 应用多元统计分析作业Word格式.docx
应用多元统计分析作业Word格式.docx
- 文档编号:19110918
- 上传时间:2023-01-03
- 格式:DOCX
- 页数:17
- 大小:135.70KB
应用多元统计分析作业Word格式.docx
《应用多元统计分析作业Word格式.docx》由会员分享,可在线阅读,更多相关《应用多元统计分析作业Word格式.docx(17页珍藏版)》请在冰豆网上搜索。
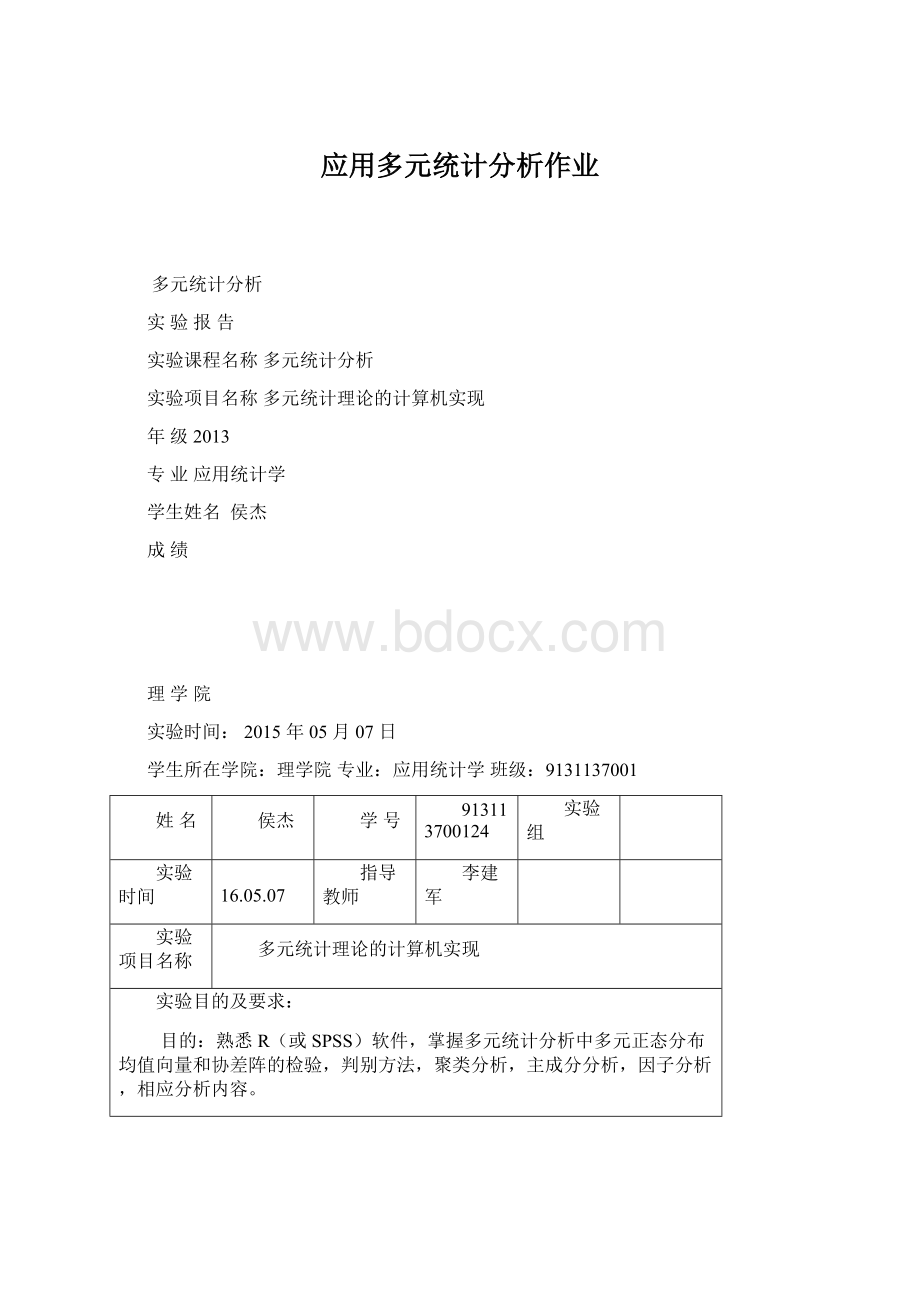
xdat<
-data[,2:
4];
xbar<
-apply(xdat,2,mean);
#计算LF指标的均值
ydat<
-data[,5:
7];
ybar<
-apply(ydat,2,mean);
#计算HF指标数据
xcov<
-cov(xdat);
#计算LF样本协差阵
ycov<
-cov(ydat);
#计算HF样本协差阵
sinv<
-solve(xcov+ycov);
#求逆矩阵Tsq<
-(16+16-2)*t(sqrt(16*16/(16+16)*(xbar-ybar)))%*%sinv%*%sqrt(16*16/(16+16)*(xbar-ybar));
#计算T统计量
Fstat<
-((16+16-2)-3+1)/((16+16-2)*3)*Tsq;
#计算F统计量
pvalue<
-as.numeric(1-pf(Fstat,3,16+16-3-1));
cat("
p值="
pvalue,"
\n"
);
if(pvalue>
0.05)#结果输出
cat('
均值向量不存在差异'
)
else
均值向量存在差异'
}
运行结果及分析:
通过运行程序,我们可以得到如下结果:
>
Tsq.test()
p值=1.632028e-14
均值向量存在差异
即LF与HF这两个指标的各次重复测定均值向量存在显著差异。
2、判别分析
银行的贷款部门需要判别每个客户的信用好坏(是否未履行还贷责任),以决定是否给予贷款。
可以根据贷款申请人的年龄()、受教育程度()、现在所从事工作的年数()、未变更住址的年数()、收入()、负债收入比例()、信用卡债务()、其它债务()等来判断其信用情况。
数据见压缩包。
⑴根据样本资料分别用距离判别法、Bayes判别法和Fisher判别法建立判别函数和判别规则。
⑵某客户的如上情况资料为(53,1,9,18,50,11.20,2.02,3.58),对其进行信用好坏的判别。
#距离判别法
discrim.dist<
-function(x){
-read.csv("
ch49.csv"
header=T,sep="
#读取数据
G1<
-data[1:
5,];
G2<
-data[6:
10,];
u1<
-apply(G1,2,mean);
#计算信用好的样本数据均值
u2<
-apply(G2,2,mean);
#计算信用不好的样本数据均值
s1<
-cov(G1);
s2<
-cov(G2);
s<
-s1+s2;
-(u1+u2)/2;
alpha<
-solve(s)%*%(u1-u2);
#计算判别系数alpha
w<
-t(alpha)%*%(x-xbar);
#构造判别函数
if(w>
=0)#结果输出
该客户属于信用好的一类"
该客户属于信用坏的一类"
#费希尔判别法
fisher.test<
n1<
-nrow(G1);
n2<
-nrow(G2);
#计算信用好的一组的数据均值
#计算信用不好的一组的样本数据均值
E<
B<
-n1*n2*(u1-u2)%*%t(u1-u2)/(n1+n1);
-eigen(solve(E)%*%B);
vector<
-alpha$vectors[,1];
#提取费希尔判别函数系数
d1<
-abs(t(vector)%*%x-t(vector)%*%u1);
#计算样本到第一组的费希尔判别函数值
d2<
-abs(t(vector)%*%x-t(vector)%*%u2);
#计算样本到第二组的费希尔判别函数值
if(d1<
d2)#结果输出
注:
由于在本题的情形下,距离判别与贝叶斯判别等价,故在此处仅选取距离判别进行编程。
距离判别的运行结果:
>
x<
-c(53,1,9,18,50,11.20,2.02,3.58)
discrim.dist(x)
该客户属于信用好的一类
费希尔判别的运行结果:
fisher.test(x)
该客户属于信用好的一类
从上面的运行结果可以看出该客户属于信用好的一类,即已履行还贷责任。
3、聚类分析
下表(数据见压缩包)是某年我国16个地区农民支出情况的抽样调查数据,每个地区调查了反映每人平均生活消费支出情况的六个经济指标。
试使用系统聚类法和K均值法对这些地区进行聚类分析,并对结果进行分析比较。
#系统聚类法
data<
ch58.csv"
Cludata<
Dismatrix<
-dist(Cludata,method="
euclidean"
#计算样本间的欧几里得距离
Clu1<
-hclust(d=Dismatrix,method="
single"
#最短距离法
Clu2<
complete"
#最长距离法
Clu3<
centroid"
#重心法
Clu4<
ward.D"
#离差平方和法
###绘出四种方法情况下的谱系图和聚类情况
opar<
-par(mfrow=c(2,2));
plot(Clu1,labels=data[,1]);
re1<
-rect.hclust(Clu1,k=5,border="
red"
box();
plot(Clu2,labels=data[,1]);
re2<
-rect.hclust(Clu2,k=5,border="
plot(Clu3,labels=data[,1]);
re3<
-rect.hclust(Clu3,k=5,border="
plot(Clu4,labels=data[,1]);
re4<
-rect.hclust(Clu4,k=5,border="
par(opar);
###绘出直观的分类情形
-par(mfrow=c(2,2),las=2);
cut1<
-cutree(Clu1,k=5);
plot(cut1,pch=cut1,ylab="
类别编号"
xlab="
省市"
main="
聚类的成员"
axes=FALSE);
axis(1,at=1:
16,labels=data[,1],cex.axis=0.6);
axis(2,at=1:
5,labels=1:
5,cex.axis=0.6);
cut2<
-cutree(Clu2,k=5);
plot(cut2,pch=cut2,ylab="
cut3<
-cutree(Clu3,k=5);
plot(cut3,pch=cut3,ylab="
cut4<
-cutree(Clu4,k=5);
plot(cut4,pch=cut4,ylab="
#K均值聚类法
Cluk<
-kmeans(x=Cludata,centers=5,nstart=5);
#用K均值聚类分成五类
par(mfrow=c(2,1),las=2);
cluster<
-Cluk$cluster;
#保存聚类解
plot(cluster,pch=cluster,ylab="
#绘制各省市聚类解得序列图
legend("
topright"
c("
第一类"
第二类"
第三类"
第四类"
第五类"
),pch=1:
5,cex=0.3);
###绘制类中心变量取值折线图
plot(Cluk$centers[1,],ylim=c(0,82),xlab="
聚类变量"
ylab="
组均值(类中心)"
各类聚类变量均值的变化折线图"
6,labels=c("
食品"
衣着"
燃料"
住房"
交通和通讯"
娱乐教育文化"
),cex.axis=0.6);
lines(1:
6,Cluk$centers[1,],lty=2,col=2);
6,Cluk$centers[2,],lty=2,col=2);
6,Cluk$centers[3,],lty=3,col=3);
6,Cluk$centers[4,],lty=4,col=4);
6,Cluk$centers[5,],lty=5,col=5);
topleft"
),lty=1:
5,col=1:
5,cex=0.2)
系统聚类法
首先输入数据,计算样本间的欧几里得距离,然后用最短距离法,最长距离法,重心法,离差平方和法进行聚类分析,绘出谱系图和直观分类图。
分类结果如下:
从结果可以看出
最短距离法分类的情况如下:
第一类:
上海
第二类:
北京
第三类:
浙江
第四类:
山东
第五类:
其余地区
最长距离法分类的情况如下:
北京,浙江
吉林,安徽,福建,江西
辽宁,天津,江苏
山西,河北,河南,山东,内蒙,黑龙江
重心法分类的情况如下:
山西,河北,河南
离差平方和法分类的情况:
K均值聚类法的结果如下,将结果分成三类
分类情况如下:
北京,上海
天津,辽宁,吉林,江苏,浙江,安徽,福建,江西
河北,山西,内蒙,黑龙江,山东,河南
并且从第二张图可以看出三类地区的主要差别存在于食品和住房还有交通和通讯的方面,在其他方面则相差无几。
4、主成分分析
城市用水普及率X1,城市燃气普及率X2,每万人拥有公共交通车辆X3,人均城市道路面积X4,人均公园绿地面积X5,每万人拥有公共厕所X6等六个指标是衡量城市设施水平的主要指标,数据见压缩包,试用主成分分析法对各地区城市设施水平进行综合评价和排序。
ch68.csv"
cormatrix<
-cor(data[,2:
7]);
Result<
-eigen(cormatrix);
#求相关系数矩阵的特征值和特征向量
plot(Result$values,type="
b"
特征值(主成分方差)"
特征值编号(主成分编号)"
#绘制各主成分的方差变化折线图
datamatrix<
-as.matrix(data[,2:
princomp<
-datamatrix%*%Result$vectors;
#计算主成分
sum<
-sum(Result$values);
values<
-as.vector(Result$values);
contri<
-values/sum;
#方差贡献率
plot(contri,type="
方差贡献率"
主成分编号"
score<
-princomp%*%contri;
#计算综合得分
place<
-data[,1];
consequence<
-data.frame(score,place);
rank<
-c(1:
31);
final<
-consequence[order(-consequence$score),];
#对结果进行排序
total<
-cbind(final,rank);
total
total
scoreplacerank
1548.17886山东1
347.02848天津2
1046.98910江苏3
1145.69279浙江4
1345.67545福建5
245.49443河北6
1945.42103广东7
1444.84118江西8
944.47630上海9
144.19970北京10
3143.89986新疆11
3043.89648宁夏12
643.85077辽宁13
2243.84919重庆14
1243.81336安徽15
2043.65408广西16
1743.41939湖北17
442.94670山西18
2742.73741陕西19
1841.22774湖南20
2940.63502青海21
2140.16107海南22
2340.02236四川23
739.94659吉林24
539.33251内蒙古25
839.01378黑龙江26
2538.63829云南27
2837.48472甘肃28
1636.96833河南29
2636.29778西藏30
2435.74812贵州31
上面的结果中,rank列为排名,从上到下按得分从大到小排序。
此结果可能会有些许疑问,那就是北京上海等强势地区为何排名却少许靠后。
从数据方面来看,我们可以看到例如X3每万人拥有公共交通车辆,X4人均城市道路面积,X5人均公园绿地面积,X6每万人拥有公共厕所的数量等这些涉及到人均或者人口数量的指标对于人口十分密集的地区来说得分应该不会太高,因为北京上海这种人口十分密集的地区虽然强势,但是排名却不是十分靠前。
5、因子分析
利用因子分析方法分析下列30个学生成绩的因子构成,并分析各个学生较适合学文科还是理科。
library(psych);
ch77.csv"
correlations<
-cor(data);
#计算相关系数矩阵
fa<
-fa(correlations,nfactors=2,rotate="
varimax"
fm="
pa"
scores="
regression"
#设定因子数为2,采用正交旋转进行因子分析
###画出因子图形
factor.plot(fa,labels=rownames(fa$loadings));
fa.diagram(fa,simple=FALSE);
-as.matrix(data);
faFs<
-data%*%fa$weight;
#计算因子得分
outcome<
-c();
for(iin1:
30){
ifelse((faFs[i,1]>
faFs[i,2]),outcome<
-c(outcome,"
文科"
),outcome<
理科"
))
};
-as.vector(outcome);
#根据得分决定文理科
result<
-cbind(data,outcome);
从图上我们看出数学物理化学在第二个因子上载荷较大,语文英语历史在第一个因子载荷上较大,因此我们也就可以将第一个因子和第二个因子理解成日常中的文科和理科
接下来根据每个学生的因子得分比较来分析该学生适合文科还是理科,结果如下:
result
数学物理化学语文历史英语outcome
[1,]"
65"
"
61"
72"
84"
81"
79"
[2,]"
77"
76"
64"
70"
55"
[3,]"
67"
63"
49"
57"
[4,]"
80"
69"
75"
74"
[5,]"
[6,]"
78"
62"
71"
[7,]"
66"
52"
[8,]"
86"
[9,]"
83"
100"
41"
50"
[10,]"
94"
97"
51"
[11,]"
88"
73"
[12,]"
53"
58"
56"
[13,]"
[14,]"
[15,]"
96"
89"
[16,]"
[17,]"
90"
68"
60"
[18,]"
[19,]"
85"
[20,]"
[21,]"
91"
[22,]"
87"
[23,]"
82"
[24,]"
[25,]"
95"
59"
[26,]"
[27,]"
98"
47"
[28,]"
[29,]"
54"
[30,]"
6相应分析
问题重述:
费希尔研究头发颜色与眼睛颜色的关系,抽查了5387人的资料如下表,试对其进行相应分析。
代码如下:
library(ca);
ch85.csv"
header=T);
data1<
6]);
rownames(data1)<
ca<
-ca(data1);
plot(ca);
ca
Principalinertias(eigenvalues):
12


- 配套讲稿:
如PPT文件的首页显示word图标,表示该PPT已包含配套word讲稿。双击word图标可打开word文档。
- 特殊限制:
部分文档作品中含有的国旗、国徽等图片,仅作为作品整体效果示例展示,禁止商用。设计者仅对作品中独创性部分享有著作权。
- 关 键 词:
- 应用 多元 统计分析 作业
 冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 铝散热器项目年度预算报告.docx
铝散热器项目年度预算报告.docx
-
牛津上海版通用小学英语三年级上册Unit 12同步练习2II 卷.docx
-
论我国私营企业员工激励机制.docx
-
人教版五年级品德与社会上册全册教案.docx
-
开学啦国旗下讲话稿三分钟.docx
-
露天采矿学复习题.docx
-
六年级英语教师年度考核个人总结.docx
-
某路站综合体项PC吊装施工方案.docx
-
人教版九年级历史上册期末考试试题一套.docx
-
隆昌妇幼保健院.docx
-
芦二矿抽采达标中长期规划.docx
-
看拼音写词语.docx
-
模拟磁盘调度算法系统的设计毕业设计.docx
-
每周一条名言警句或一首诗词.docx
-
棉花膜下滴灌示范工程设计总结报告.docx
-
九年级化学教案第十单元酸和碱教案新人教版.docx
-
宁波市水资源公报.docx
-
农业实用技术培训工作意见与农业局上半年工作总结范例两篇汇编.docx
-
平行线的判定.docx
-
内部会计管理制度11成本核算制度.docx
-
盘扣式脚手架支撑方案.docx
-
旅游规划模板.docx
-
煤矿大本大专毕业设计大采高综采工作面作业规程.docx
-
美学选择题整理课件资料.docx
-
名家论腹泻慢性肠炎.docx
-
宁夏银川市第一中学学年高一上学期期中考试地理试题解析解析版.docx
-
年产吨精密纤维纸项目建设建议书.docx
-
农技推广中心工作总结.docx
-
彭宇案的法逻辑批判.docx
-
宁夏仕奇房产网发布份房地产交易情况.docx
-
项目推荐书智能温控节能系统.docx
-
区县节日期间加强消防安全讲话稿与区发改委领导班子述职述廉报告汇编.docx
 公共人力资源管理(中国人民大学).ppt
公共人力资源管理(中国人民大学).ppt
-
公共关系学第1章公共关系概述.ppt
-
公共关系广告.ppt
-
零售连锁业的配货中心管理与配送运输管理.ppt
-
零售环境设计.pptx
-
公共关系学第四章公众分析与心理研究.ppt
-
零缺陷管理PPT培训课件.ppt
-
零售行业-商品管理培训教材.pptx
-
公共关系活动类型.ppt
-
公共关系学课件(第九章).ppt
-
青春之恋分析.ppt
-
公共关系的工作程序.ppt
-
公共关系理论第二章.ppt
-
公共关系实施与评估.ppt
-
公共关系期末考试复习题1.ppt
-
公共决策第二讲.ppt
-
非人力资源经理的人力资源管理培训教材.ppt
-
非常可乐案例.ppt
-
公共关系礼仪.ppt
