 spss教程常用的数据描述统计频数分布表等统计学Word下载.docx
spss教程常用的数据描述统计频数分布表等统计学Word下载.docx
- 文档编号:18848614
- 上传时间:2023-01-01
- 格式:DOCX
- 页数:14
- 大小:393.35KB
spss教程常用的数据描述统计频数分布表等统计学Word下载.docx
《spss教程常用的数据描述统计频数分布表等统计学Word下载.docx》由会员分享,可在线阅读,更多相关《spss教程常用的数据描述统计频数分布表等统计学Word下载.docx(14页珍藏版)》请在冰豆网上搜索。
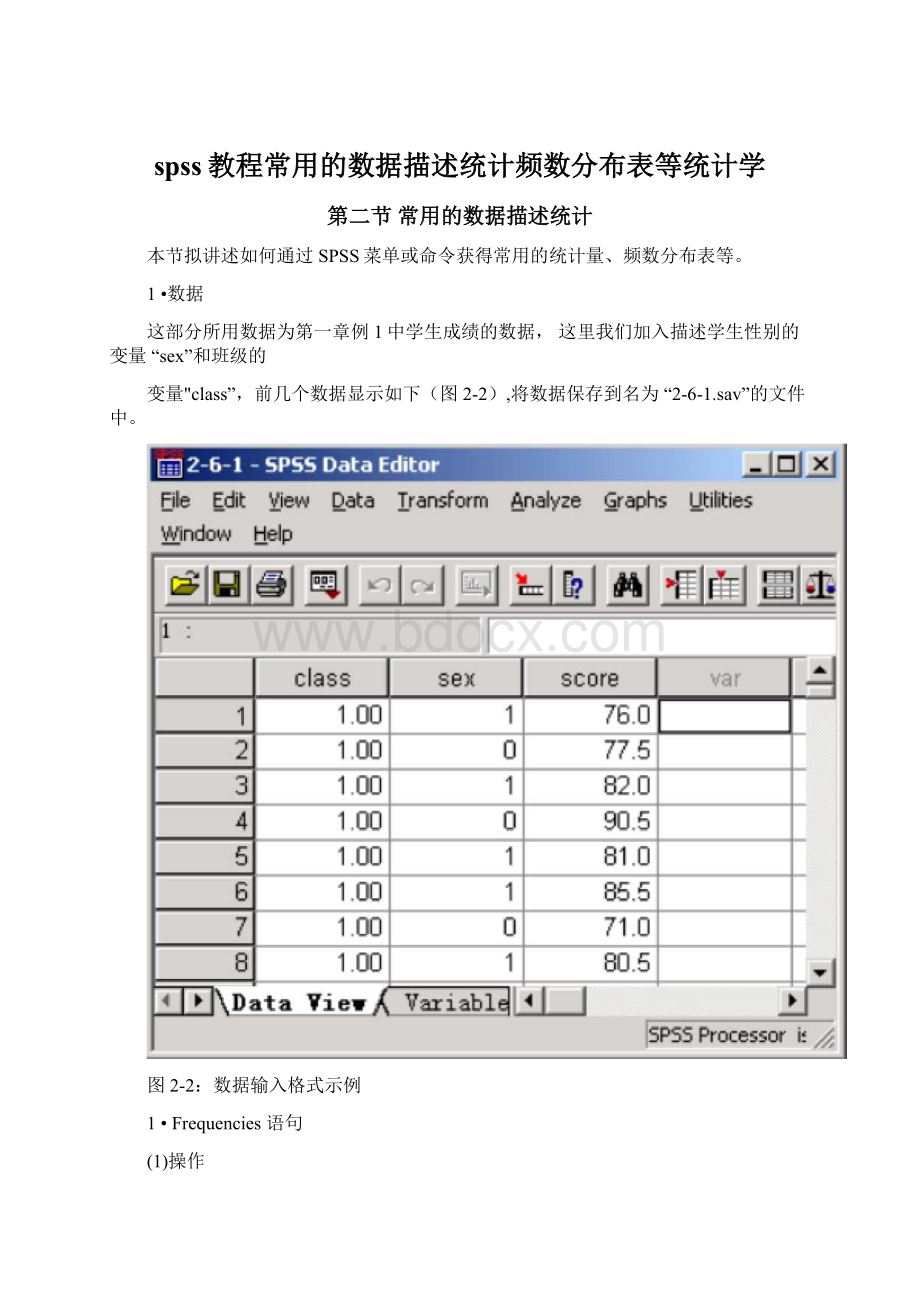
Sum算术和
(iii)在定义输出离散统计量(Dispersion)的矩形框中,选择想要输出的离散统计量,常用的选项有:
Std.Deviation标准差
Varianee方差
Range全距
Minimum最小值
Maximum最大值
S.E.mean平均数的标准误
(iv)描述数据分布(Distribution)的统计量
Skewness偏度,非对称分布指数。
Kurtosis峰度,CASE围绕中心点的扩展程度。
另外,频数过程(Frequenee)除了能够提供上面常用的统计量外,还可以对分组数据计算百分位数和中数
(Valuesaregroupmidpoints),即对于已经分组的数据,并且数据中的原始数据表示的是组中数的数据计算百分位数的值和中位数。
图2-4:
次数分布统计量定义窗口图2-5:
次数分布图形定义窗口
在本例中,我们选择输出:
四分位点的值,平均分为3等分的分位点的值和15%,50%,85%的分位
点的值;
对于集中趋势的度量,选择输出算术平均数、中数、众数和总和,对于离散程度的度量选择输出标准差和方差。
2Charts选项
为了获得统计图表,单击主对话框中的Charts铵钮,打开它的对话框,如图2-5所示。
用户可以在图形类型(ChartType)选择框中定义输出的图形类型,频数(Frequenee)过程可以提供
的输出选项有:
None不显示图表
Barcharts条形图
Piecharts圆形图
Histograms直方图
另外,对于图形中纵坐标值的表示,可以有两种方式:
Frequencies纵座标为变量值的频数
Percentages纵座标为变量值的百分比
在本例中,由于学生成绩可以看成是连续性的数据,所以这里选择输出直方图,并拟合正态曲线。
点击
Continue返回主对话框。
3Format选项
单击Format…,打开Format对话框,如图2-6所示。
在该对话框,可以选择数据输出显示的顺序(Order
by),Frequencies提供的选项有:
Ascendingvalues在输出频数分布表时按变量值升序排列
Descendingvalues在输出频数分布表时按变量值降序排列
Ascendingcounts输出频数分布表时按变量值频数的升序排列
Descendingcounts输出频数表时按变量值频数的降序排列
图2-6:
定义输出显示格式对话框
在Format中我们一律使用默认选项。
点击Continue返回主对话框,在主对话框中点击OK,可以得到次数
分布的输出结果。
(2)结果及解释
①学生成绩变量的Frequences输出描述统计结果
Statistics
SCORE
NValid
100
Missing
Mean
79.68
Median
79.75
Mode
80.(
Std.Deviation
7.02
6
Variance
49.37
1
Sum
7968.
Percentiles15
72.07
5
25
75.0C
33.3333333
376.50
50
66.6666666
82.50
75
84.00
85
87.00
输出说明:
N后面的Valid和Missing分别用来描述有效值样本容量和缺失值的样本个数,在本例所用数据中,有100个有效数字,缺失值的个数为0。
Mean、Median、Mode和Sum分别用来描述算术平均数、中数、众数和数据的总和,本例所用数据的算术平均数为79.680,中数为79.75,众数为80,数据总和为7968.0。
Std.Deviation和Variance分别用来描述数据的标准差和方差,这里数据的标准差为7.026,方差为
49.371。
Percentiles后给出不同的百分位数对应的值,如15后面的数字72.075表示,15%的分位点的值为
72.075,即小于72.075分的人数占总人数的15%。
(表中有两个无穷循环小数,是我们自定义的三等
分的百分位数)
②学生成绩的频数分布表:
Frequency
Percent
ValidPercent
CumulativePercent
Valid62.0
1.0
65.0
2.0
66.0
3.0
67.0
4.0
68.0
5.0
68.5
6.0
69.0
7.0
70.0
8.0
70.5
9.0
71.0
3
12.0
71.5
13.0
72.0
2
15.0
72.5
16.0
73.0
18.0
73.5
20.0
74.0
22.0
74.5
24.0
75.0
27.0
75.5
29.0
76.0
32.0
76.5
34.0
77.0
36.0
77.5
38.0
78.0
41.0
78.5
43.0
79.0
4
47.0
79.5
50.0
80.0
55.0
80.5
58.0
81.0
61.0
81.5
63.0
82.0
82.5
83.0
83.5
84.0
84.5
85.0
85.5
86.0
86.5
87.0
87.5
88.0
88.5
89.0
91.0
89.5
92.0
90.0
93.0
90.5
94.0
95.0
92.5
96.0
97.0
98.0
99.0
100.0
Total
100
在输出的频数分布表中,第一列给出数据中出现的不同数值;
第二列给出该数值对应的频数
(Frequency);
第三列给出对应数据在总数据中所占的百分比(Percent);
第四列给出有效百分比(Valid
percent)即去除缺失值后的百分比,由于在此例中不含有缺失值所以该列数据与第三列相同;
最后一列给出累加百分比(Cumulativepercent)。
如数据70,对应的频数为1,表示在这组数据中70出现了1次,所占比例和有效百分比都是1%,累计百分比8%表示小于等于70的人数占总人数的8%。
2.Descriptives
仍以上面所用数据为例,简单说明另外一种常用的输出描述统计量的过程一Descriptive。
打开数据文
件"
2-6-1.sav”,
•Descriptive^
单击主菜单Analyze/DescriptiveStatistics/Descriptives•;
•打开主对话框如图2-7所示:
OK
Paste
Reset
Cancel
Help
图2—7:
Descriptives定义窗口
将左边变量表列中的class、sex和scores变量选到右边的变量表列(Variable(s))中。
注意选中下方
Savestandardizedvaluesasvariables复选框,即要求把该变量值的标准分存为一变量,并在数据窗口中显示
(请注意在执行完操作后自行查看结果,新生成的变量名称分别为zclass、zsex和zscore)。
图2—8:
Descriptives的options窗口
①options选项
单击options••按钮,打开描述统计过程的选择输出对话框(Descriptives:
Options),设置如图2-8所示:
请注意,这里所给出的一些统计量,与在Frequencies中所给的相差无几。
所以,当我们需要用到这
些描述统计量的时候,可以不受一种特殊方法的限制。
在此不再对这些统计量作过多说明,如有不解之处,
请参阅Frequencies部分。
在图2—8的下方,提供了有关输出显示顺序(DisplayOrder)的定义框:
Variablelist变量表列中变量的排列顺序为数据窗口中的顺序
Alphabetic按字母顺序
Ascendingmeans按平均数的升序排列
Descendingmeans按平均数的降序排列
定义完成后,点击Continue,返回主对话框,点击0K,可以得到的输出结果。
DescriptiveStatistics
N
Range
Minimum
Maximum
Mean
Std.
Deviation
Varianee
StatisticStatistic
Statistic
Std.Error
CLASS
2.00
1.00
3.00
205.00
2.0500
8.087E-02
.8087
.654
SEX
48
.48
5.02E-02
.50
.252
62.0
7968.0
79.680
.703
7.026
49.371
ValidN
(listwise)
结果解释:
上表分别给出三个变量(class,sex和score)的样本容量、全距、最小值、最大值、和、均值、
标准误、标准差和方差。
如对于学生分数(score)对应一行的输出结果显示:
该组数据所含样本容量为100
(N=100),最高分与最低分的差为36,即全距为36(Range=36)、最低分数为62分,即最小值为62(Minimum
=62);
最高分数为98分,即最大值为98(Maximum=98);
100个学生分数总和为7968(Sum=7968);
平均分79.68分(Mean=79.68),标准误为0.703(Std.Error=0.703)、标准差为7.026(Std.Deviation=7.026)和方差为49.371(Variance=49.371)。
再返回数据编辑(DataEditor)窗口,数据中多了三列数据分别命名为zclass,zsex和zscore,对应于三
个变量的标准分数。
3.求分组平均数(Means命令)
有时我们常常需要求不同组的平均数和标准差,如对于上面所描述的资料,研究者往往预了解三个班
级每个班学生的平均学习成绩等信息。
SPSS提供了用于描述分组数据描述统计量的过程----Means,下面
仍用上面的数据介绍这一过程的具体应用。
打开数据文件"
2-6-1.sav”,单击主菜单Analyze/CompareMeans/Means…,打开Means对话框,将score选入右边的Dependentlist对话框,将class选入右边的Independentlist对话框。
如下图2-9所示:
图2-9:
Means语句主对话框图2-10:
Means的Options窗口
我们的目的在于计算不同班级学生的平均成绩和标准差。
①Options选项
在主对话框单击Options按钮,打开选择(Options)输出对话框如图2-10所示:
左面是统计量表列,包含一些常用的统计量,我们在Frequencies与Descriptives中做过说明,在此从
略。
右边三项:
Mean平均数
Numberofcases样本容量
Standarddeviation标准差
是默认的统计量,如果需要计算其他的统计量,可以将左侧统计量选入右侧。
这里我们采用默认的选项。
点击Continue返回主对话框,然后点击OK,得到最后的统计结果。
①所用CASE的情况
包括有效值与缺失值的实际数目及所占百分比。
CaseProcessingSummary
Cases
Included
Excluded
SCORE*CLASS100
100.0%
.0%
上面输出结果表明,在分析的100个数据中,有效数据100个,排除在分析之外的数据个数为零,说明在
分析的这一组数据中不含有缺失数据。
②结果报告表:
各班的平均数、标准差、每个班级的人数
Std.Deviation
79.733
30
6.579
80.557
35
7.288
78.757
7.215
6.579分;
2班学生
35人,这次考试成
79.680分,标准差
上述结果表明1班学生人数为30人,这次考试成绩的平均分数为79.733分,标准差为人数为35人,这次考试成绩的平均分数为80.557分,标准差为7.288分;
3班学生人数为绩的平均分数为79.757分,标准差为7.215分;
三个班总学生人数为100人,总平均分数为为7.026分。


- 配套讲稿:
如PPT文件的首页显示word图标,表示该PPT已包含配套word讲稿。双击word图标可打开word文档。
- 特殊限制:
部分文档作品中含有的国旗、国徽等图片,仅作为作品整体效果示例展示,禁止商用。设计者仅对作品中独创性部分享有著作权。
- 关 键 词:
- spss 教程 常用 数据 描述 统计 频数 分布 统计学
 冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 对中国城市家庭的教育投资行为的理论和实证研究.docx
对中国城市家庭的教育投资行为的理论和实证研究.docx
-
二年级下册数学练习题大全.docx
-
二十年后回故乡的优秀作文.docx
-
软基换填施工方案.docx
-
《黑白装饰画》教案.docx
-
课堂教学改革实施方案5篇.docx
-
返璞归真简约致美解读《给予树》教学设计语文.docx
-
离职证明范本精选多篇.docx
-
《天局》全文.docx
-
我害怕作文集合15篇.docx
-
伏魔战记39详细攻略.docx
-
幼儿园学期计划.docx
-
雅思分类打印版Word格式文档下载.docx
-
年产1万吨竹子纤维加工项目可行性研究报告文档格式.docx
-
电商产业化项目投资经营商业计划书Word文件下载.docx
-
医学多媒体课件的设计与制作Word文档格式.docx
-
中学生中秋节想象作文Word格式.docx
-
等保20之漏洞扫描系统技术方案建议书Word文档格式.docx
-
培训学校个人工作计划模板5篇Word格式.docx
-
北京各区二模试题分类汇编文言文阅读Word文档下载推荐.docx
-
不同职业病危害因素的防护常识Word格式文档下载.docx
-
一年级上册同音形近字练习汇总Word文档格式.docx
-
班级家长会上班主任教师讲话稿Word下载.docx
-
科斯塔环载波恢复Word文件下载.docx
-
浙教义务版六年级语文下册教案 花潮Word文件下载.docx
-
集成电路设计与集成系统专业Word格式文档下载.docx
-
开工第一课专题讲座观后感文档格式.docx
-
东城区学年第一学期高三期末化学试题及答案Word格式文档下载.docx
-
苏教版六年级语文下册第七单元测试题Word格式文档下载.docx
-
学长征精神做红色传人活动方案文档格式.docx
-
读书笔记150字30篇文档格式.docx
-
中级经济法考前必背法条精华版备考资料Word格式.docx
 六西格玛培训PPT资料.ppt
六西格玛培训PPT资料.ppt
-
物业违章停车提示Word格式.doc
-
物权法自动续期法律问题Word文档格式.docx
-
物业管理企业应对《劳动合同法》的几点建议Word文档下载推荐.doc
-
信息社会责任目标解读PPT推荐.pptx
-
物权法司法解释Word文件下载.doc
-
物业费收费依据法规汇总Word文档格式.doc
-
信托、资管、有限合伙、银行理财概念与区别PPT课件下载推荐.pptx
-
物业管理部门管理条例Word文件下载.docx
-
物业管理常用法律法规解读Word文档格式.docx
-
兰博基尼发展史PPT推荐.ppt
-
物有所值定性评价专家打分表Word文件下载.doc
-
物资借用申请Word文件下载.doc
-
信息系统审计PPT文档格式.ppt
-
信息资源管理前沿第一周优质PPT.ppt
-
物业管理服务招标文件保洁绿化Word文件下载.doc
-
兰州张掖路--兰州的“王府井”优质PPT.pptx
-
物联网发展专项行动计划(2013-2015年)(完整全文)Word下载.docx
-
共建“秦巴国际生态旅游圈”的若干思考优质PPT.pptx
