 中国科学院大学现代信息检索课后习题答案Word文档格式.docx
中国科学院大学现代信息检索课后习题答案Word文档格式.docx
- 文档编号:18837212
- 上传时间:2023-01-01
- 格式:DOCX
- 页数:22
- 大小:128.22KB
中国科学院大学现代信息检索课后习题答案Word文档格式.docx
《中国科学院大学现代信息检索课后习题答案Word文档格式.docx》由会员分享,可在线阅读,更多相关《中国科学院大学现代信息检索课后习题答案Word文档格式.docx(22页珍藏版)》请在冰豆网上搜索。
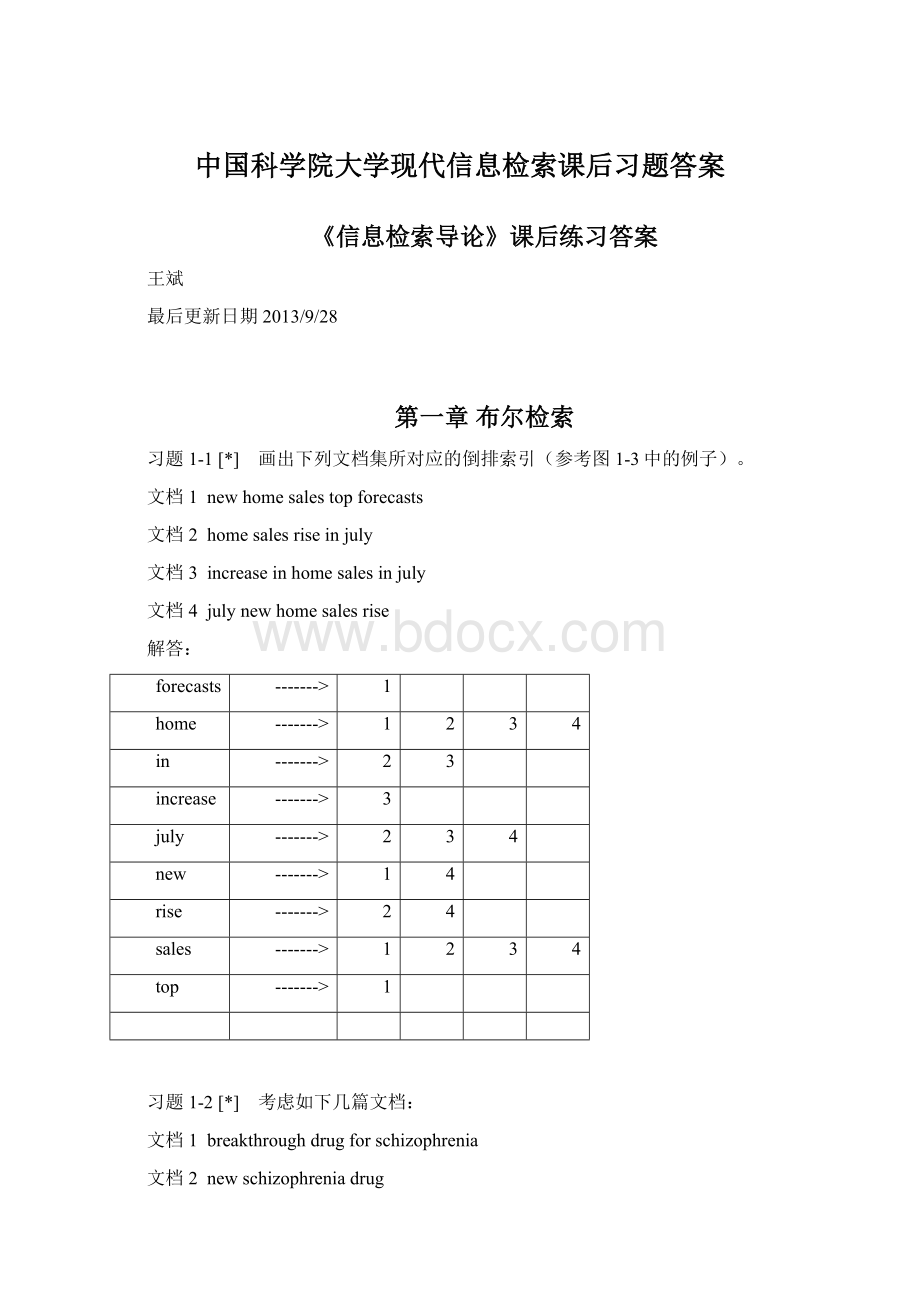
approach
breakthrough
drug
for
hopes
of
patients
schizophrenia
treatment
b.画出该文档集的倒排索引(参考图1-3中的例子)。
参考a。
习题1-3[*] 对于习题1-2中的文档集,如果给定如下查询,那么返回的结果是什么?
a.schizophreniaANDdrug
{文档1,文档2}
b.forANDNOT(drugORapproach)
{文档4}
习题1-4[*]对于如下查询,能否仍然在O(x+y)次内完成?
其中x和y分别是Brutus和Caesar所对应的倒排记录表长度。
如果不能的话,那么我们能达到的时间复杂度是多少?
a.BrutusANDNOTCaesar
b.BrutusORNOTCaesar
a.可以在O(x+y)次内完成。
通过集合的减操作即可。
具体做法参考习题1-11。
b.不能。
不可以在O(x+y)次内完成。
因为NOTCaesar的倒排记录表需要提取其他所有词项对应的倒排记录表。
所以需要遍历几乎全体倒排记录表,于是时间复杂度即为所有倒排记录表的长度的和N,即O(N)或者说O(x+N-y)。
习题1-5[*]将倒排记录表合并算法推广到任意布尔查询表达式,其时间复杂度是多少?
比如,对于查询
c.(BrutusORCaesar)ANDNOT(AntonyORCleopatra)
我们能在线性时间内完成合并吗?
这里的线性是针对什么来说的?
我们还能对此加以改进吗?
时间复杂度为O(qN),其中q为表达式中词项的个数,N为所有倒排记录表长度之和。
也就是说可以在词项个数q及所有倒排记录表长度N的线性时间内完成合并。
由于任意布尔表达式处理算法复杂度的上界为O(N),所以上述复杂度无法进一步改进。
习题1-6[**] 假定我们使用分配律来改写有关AND和OR的查询表达式。
a.通过分配律将习题1-5中的查询写成析取范式;
b.改写之后的查询的处理过程比原始查询处理过程的效率高还是低?
c.上述结果对任何查询通用还是依赖于文档集的内容和词本身?
a.析取范式为:
(BrutusAndNotAnthonyAndNotCleopatra)OR(CaesarANDNOTAnthonyANDNOTCleopatra)
b.这里的析取范式处理比前面的合取范式更有效。
这是因为这里先进行AND操作(括号内),得到的倒排记录表都不大,再进行OR操作效率就不会很低。
而前面需要先进行OR操作,得到的中间倒排记录表会更大一些。
c.上述结果不一定对,比如两个罕见词A和B构成的查询(AORB)ANDNOT(HONGORKONG),假设HONGKONG一起出现很频繁。
此时合取方式可能处理起来更高效。
如果在析取范式中仅有词项的非操作时,b中结果
不对。
习题1-7[*] 请推荐如下查询的处理次序。
d.(tangerineORtrees)AND(marmaladeORskies)AND(kaleidoscopeOReyes)
其中,每个词项对应的倒排记录表的长度分别如下:
词项倒排记录表长度
eyes213312
kaleidoscope87009
marmalade107913
skies271658
tangerine46653
trees316812
由于:
(tangerineORtrees)46653+316812=363465
(marmaladeORskies)107913+271658=379571
(kaleidoscopeOReyes)87009+213312=30321
所以推荐处理次序为:
(kaleidoscopeOReyes)AND(tangerineORtrees)AND(marmaladeORskies)
习题1-8[*]对于查询
e.friendsANDromansAND(NOTcountrymen)
如何利用countrymen的文档频率来估计最佳的查询处理次序?
特别地,提出一种在确定查询顺序时对逻辑非进行处理的方法。
令friends、romans和countrymen的文档频率分别为x、y、z。
如果z极高,则将N-z作为NOTcountrymen的长度估计值,然后按照x、y、N-z从小到大合并。
如果z极低,则按照x、y、z从小到大合并。
习题1-9[**] 对于逻辑与构成的查询,按照倒排记录表从小到大的处理次序是不是一定是最优的?
如果是,请给出解释;
如果不是,请给出反例。
不一定。
比如三个长度分别为x,y,z的倒排记录表进行合并,其中x>
y>
z,如果x和y的交集为空集,那么有可能先合并x、y效率更高。
习题1-10[**] 对于查询xORy,按照图1-6的方式,给出一个合并算法。
1answer<
-()
2whilep1!
=NILandp2!
=NIL
3doifdocID(p1)=docID(p2)
4thenADD(answer,docID(p1))
5p1<
-next(p1)
6p2<
-next(p2)
7elseifdocID(p1)<
docID(p2)
8thenADD(answer,docID(p1))
9p1<
10elseADD(answer,docID(p2))
11p2<
12ifp1!
=NIL//x还有剩余
13thenwhilep1!
=NILdoADD(answer,docID(p1))
14elsewhilep2!
=NILdoADD(answer,docID(p2))
15return(answer)
习题1-11[*]如何处理查询xANDNOTy?
为什么原始的处理方法非常耗时?
给出一个针对该查询的高效合并算法。
由于NOTy几乎要遍历所有倒排表,因此如果采用列举倒排表的方式非常耗时。
可以采用两个有序集合求减的方式处理xANDNOTy。
算法如下:
Meger(p1,p2)
1answer()
3doifdocID(p1)=docID(p2)
4thenp1next(p1)
5p2next(p2)
6elseifdocID(p1)<
7thenADD(answer,docID(p1))
8p1next(p1)
9elseADD(answer,docID(p2))
10p2next(p2)
11ifp1!
12thenwhilep1!
13return(answer)
习题1-12[*] 利用Westlaw系统的语法构造一个查询,通过它可以找到professor、teacher或lecturer中的任意一个词,并且该词和动词explain在一个句子中出现,其中explain以某种形式出现。
professorteacherlecturer/sexplain!
习题1-13[*] 在一些商用搜索引擎上试用布尔查询,比如,选择一个词(如burglar),然后将如下查询提交给搜索引擎
(i)burglar;
(ii)burglarANDburglar;
(iii)burglarORburglar。
对照搜索引擎返回的总数和排名靠前的文档,这些结果是否满足布尔逻辑的意义?
对于大多数搜索引擎来说,它们往往不满足。
你明白这是为什么吗?
如果采用其他词语,结论又如何?
比如以下查询
(i)knight;
(ii)conquer;
(iii)knightORconquer。
第二章词汇表和倒排记录表
习题2-1[*] 请判断如下说法是否正确。
a.在布尔检索系统中,进行词干还原从不降低正确率。
b.在布尔检索系统中,进行词干还原从不降低召回率。
c.词干还原会增加词项词典的大小。
d.词干还原应该在构建索引时调用,而不应在查询处理时调用。
a错b对c错d错
习题2-7[*] 考虑利用如下带有跳表指针的倒排记录表
和一个中间结果表(如下所示,不存在跳表指针)进行合并操作。
3 5 89 95 97 99 100 101
采用图2-10所示的倒排记录表合并算法,请问:
a.跳表指针实际跳转的次数是多少(也就是说,指针p1的下一步将跳到skip(p1))?
一次,24—>
75
b.当两个表进行合并时,倒排记录之间的比较次数是多少?
【如下答案不一定正确,有人利用程序计算需要21次,需要回到算法,本小题不扣分,下面不考虑重新比较同意对数字】
18次:
<
3,3>
<
5,5>
9,89>
15,89>
<
24,89>
75,89>
92,89>
81,89>
84,89>
89,89>
92,95>
115,95>
96,95>
96,97>
97,97>
100,99>
100,100>
<
115,101>
c.如果不使用跳表指针,那么倒排记录之间的比较次数是多少?
19次:
39,89>
60,89>
68,89>
习题2-9[*] 下面给出的是一个位置索引的一部分,格式为:
词项:
文档1:
〈位置1,位置2,…〉;
文档2:
〈位置1,位置2,…〉。
angels:
2:
〈36,174,252,651〉;
4:
〈12,22,102,432〉;
7:
〈17〉;
fools:
〈1,17,74,222〉;
〈8,78,108,458〉;
〈3,13,23,193〉;
fear:
〈87,704,722,901〉;
〈13,43,113,433〉;
〈18,328,528〉;
in:
〈3,37,76,444,851〉;
〈10,20,110,470,500〉;
〈5,15,25,195〉;
rush:
〈2,66,194,321,702〉;
〈9,69,149,429,569〉;
〈4,14,404〉;
to:
〈47,86,234,999〉;
〈14,24,774,944〉;
〈199,319,599,709〉;
tread:
〈57,94,333〉;
〈15,35,155〉;
〈20,320〉;
where:
〈67,124,393,1001〉;
〈11,41,101,421,431〉;
〈16,36,736〉;
那么哪些文档和以下的查询匹配?
其中引号内的每个表达式都是一个短语查询。
a.“foolsrushin”。
文档2、4、7
b.“foolsrushin”AND“angelsfeartotread”。
解答:
文档4
第三章词典及容错式检索
习题3-5 再次考虑3.2.1节中的查询fi*mo*er,如果采用2-gram索引的话,那么对应该查询应该会产生什么样的布尔查询?
你能否举一个词项的例子,使该词匹配3.2.1节的轮排索引查询,但是并不满足刚才产生的布尔查询?
2-gram索引下的布尔查询:
$fANDfiANDmoANDerANDr$
词项filibuster(海盗)满足3.2.1节的轮排索引查询,但是并不满足上述布尔查询
习题3-7 如果|si|表示字符串si的长度,请证明s1和s2的编辑距离不可能超过max{|s1|,|s2|}。
证明:
不失一般性,假设|s1|<
=|s2|,将s1转换为s2的一种做法为:
将s1中的每个字符依次替换为s2中的前|s1|个字符,然后添加s2的后|s2|-|s1|个字符,上述操作的总次数为|s2|=max{|s1|,|s2|},根据编辑距离的定义,其应该小于|s2|=max{|s1|,|s2|}
习题3-8 计算paris和alice之间的编辑距离,给出类似于图3-5中的算法结果,其中的5×
5矩阵包含每个前缀子串之间的计算结果。
习题3-11 考虑四词查询catchedintherye,假定根据独立的词项拼写校正方法,每个词都有5个可选的正确拼写形式。
那么,如果不对空间进行缩减的话,需要考虑多少可能的短语拼写形式(提示:
同时要考虑原始查询本身,也就是每个词项有6种变化可能)?
6*6*6*6=1296
习题3-14 找出两个拼写不一致但soundex编码一致的专有名词。
Mary,Mira(soundex相同),本题答案不唯一,可能有其他答案,但是soundex编码必须一致。
第四章索引构建
习题4-1 如果需要Tlog2T次比较(T是词项ID—文档ID对的数目),每次比较都有两次磁盘寻道过程。
假定使用磁盘而不是内存进行存储,并且不采用优化的排序算法(也就是说不使用前面提到的外部排序算法),那么对于Reuters-RCV1构建索引需要多长时间?
计算时假定采用表4-1中的系统参数。
对于Reuters-RCV1,T=108
因此排序时间(文档分析时间可以忽略不计)为:
2*(108*log2108)*5*10-3s=26575424s=7382h=308day
习题4-3 对于n=15个数据片,r=10个分区文件,j=3个词项分区,假定使用的集群的机器的参数如表4-1所示,那么在MapReduce构架下对Reuters-RCV1语料进行分布式索引需要多长时间?
【给助教:
教材不同印刷版本表4-2不一样,不同同学用的不同版本,还有本题过程具有争议。
暂不扣分】
解答【整个计算过程是近似的,要了解过程】:
(一)、MAP阶段【读入语料(已经不带XML标记信息了,参考表5-6),词条化,写入分区文件】:
(1)读入语料:
基于表4-2,ReutersRCV1共有8*105篇文档,每篇文档有200词条,每个词条(考虑标点和空格)占6B,因此整个语料库的大小为8*105*200*6=9.6*108B(近似1GB,注表4-2对应于表5-1第3行的数据,而那里的数据已经经过去数字处理,因此实际的原始文档集大小应该略高于0.96G,这里近似计算,但是不要认为没有处理就得到表5-1第3行的结果)
将整个语料库分成15份,则每份大小为9.6*108/15B
每一份读入机器的时间为:
9.6*108/15*2*10-8=1.28s
(2)词条化:
每一份语料在机器上进行词条化处理,得到8*105*200=1.6*108个词项ID-文档ID对(参考表4-2和图4-6,注意此时重复的词项ID-文档ID对还没有处理),共占1.6*108*8=1.28*109个字节,词条化的时间暂时忽略不计【从题目无法得到词条化这一部分时间,从表5-1看词条化主要是做了去数字和大小写转换,当然也感觉这一部分的处理比较简单,可以忽略】。
(3)写入分区文件:
每一份语料得到的词项ID-文档ID(Key-Value)存储到分区所花的时间为:
(1.28*109/15)*2*10-8=1.71s
(4)MAP阶段时间:
由于分成15份,但只有10台机器进行MAP操作,所以上述MAP操作需要两步,因此,整个MAP过程所需时间为(1.28+1.71)*2=6.0s
(二)、REDUCE阶段【读入分区文件,排序,写入倒排索引】:
(1)读入分区文件【读入过程中已经实现所有Key-Value对中的Value按Key聚合,即变成Key,list(V1,V2..)。
聚合过程在内存中实现,速度很快,该时间不计。
另外,网络传输时间这里也不计算】:
根据表4-2,所有倒排记录的数目为1.6*108,因此3台索引器上每台所分配的倒排记录数目为1.6*108/3,而每条记录由4字节词项ID和4字节文档ID组成,因此每台索引器上需要读入的倒排记录表数据为1.28*109/3字节。
于是,每台索引器读数据的时间为1.28*109/3*2*10-8=8.5s
(2)排序:
每台索引器排序所花的时间为1.6*108/3*log2(1.6*108/3)*10-8=13.7s
(3)写入倒排索引文件【此时倒排文件已经实现文档ID的去重,假定只存储词项ID和文档ID列表,并不存储其他信息(如词项的DF及在每篇文档中的TF还有指针等等)】:
需要写入磁盘的索引大小为(据表4-2,词项总数为4*105个)4*105/3*4+108/3*4=4/3*108字节
索引写入磁盘的时间为:
4/3*108*2*10-8=2.7s
(4)REDUCE阶段时间为:
8.5+13.7+2.7=24.9
(三)因此,整个分布式索引的时间约为6.0+8.5+13.7+2.7=30.9s
第五章索引压缩
习题5-2 估计Reuters-RCV1文档集词典在两种不同按块存储压缩方法下的空间大小。
其中,第一种方法中k=8,第二种方法中k=16。
每8个词项会节省7*3个字节,同时增加8个字节,于是每8个词项节省7*3-8=13字节,所有词项共节省13*400000/8=650K,因此,此时索引大小为7.6MB-0.65MB=6.95MB
每16个词项会节省15*3个字节,同时增加16个字节,于是每16个词项节省15*3-16=29字节,所有词项共节省29*400000/16=725K,因此,此时索引大小为7.6MB-0.725MB=6.875MB
习题5-6 考虑倒排记录表(4,10,11,12,15,62,63,265,268,270,400)及其对应的间距表(4,6,1,1,3,47,1,202,3,2,130)。
假定倒排记录表的长度和倒排记录表分开独立存储,这样系统能够知道倒排记录表什么时候结束。
采用可变字节码:
(i)能够使用1字节来编码的最大间距是多少?
(ii)能够使用2字节来编码的最大间距是多少?
(iii)采用可变字节编码时,上述倒排记录表总共需要多少空间(只计算对这些数字序列进行编码的空间消耗)?
(i)27-1=127(答128也算对,因为不存在0间距,0即可表示间距1,……)
(ii)214-1=16383(答16384也算对)
(iii)1+1+1+1+1+1+1+2+1+1+2=13
习题5-8[*] 对于下列采用γ编码的间距编码结果,请还原原始的间距序列及倒排记录表。
111000*********1111101101111011
1110001;
11010;
101;
11111011011;
11011
1001;
110;
11;
111011;
111
9;
6;
3;
32+16+8+2+1=59;
7
15;
18;
77;
84
第六章文档评分、词项权重计算及向量空间模型
习题6-10 考虑图6-9中的3篇文档Doc1、Doc2、Doc3中几个词项的tf情况,采用图6-8中的idf值来计算所有词项car、auto、insurance及best的tf-idf值。
Doc1
Doc2
Doc3
car
27
24
auto
33
insurance
29
best
14
17
图6-9 习题6-10中所使用的tf值
idfcar=1.65,idfauto=2.08,idfinsurance=1.62,idfbest=1.5,
于是,各词项在各文档中的tf-idf结果如下表:
27*1.65=44.55
4*1.65=6.6
24*1.65=39.6
3*2.08=6.24
33*2.08=68.64
33*1.62=53.46
29*1.62=46.98
14*1.5=21
17*1.5=25.5
习题6-12 公式(6-7)中对数的底对公式(6-9)会有什么影响?
对于给定查询来说,对数的底是否会对文档的排序造成影响?
没有影响。
假定idf采用与(6-


- 配套讲稿:
如PPT文件的首页显示word图标,表示该PPT已包含配套word讲稿。双击word图标可打开word文档。
- 特殊限制:
部分文档作品中含有的国旗、国徽等图片,仅作为作品整体效果示例展示,禁止商用。设计者仅对作品中独创性部分享有著作权。
- 关 键 词:
- 中国科学院 大学 现代 信息 检索 课后 习题 答案
 冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 铝散热器项目年度预算报告.docx
铝散热器项目年度预算报告.docx
-
牛津上海版通用小学英语三年级上册Unit 12同步练习2II 卷.docx
-
论我国私营企业员工激励机制.docx
-
人教版五年级品德与社会上册全册教案.docx
-
开学啦国旗下讲话稿三分钟.docx
-
露天采矿学复习题.docx
-
六年级英语教师年度考核个人总结.docx
-
某路站综合体项PC吊装施工方案.docx
-
人教版九年级历史上册期末考试试题一套.docx
-
隆昌妇幼保健院.docx
-
芦二矿抽采达标中长期规划.docx
-
看拼音写词语.docx
-
模拟磁盘调度算法系统的设计毕业设计.docx
-
每周一条名言警句或一首诗词.docx
-
棉花膜下滴灌示范工程设计总结报告.docx
-
九年级化学教案第十单元酸和碱教案新人教版.docx
-
宁波市水资源公报.docx
-
农业实用技术培训工作意见与农业局上半年工作总结范例两篇汇编.docx
-
平行线的判定.docx
-
内部会计管理制度11成本核算制度.docx
-
盘扣式脚手架支撑方案.docx
-
旅游规划模板.docx
-
煤矿大本大专毕业设计大采高综采工作面作业规程.docx
-
美学选择题整理课件资料.docx
-
名家论腹泻慢性肠炎.docx
-
宁夏银川市第一中学学年高一上学期期中考试地理试题解析解析版.docx
-
年产吨精密纤维纸项目建设建议书.docx
-
农技推广中心工作总结.docx
-
彭宇案的法逻辑批判.docx
-
宁夏仕奇房产网发布份房地产交易情况.docx
-
项目推荐书智能温控节能系统.docx
-
区县节日期间加强消防安全讲话稿与区发改委领导班子述职述廉报告汇编.docx
-
幼儿园安全工作总结写.docx
-
HCDA题库.docx
-
Frenchay构音障碍评定.docx
-
ICE3500原子吸收光谱仪确认方案.docx
-
GMAT真题9.docx
-
java实习工作总结1200字.docx
-
幼儿园沙池活动.docx
-
LAMMPS讲课教案.docx
-
幼儿园小班班周计划表.docx
-
LTE小区重选规则.docx
-
幼儿园新生家长会的发言稿.docx
-
NPN和PNP输出电路和PLC输入模块的连接.docx
-
幼儿园中班语言小树叶会说话教案.docx
-
幼小衔接教学常规落实教学设计说明.docx
-
预拌商品混凝土进场验收单.docx
-
MILKRUN实施具体细节.docx
-
PMP网上培训考试试题集.docx
-
玉器文化的心得体会.docx
-
QC七手法新.docx
