 编译原理实验报告词法分析器内含源代码Word文档格式.docx
编译原理实验报告词法分析器内含源代码Word文档格式.docx
- 文档编号:18963970
- 上传时间:2023-01-02
- 格式:DOCX
- 页数:16
- 大小:150.93KB
编译原理实验报告词法分析器内含源代码Word文档格式.docx
《编译原理实验报告词法分析器内含源代码Word文档格式.docx》由会员分享,可在线阅读,更多相关《编译原理实验报告词法分析器内含源代码Word文档格式.docx(16页珍藏版)》请在冰豆网上搜索。
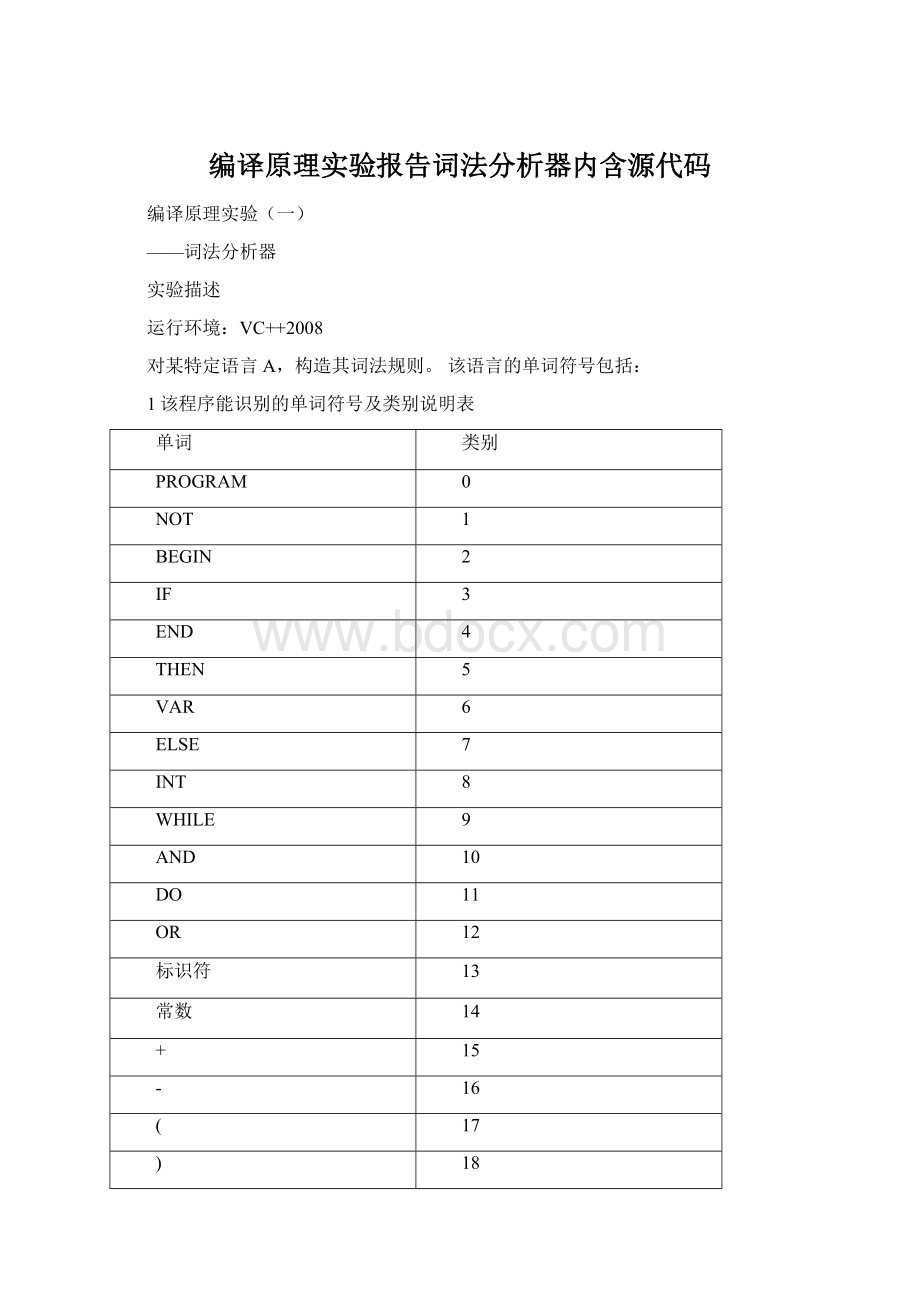
17
)
18
19
20
=
21
<
22
>
23
*
24
**
25
=
26
27
!
28
2状态转换图
數宇
其它
3程序流程:
词法分析作成一个子程序,由另一个主程序调用,每次调用返回一个单词对应的二元组,输出标识符表、常数表由主程序来完成。
2.实验目的
通过动手实践,使学生对构造编译系统的基本理论、编译程序的基本结构有更为深入的理解和掌握;
使学生掌握编译程序设计的基本方法和步骤;
能够设计实现编译系统的重要环节。
同时增强编写和调试程序的能力。
3.实验任务
编制程序实现要求的功能,并能完成对测试样例程序的分析。
四.实验原理
intReserve(char*strTaken);
//对strTaken中的字符串查找保留字表,若是一个保留
字返回它的数码,否则返回0。
voidRetract(char*ch);
//将搜索指针器回调一个字符位置,将ch置为空白字符。
voidinput();
//向存放输入结果的字符数组输入一句语句。
voiddisplay();
//输出一些程序结束字符显示样式
intanalyzerSubFun();
//词法分析器子程序,为了实现词法分析的主要功能。
五.代码实现
//cifa.cpp:
定义控制台应用程序的入口点
//#include"
stdafx.h"
#include"
stdio.h"
string.h"
iostream"
//set[]存储代码,strtaken[]存储当前字符
//存储标识符和常量
的指针
usingnamespacestd;
charset[1000],str[500],strtaken[20];
charsign[50][10],constant[50][10];
//intWords[500][10];
charch;
//当前读入字符intsr,to=0;
//数组str,strtakenintst=0,dcount=0;
intid=0;
staticintline=1;
inth,l;
typedefstructWords/*放置二元组*/{
intnum;
charletters[20];
"
program"
0},"
not"
1},"
begin"
2},"
end"
3},"
if"
4},"
then"
5},"
var"
6},"
else"
7},"
int"
8},"
while"
9},"
and"
10},"
do"
11},"
or"
12},
}DS;
DSWords[500];
typedefstructwords{
charword[20];
inttype;
}WORDS;
WORDSwords[]={
{
{{{{{{{{{{
{"
+"
15},{"
-"
16},{"
("
17},{"
)"
18},
"
19},
;
20},{"
="
21},
22},{"
23},
25},
};
typedefstructkeytable{
charname[20];
intkind;
/*设置关键字*/"
}KEYTABLE;
KEYTABLEkeyword[]={
voidopenfile()/*打开文件*/
cout<
"
<
endl;
词法分析器"
请在本程序根目录下寻找以.txt”为结尾的文件作为词法分析对象,输入文件名"
FILE*fp;
chara,filename[10];
intn=0;
gets(filename);
if((fp=fopen(filename,"
r"
))==NULL)
//exit(0);
}
else
while(!
feof(fp))
a=getc(fp);
set[n]=a;
n++;
printf("
cannotopenfile.\n"
);
/*文件不结束,则循环*/
/*getc函数带回一个字符,赋给a*/
/*文件的每一个字符都放入set[]数组中*/
fclose(fp);
set[n-1]='
\0'
voidreflesh()/*清空strtaken数组*/
to=0;
/*全局变量to是strtaken的指示器*/
strcpy(strtaken,"
voidpre1()/*预处理程序*/
inti,a,b,n=0;
do
if(set[n]=='
/'
&
&
set[n+1]=='
*'
)
a=n;
/*记录第一个注释符的位置*/while(!
(set[n]=='
))
\n'
line++;
b=n+1;
/*记录第二个注释符的位置*/
for(i=a;
i<
=b;
i++)/**/
set[i]='
'
;
/*把注释的内容换成空格,等待第二步预处理*/}
elseif(set[n]=='
set[n]=='
/*记录第二个注释符的位置*/for(i=a;
}while(set[n]!
='
intj=0;
sr=0;
/*全局变量sr是str[]的指示器*/
if
(set[j]=='
||set[j]==
'
while(set[j]==
||set[j]=='
)/*扫描到有连续的空格或换行符
*/
{if(set[j]==
)line++;
j++;
str[sr]=
/*用一个空格代替扫描到的连续空格和换行符放入str[]*/
sr++;
str[sr]=set[j];
/*若当前字符不为空格或换行符就直接放入str[]*/
charGetChar()/*把字符读入全局变量ch中,指示器sr前移*/{
ch=str[sr];
return(str[sr-1]);
}
voidGetBC()/*开始读入符号,直至第一个不为空格*/{
while(ch=='
{ch=GetChar();
voidConcat()/*把ch中的字符放入strtaken[]*/
strtaken[to]=ch;
to++;
/*全局变量to是strtaken的指示器*/
strtaken[to]=
intIsLetter()/*判断是否为字母*/
if((ch>
a'
ch<
z'
)||(ch>
A'
Z'
))return
(1);
elsereturn(0);
intIsDigit()/*判断是否为数字*/
if(ch>
0'
9'
return
(1);
intReserve()/*对strtaken中的字符串查找保留字表,若是则返回它的编码,否则返回-*/{
inti,k=0;
for(i=0;
=12;
i++)
if(stricmp(strtaken,keyword[i].name)==0)
{k=1;
Words[dcount].num=keyword[i].kind;
strcpy(Words[dcount].letters,"
dcount++;
return(keyword[i].kind);
if(k!
=1)
return(-1);
voidRetract()/*指示器sr回调一个字符位置,把ch置为空*/
sr--;
ch='
intInsertId()
inti,k;
id;
{k=strcmp(strtaken,sign[i]);
if(k==0)return(i);
strcpy(sign[id],strtaken);
/*插入标识符*/Words[dcount].num=13;
strcpy(Words[dcount].letters,strtaken);
id++;
return(id-1);
intInsertConst()
st;
k=strcmp(strtaken,constant[i]);
if(k==0)
return(i);
strcpy(constant[st],strtaken);
/*插入常数*/Words[dcount].num=14;
strcpy(Words[dcount].letters,strtaken);
st++;
return(st-1);
voidanalysis()
intvalue;
reflesh();
/*清空strtaken数组*/
pre1();
/*预处理,使注释内容换成单个空格,放回set[]中*/
pre2();
/*预处理,使set[]中连续的空格置换成单个空格,并把set[]的内容放到str[]中*/
GetChar();
/*把字符读入全局变量ch中,指示器sr前移*/
GetBC();
/*读取第一个字符*/
while(ch!
/*当不等于结束符,继续执行*/
if(IsLetter())//标识符和关键字判定
Concat();
for(intc0=15;
c0<
=23;
c0++)
if(stricmp(strtaken,words[c0].word)==0)
Words[dcount].num=words[c0].type;
}reflesh();
break;
default:
if(ch=='
)/*如果是"
*"
符号,继续读取下一个*/{
/*判断是否为"
**"
的情况*/
if(ch==strtaken[0])
Retract();
for(intc1=24;
c1<
=25;
c1++)
if(stricmp(strtaken,words[c1].word)==0)
{Words[dcount].num=words[c1].type;
//printf("
%s"
strtaken);
//getchar();
elseif(ch=='
||ch=='
/*判断是否为<
=,>
=,!
=的情况*/
='
for(intc2=26;
c2<
=28;
c2++)
if(stricmp(strtaken,words[c2].word)==0)
Words[dcount].num=words[c2].type;
dcount++;
{h=ch/line;
l=ch%line;
Errorin"
h<
行"
l<
列"
输出二元组:
for(intd_i=0;
d_i<
dcount;
d_i++)cout<
Words[d_i].num<
Words[d_i].letters<
输出标识符:
for(intsign_i=0;
sign_i<
sign_i++)cout<
sign[sign_i]<
cout<
输出常量:
for(intconst_i=0;
const_i<
const_i++)cout<
constant[const_i]<
int_tmain(intargc,_TCHAR*argv[])
openfile();
analysis();
Analysisisfinished!
getchar();
return0;
测试结果
测试语句为:
Programexample;
varintj,m,n;
Begin/*thereis*a
/comment*/i:
=2;
j:
=6;
m:
=3;
//thereisacommentn:
=j+m;
Ifn>
=3andn<
thenj:
=j-1;
end.
结果截图:
m
ithere
is
A.
Iconsent
脑出常量’
12
六.总结
我在这次词法分析器的设计过程中学到了很多东西,其中最大的收获是对
于编译原理中的词法分析这一过程理解的更加清楚明了。
其次,是在使用C++编
程的能力有所提高。
当然,在该词法分析器设计中也有一些不足的地方,比如能
识别的关键字有限,并不能识别所有的关键字,识别不出字符常量等。
分析结果输出方式为:
用一个存放结果的字符串数组,并用指针指向它,输出结果正确,但是输出结果比较乱。
不过总的来说,这次实验达到了其初衷,实现了规定的功
八.致谢词:
感谢XXX老师对我们的悉心教导以及提供我们这样一个学以致用的机会通过这一阶段对编译原理课程的学习,特别是通过这次对于词法分析器的编程实践,我对于编译原理中的词法分析这一过程理解的更加清楚明了,收获很大。


- 配套讲稿:
如PPT文件的首页显示word图标,表示该PPT已包含配套word讲稿。双击word图标可打开word文档。
- 特殊限制:
部分文档作品中含有的国旗、国徽等图片,仅作为作品整体效果示例展示,禁止商用。设计者仅对作品中独创性部分享有著作权。
- 关 键 词:
- 编译 原理 实验 报告 词法 分析器 内含 源代码
 冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 铝散热器项目年度预算报告.docx
铝散热器项目年度预算报告.docx
-
牛津上海版通用小学英语三年级上册Unit 12同步练习2II 卷.docx
-
论我国私营企业员工激励机制.docx
-
人教版五年级品德与社会上册全册教案.docx
-
开学啦国旗下讲话稿三分钟.docx
-
露天采矿学复习题.docx
-
六年级英语教师年度考核个人总结.docx
-
某路站综合体项PC吊装施工方案.docx
-
人教版九年级历史上册期末考试试题一套.docx
-
隆昌妇幼保健院.docx
-
芦二矿抽采达标中长期规划.docx
-
看拼音写词语.docx
-
模拟磁盘调度算法系统的设计毕业设计.docx
-
每周一条名言警句或一首诗词.docx
-
棉花膜下滴灌示范工程设计总结报告.docx
-
九年级化学教案第十单元酸和碱教案新人教版.docx
-
宁波市水资源公报.docx
-
农业实用技术培训工作意见与农业局上半年工作总结范例两篇汇编.docx
-
平行线的判定.docx
-
内部会计管理制度11成本核算制度.docx
-
盘扣式脚手架支撑方案.docx
-
旅游规划模板.docx
-
煤矿大本大专毕业设计大采高综采工作面作业规程.docx
-
美学选择题整理课件资料.docx
-
名家论腹泻慢性肠炎.docx
-
宁夏银川市第一中学学年高一上学期期中考试地理试题解析解析版.docx
-
年产吨精密纤维纸项目建设建议书.docx
-
农技推广中心工作总结.docx
-
彭宇案的法逻辑批判.docx
-
宁夏仕奇房产网发布份房地产交易情况.docx
-
项目推荐书智能温控节能系统.docx
-
区县节日期间加强消防安全讲话稿与区发改委领导班子述职述廉报告汇编.docx
-
自己动手做漂亮地识字卡有拼音.docx
-
rtk在电力线路测量中的应用.docx
-
癌痛规范化诊疗规范版.docx
-
北京市五年级上册综合实践活动教案集.docx
-
自然拼读练习题1.docx
-
SY51405FUDQ工作原理.docx
-
安徽省宁国市D区学年七年级语文上学期期中联考试题 新人教版.docx
-
北师大版五年级数学下册分数除法三综合练习题30.docx
-
综合素质评价各方面评语.docx
-
VDA67提问表条例.docx
-
安全教育片观后感六篇.docx
-
总领导述职报告两篇.docx
-
被改成广告的历史图片.docx
-
word完整版新人教版一年级数学下册《找规律》教学设计.docx
-
最高人民法院知识产权案件年度报告度.docx
-
案例分析题公路运输doc.docx
-
毕业考题目理财规划师二级专业 技能答案解析.docx
-
XX年度思想政治工作总结.docx
-
最全园林绿化工程施工组织方案.docx
