CNN要比滑动窗口方法更快速、更准确。
边界框回归器
候选区域方法有非常高的计算复杂度。
为了加速这个过程,通常会使用计算量较少的候选区域选择方法构建ROI,并在后面使用线性回归器(使用全连接层)进一步提炼边界框。
使用回归方法将蓝色的原始边界框提炼为红色的。
FastR-CNN
R-CNN需要非常多的候选区域以提升准确度,但其实有很多区域是彼此重叠的,因此R-CNN的训练和推断速度非常慢。
如果我们有2000个候选区域,且每一个都需要独立地馈送到CNN中,那么对于不同的ROI,我们需要重复提取2000次特征。
此外,CNN中的特征图以一种密集的方式表征空间特征,那么我们能直接使用特征图代替原图来检测目标吗?
直接利用特征图计算ROI。
FastR-CNN使用特征提取器(CNN)先提取整个图像的特征,而不是从头开始对每个图像块提取多次。
然后,我们可以将创建候选区域的方法直接应用到提取到的特征图上。
例如,FastR-CNN选择了VGG16中的卷积层conv5来生成ROI,这些关注区域随后会结合对应的特征图以裁剪为特征图块,并用于目标检测任务中。
我们使用ROI池化将特征图块转换为固定的大小,并馈送到全连接层进行分类和定位。
因为Fast-RCNN不会重复提取特征,因此它能显著地减少处理时间。
将候选区域直接应用于特征图,并使用ROI池化将其转化为固定大小的特征图块。
以下是FastR-CNN的流程图:
在下面的伪代码中,计算量巨大的特征提取过程从For循环中移出来了,因此速度得到显著提升。
FastR-CNN的训练速度是R-CNN的10倍,推断速度是后者的150倍。
FastR-CNN最重要的一点就是包含特征提取器、分类器和边界框回归器在内的整个网络能通过多任务损失函数进行端到端的训练,这种多任务损失即结合了分类损失和定位损失的方法,大大提升了模型准确度。
ROI池化
因为FastR-CNN使用全连接层,所以我们应用ROI池化将不同大小的ROI转换为固定大小。
为简洁起见,我们先将8×
8特征图转换为预定义的2×
2大小。
下图左上角:
特征图。
右上角:
将ROI(蓝色区域)与特征图重叠。
左下角:
将ROI拆分为目标维度。
例如,对于2×
2目标,我们将ROI分割为4个大小相似或相等的部分。
右下角:
找到每个部分的最大值,得到变换后的特征图。
输入特征图(左上),输出特征图(右下),ROI(右上,蓝色框)。
按上述步骤得到一个2×
2的特征图块,可以馈送至分类器和边界框回归器中。
FasterR-CNN
FastR-CNN依赖于外部候选区域方法,如选择性搜索。
但这些算法在CPU上运行且速度很慢。
在测试中,FastR-CNN需要2.3秒来进行预测,其中2秒用于生成2000个ROI。
FasterR-CNN采用与FastR-CNN相同的设计,只是它用内部深层网络代替了候选区域方法。
新的候选区域网络(RPN)在生成ROI时效率更高,并且以每幅图像10毫秒的速度运行。
FasterR-CNN的流程图与FastR-CNN相同
外部候选区域方法代替了内部深层网络
候选区域网络
候选区域网络(RPN)将第一个卷积网络的输出特征图作为输入。
它在特征图上滑动一个3×
3的卷积核,以使用卷积网络(如下所示的ZF网络)构建与类别无关的候选区域。
其他深度网络(如VGG或ResNet)可用于更全面的特征提取,但这需要以速度为代价。
ZF网络最后会输出256个值,它们将馈送到两个独立的全连接层,以预测边界框和两个objectness分数,这两个objectness分数度量了边界框是否包含目标。
我们其实可以使用回归器计算单个objectness分数,但为简洁起见,FasterR-CNN使用只有两个类别的分类器:
即带有目标的类别和不带有目标的类别。
对于特征图中的每一个位置,RPN会做k次预测。
因此,RPN将输出4×
k个坐标和每个位置上2×
k个得分。
下图展示了8×
8的特征图,且有一个3×
3的卷积核执行运算,它最后输出8×
8×
3个ROI(其中k=3)。
下图(右)展示了单个位置的3个候选区域。
此处有3种猜想,稍后我们将予以完善。
由于只需要一个正确猜想,因此我们最初的猜想最好涵盖不同的形状和大小。
因此,FasterR-CNN不会创建随机边界框。
相反,它会预测一些与左上角名为「锚点」的参考框相关的偏移量(如x、y)。
我们限制这些偏移量的值,因此我们的猜想仍然类似于锚点。
要对每个位置进行k个预测,我们需要以每个位置为中心的k个锚点。
每个预测与特定锚点相关联,但不同位置共享相同形状的锚点。
这些锚点是精心挑选的,因此它们是多样的,且覆盖具有不同比例和宽高比的现实目标。
这使得我们可以以更好的猜想来指导初始训练,并允许每个预测专门用于特定的形状。
该策略使早期训练更加稳定和简便。
FasterR-CNN使用更多的锚点。
它部署9个锚点框:
3个不同宽高比的3个不同大小的锚点框。
每一个位置使用9个锚点,每个位置会生成2×
9个objectness分数和4×
9个坐标。
R-CNN方法的性能
如下图所示,FasterR-CNN的速度要快得多。
基于区域的全卷积神经网络(R-FCN)
假设我们只有一个特征图用来检测右眼。
那么我们可以使用它定位人脸吗?
应该可以。
因为右眼应该在人脸图像的左上角,所以我们可以利用这一点定位整个人脸。
如果我们还有其他用来检测左眼、鼻子或嘴巴的特征图,那么我们可以将检测结果结合起来,更好地定位人脸。
现在我们回顾一下所有问题。
在FasterR-CNN中,检测器使用了多个全连接层进行预测。
如果有2000个ROI,那么成本非常高。
R-FCN通过减少每个ROI所需的工作量实现加速。
上面基于区域的特征图与ROI是独立的,可以在每个ROI之外单独计算。
剩下的工作就比较简单了,因此R-FCN的速度比FasterR-CNN快。
现在我们来看一下5×
5的特征图M,内部包含一个蓝色方块。
我们将方块平均分成3×
3个区域。
现在,我们在M中创建了一个新的特征图,来检测方块的左上角(TL)。
这个新的特征图如下图(右)所示。
只有黄色的网格单元[2,2]处于激活状态。
在左侧创建一个新的特征图,用于检测目标的左上角
我们将方块分成9个部分,由此创建了9个特征图,每个用来检测对应的目标区域。
这些特征图叫作位置敏感得分图(position-sensitivescoremap),因为每个图检测目标的子区域(计算其得分)。
生成9个得分图
下图中红色虚线矩形是建议的ROI。
我们将其分割成3×
3个区域,并询问每个区域包含目标对应部分的概率是多少。
例如,左上角ROI区域包含左眼的概率。
我们将结果存储成3×
3vote数组,如下图(右)所示。
例如,vote_array[0][0]包含左上角区域是否包含目标对应部分的得分。
将ROI应用到特征图上,输出一个3x3数组。
将得分图和ROI映射到vote数组的过程叫作位置敏感ROI池化(position-sensitiveROI-pool)。
该过程与前面讨论过的ROI池化非常接近。
将ROI的一部分叠加到对应的得分图上,计算V[i][j]。
在计算出位置敏感ROI池化的所有值后,类别得分是其所有元素得分的平均值。
假如我们有C个类别要检测。
我们将其扩展为C+1个类别,这样就为背景(非目标)增加了一个新的类别。
每个类别有3×
3个得分图,因此一共有(C+1)×
3×
3个得分图。
使用每个类别的得分图可以预测出该类别的类别得分。
然后我们对这些得分应用softmax函数,计算出每个类别的概率。
以下是数据流图,在我们的案例中,k=3。
单次目标检测器
单次目标检测器(包括SSD、YOLO、YOLOv2、YOLOv3)
我们将分析FPN以理解多尺度特征图如何提高准确率,特别是小目标的检测,其在单次检测器中的检测效果通常很差。
然后我们将分析Focalloss和RetinaNet,看看它们是如何解决训练过程中的类别不平衡问题的。
单次检测器
FasterR-CNN中,在分类器之后有一个专用的候选区域网络。
FasterR-CNN工作流
基于区域的检测器是很准确的,但需要付出代价。
FasterR-CNN在PASCALVOC2007测试集上每秒处理7帧的图像(7FPS)。
和R-FCN类似,研究者通过减少每个ROI的工作量来精简流程。
作为替代,我们是否需要一个分离的候选区域步骤?
我们可以直接在一个步骤内得到边界框和类别吗?
YOLO
YOLO将全图划分为SXS的格子,每个格子负责中心在该格子的目标检测,采用一次性预测所有格子所含目标的bbox、定位置信度以及所有类别概率向量来将问题一次性解决(one-shot)。
YOLO的核心思想就是利用整张图作为网络的输入,直接在输出层回归boundingbox(边界框)的位置及其所属的类别。
将一幅图像分成SxS个网格(gridcell),如果某个object的中心落在这个网格中,则这个网格就负责预测这个object。
让我们再看一下滑动窗口检测器。
我们可以通过在特征图上滑动窗口来检测目标。
对于不同的目标类型,我们使用不同的窗口类型。
以前的滑动窗口方法的致命错误在于使用窗口作为最终的边界框,这就需要非常多的形状来覆盖大部分目标。
更有效的方法是将窗口当做初始猜想,这样我们就得到了从当前滑动窗口同时预测类别和边界框的检测器。
1、现代文化对大学生饰品消费的影响基于滑动窗口进行预测
这个概念和FasterR-CNN中的锚点很相似。
然而,单次检测器会同时预测边界框和类别。
例如,我们有一个8×
8特征图,并在每个位置做出k个预测,即总共有8×
8×
k个预测结果。
在每个位置,我们有k个锚点(锚点是固定的初始边界框猜想),一个锚点对应一个特定位置。
我们使用相同的锚点形状仔细地选择锚点和每个位置。
功能性手工艺品。
不同的玉石具有不同的功效,比如石榴石可以促进血液循环,改善风湿和关节炎;
白水晶则可以增强记忆力;
茶晶能够帮助镇定情绪,缓解失眠、头昏等症状。
顾客可以根据自己的需要和喜好自行搭配,每一件都独一无二、与众不同。
使用4个锚点在每个位置做出4个预测。
以下是4个锚点(绿色)和4个对应预测(蓝色),每个预测对应一个特定锚点。
“碧芝自制饰品店”拥有丰富的不可替代的异国风采和吸引人的魅力,理由是如此的简单:
世界是每一个国家和民族都有自己的饰品文化,将其汇集进行再组合可以无穷繁衍。
4个预测,每个预测对应一个锚点。
据统计,上海国民经济持续快速增长。
03全年就实现国内生产总值(GDP)6250.81亿元,按可比价格计算,比上年增长11.8%。
第三产业的增速受非典影响而有所减缓,全年实现增加值3027.11亿元,增长8%,增幅比上年下降2个百分点。
在FasterR-CNN中,我们使用卷积核来做5个参数的预测:
4个参数对应某个锚点的预测边框,1个参数对应objectness置信度得分。
因此3×
3×
D×
5卷积核将特征图从8×
D转换为8×
5。
使用3x3卷积核计算预测。
在单次检测器中,卷积核还预测C个类别概率以执行分类(每个概率对应一个类别)。
因此我们应用一个3×
25卷积核将特征图从8×
25(C=20)。
每个位置做出k个预测,每个预测有25个参数。
单次检测器通常需要在准确率和实时处理速度之间进行权衡。
它们在检测太近距离或太小的目标时容易出现问题。
在下图中,左下角有9个圣诞老人,但某个单次检测器只检测出了5个。
(2)东西全SSD
SSD是使用VGG19网络作为特征提取器(和FasterR-CNN中使用的CNN一样)的单次检测器。
我们在该网络之后添加自定义卷积层(蓝色),并使用卷积核(绿色)执行预测。
小饰品店往往会给人零乱的感觉,采用开架陈列就会免掉这个麻烦。
“漂亮女生”像是个小超市,同一款商品色彩丰富地挂了几十个任你挑,拿上东西再到收银台付款。
这也符合女孩子精挑细选的天性,更保持了店堂长盛不衰的人气。
YOLO在卷积层后接全连接层,即检测时只利用了最高层featuremaps(包括FasterRCNN也是如此);
据调查,大学生对此类消费的态度是:
手工艺制品消费比“负债”消费更得人心。
而SSD采用了特征金字塔结构进行检测,在多个featuremaps上同时进行softmax分类和位置回归。
但这些困难并非能够否定我们创业项目的可行性。
盖茨是由一个普通退学学生变成了世界首富,李嘉诚是由一个穷人变成了华人富豪第一人,他们的成功表述一个简单的道理:
如果你有能力,你可以从身无分文变成超级富豪;
如果你无能,你也可以从超级富豪变成穷光蛋。
SSD使用低层featuremap检测小目标,使用高层featuremap检测大目标
SSD中引入了PriorBox:
预选框+通过softmax分类+boundingboxregression获得真实目标的位置。
我们大学生没有固定的经济来源,但我们也不乏缺少潮流时尚的理念,没有哪个女生是不喜欢琳琅满目的小饰品,珠光宝气、穿金戴银便是时尚的时代早已被推出轨道,简洁、个性化的饰品成为现代时尚女性的钟爱。
因此饰品这一行总是吸引很多投资者的目光。
然而我们女生更注重的是感性消费,我们的消费欲望往往建立在潮流、时尚和产品的新颖性上,所以要想在饰品行业有立足之地,又尚未具备雄厚的资金条件的话,就有必要与传统首饰区别开来,自制饰品就是近一两年来沿海城市最新流行的一种。
同时对类别和位置执行单次预测。
然而,卷积层降低了空间维度和分辨率。
因此上述模型仅可以检测较大的目标。
为了解决该问题,从多个特征图上执行独立的目标检测。
4.WWW。
google。
com。
cn。
大学生政策2004年3月23日
使用多尺度特征图用于检测。


- 配套讲稿:
如PPT文件的首页显示word图标,表示该PPT已包含配套word讲稿。双击word图标可打开word文档。
- 特殊限制:
部分文档作品中含有的国旗、国徽等图片,仅作为作品整体效果示例展示,禁止商用。设计者仅对作品中独创性部分享有著作权。
- 关 键 词:
- 最新 目标 检测 RCNN SSD 学习 总结
 冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 对中国城市家庭的教育投资行为的理论和实证研究.docx
对中国城市家庭的教育投资行为的理论和实证研究.docx
-
二年级下册数学练习题大全.docx
-
二十年后回故乡的优秀作文.docx
-
软基换填施工方案.docx
-
《黑白装饰画》教案.docx
-
课堂教学改革实施方案5篇.docx
-
返璞归真简约致美解读《给予树》教学设计语文.docx
-
离职证明范本精选多篇.docx
-
《天局》全文.docx
-
我害怕作文集合15篇.docx
-
伏魔战记39详细攻略.docx
-
幼儿园学期计划.docx
-
雅思分类打印版Word格式文档下载.docx
-
年产1万吨竹子纤维加工项目可行性研究报告文档格式.docx
-
电商产业化项目投资经营商业计划书Word文件下载.docx
-
医学多媒体课件的设计与制作Word文档格式.docx
-
中学生中秋节想象作文Word格式.docx
-
等保20之漏洞扫描系统技术方案建议书Word文档格式.docx
-
培训学校个人工作计划模板5篇Word格式.docx
-
北京各区二模试题分类汇编文言文阅读Word文档下载推荐.docx
-
不同职业病危害因素的防护常识Word格式文档下载.docx
-
一年级上册同音形近字练习汇总Word文档格式.docx
-
班级家长会上班主任教师讲话稿Word下载.docx
-
科斯塔环载波恢复Word文件下载.docx
-
浙教义务版六年级语文下册教案 花潮Word文件下载.docx
-
集成电路设计与集成系统专业Word格式文档下载.docx
-
开工第一课专题讲座观后感文档格式.docx
-
东城区学年第一学期高三期末化学试题及答案Word格式文档下载.docx
-
苏教版六年级语文下册第七单元测试题Word格式文档下载.docx
-
学长征精神做红色传人活动方案文档格式.docx
-
读书笔记150字30篇文档格式.docx
-
中级经济法考前必背法条精华版备考资料Word格式.docx
-
小学辅导班教案模板.docx
-
幼儿钢琴教学培训心得体会.docx
-
周年活动策划集锦10篇.docx
-
学校少年宫戏剧小组活动记录终审稿.docx
-
我国汽车产业发展的几大瓶颈.docx
-
元旦晚会策划方案3000字.docx
-
医药培训心得体会多篇.docx
-
无领导小组讨论实战总结.docx
-
施工现场规定.docx
-
物业工作总结怎么写.docx
-
校园运动会心得体会范文精选25篇.docx
-
幼儿园教育教学工作制度.docx
-
正放四角锥网架施工专项方案.docx
-
一级协理岗位职责.docx
-
系统函数的零极点分布决定时域特性.docx
-
武汉市酒店服务技能大赛理论题餐饮部分试题及答案.docx
-
优美句子摘抄.docx
-
中小企业信用体系建设简报.docx
-
英文字母书写标准及练习本a打印.docx
