 SPSS上机实验报告Word格式.docx
SPSS上机实验报告Word格式.docx
- 文档编号:18830206
- 上传时间:2023-01-01
- 格式:DOCX
- 页数:31
- 大小:376.09KB
SPSS上机实验报告Word格式.docx
《SPSS上机实验报告Word格式.docx》由会员分享,可在线阅读,更多相关《SPSS上机实验报告Word格式.docx(31页珍藏版)》请在冰豆网上搜索。
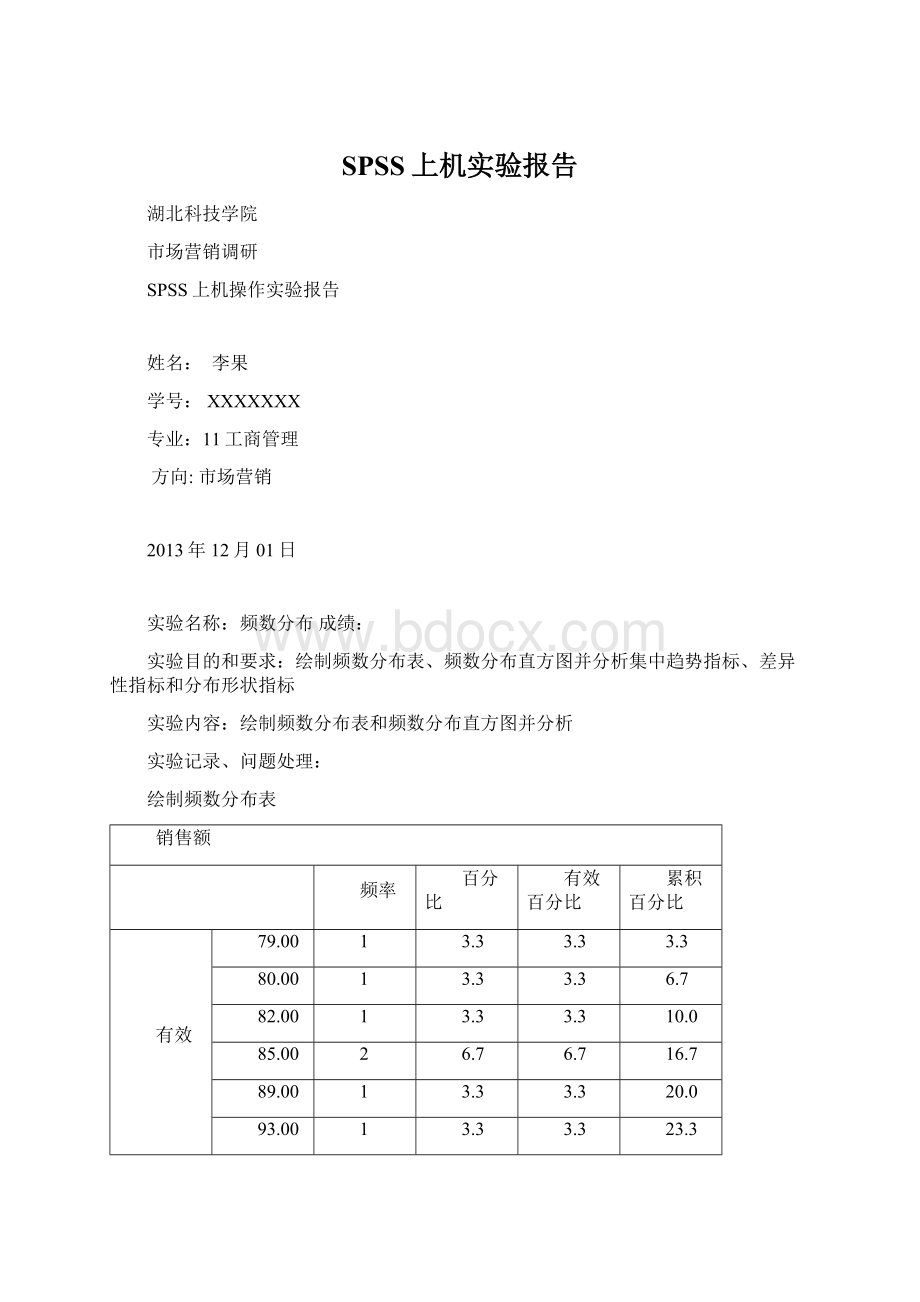
70.0
113.00
73.3
114.00
76.7
115.00
80.0
124.00
83.3
129.00
90.0
130.00
96.7
190.00
100.0
合计
30
频数分布直方图
集中趋势指标、差异性指标和分布形状指标
统计量
N
缺失
均值
106.8333
均值的标准误
3.97755
中值
105.0000
众数
85.00a
标准差
21.78592
方差
474.626
偏度
1.915
偏度的标准误
.427
峰度
6.297
峰度的标准误
.833
全距
111.00
极小值
极大值
和
3205.00
a.存在多个众数。
显示最小值
实验结果分析:
从统计量表可以看出有效样本数有30个,没有缺失值。
平均销售额是106.8333,标准差为21.78592。
从频数分布表可以看出样本值、频数占总数的百分比、累计百分比。
从带正态曲线的直方图可以看出销售额集中在110
列联表成绩:
绘制频数表、相对频数表并进行显著性检验和关系强度分析
绘制频数表、相对频数表并分析
满意度*性别交叉制表
性别
男性
女性
满意度
不满意
计数
19
8
27
满意度中的%
70.4%
29.6%
100.0%
性别中的%
35.2%
17.4%
27.0%
总数的%
19.0%
8.0%
一般
23
21
44
52.3%
47.7%
42.6%
45.7%
44.0%
23.0%
21.0%
满意
12
17
29
41.4%
58.6%
22.2%
37.0%
29.0%
12.0%
17.0%
54
46
100
54.0%
46.0%
卡方检验
值
df
渐进Sig.(双侧)
Pearson卡方
4.825a
.090
似然比
4.931
.085
线性和线性组合
4.650
.031
有效案例中的N
a.0单元格(0.0%)的期望计数少于5。
最小期望计数为12.42。
对称度量
近似值Sig.
按标量标定
φ
.220
Cramer的V
a.不假定零假设。
b.使用渐进标准误差假定零假设。
从卡方检验看出sig>
0.05,不显著。
所以男生女生对满意与否评价没有差异
方差分析成绩:
单因子方差分析、多因子方差和协方差分析
进行单因子方差分析并输出方差分析表、显著性检验及解释结果、多因子方差和协方差分析并输出方差分析表和协方差分析表、显著性检验及解释结果。
单因子方差分析
分析——比较均值,单因素——键入销售额为因变量,键入促销力度为因子——两两比较打钩L检验,选项方差齐性检验打钩得:
ANOVA
平方和
均方
F
显著性
组间
7250.667
22
329.576
170.891
.000
组内
13.500
7
1.929
总数
7264.167
多因子方差分析
分析——一般线性模型,单变量——键入店内促销和赠券状态为固定因子,销售额为因变量——两两比较打钩L检验,选项方差齐性检验打钩,得:
主体间效应的检验
因变量:
源
III型平方和
Sig.
校正模型
162.667a
5
32.533
33.655
截距
1104.133
1142.207
店内促销
106.067
53.033
54.862
赠券状态
53.333
55.172
店内促销*赠券状态
3.267
1.633
1.690
.206
误差
23.200
24
.967
总计
1290.000
校正的总计
185.867
a.R方=.875(调整R方=.849)
协方差分析
分析——一般线性模型,单变量——键入店内促销和赠券状态为固定因子,销售额为因变量,键入客源排序为协变量——两两比较打钩L检验,选项方差齐性检验打钩,得:
163.505a
6
27.251
28.028
103.346
106.294
客源排序
.838
.862
.363
54.546
54.855
1.680
.208
22.362
.972
a.R方=.880(调整R方=.848)
单因子:
组间显著性为0.000,小于0.05,显著影响。
多因子:
店内促销和赠券状态显著性分别都为0.000,小于0.05,显著影响。
但是店内促销和赠券状态交互作用的显著性为0.206,大于0.05,不显著。
协方差:
经协变量客源排序的显著性为0.363,对销售额影响不显著。
店内促销的显著性为0.000,小于0.05,对销售额影响显著。
赠券状态的显著性为0.000,小于0.05,对销售额影响显著。
店内促销和赠券状态的交互作用显著性为0.208,大于0.05,对销售额影响不显著
相关分析成绩:
计算Pearson相关系数和简单相关系数并分析
分析——相关,双变量——添加收、家庭人口、受教育程度、汽车保有量——默认pearson分析——确定,得:
相关性
收入
家庭人口
家长受教育年数
汽车保有量
Pearson相关性
-.008
.327**
.208*
显著性(双侧)
.936
.001
.038
.122
.576**
.226
.207*
.039
**.在.01水平(双侧)上显著相关。
*.在0.05水平(双侧)上显著相关。
1、收入对受教育年数,相关系数为0.327,显著性为0.001,小于0.01,所以收入和受教育年为正向相关,且相关性很强。
2、收入对汽车保有量,相关系数为0.208,显著性为0.038,小于0.05,所以收入对汽车保有量为正向相关。
3、家庭人口对汽车保有量,相关系数为0.576,显著性为0.000,小于0.01,所以收入对汽车保有量为正向相关,且相关性很强。
4、受教育年数对收入,相关系数为0.327,显著性为0.001,小于0.01,所以受教育年数对收入为正想相关,且相关性很强。
回归分析成绩:
掌握简单回归模型和多元回归分析的SPSS操作方法
检验简单回归模型、绘制散点图、输出回归结果并分析、残差分析;
检验多元回归分析模型、输出回归结果并分析及残差分析。
(一)简单回归
得出
模型汇总
模型
R
R方
调整R方
标准估计的误差
.754a
.569
.554
1.691
a.预测变量:
(常量),促销水平。
Anovaa
回归
105.800
36.999
.000b
残差
80.067
28
2.860
a.因变量:
月均销售额
b.预测变量:
系数a
非标准化系数
标准系数
t
B
标准误差
试用版
(常量)
10.667
.817
13.059
促销水平
-2.300
.378
-.754
-6.083
R方为0.554,拟合优度一般。
P值sig显著
表达式:
销售额=10.667-2.3*促销水平
(二)多元线性回归
得:
.925b
.856
.846
.995
(常量),店内促销。
(常量),店内促销,赠券状态。
159.133
79.567
80.360
.000c
26.733
.990
销售额
c.预测变量:
14.667
.727
20.183
.222
-10.337
-2.667
-.536
-7.339
R方在第二次拟合达到0.856,说明模型的拟合的情况非常好
方差分析表显示P值sig<
0.05,说明模型非常显著。
销售额=14.667-2.3*店内促销-2.667*赠券状态
Logistic回归成绩:
掌握Logistic回归分析的SPSS操作方法
估计和检验Logistic回归系数并解释结果。
得出:
分类表a
已观测
已预测
品牌忠诚
百分比校正
步骤1
3
总计百分比
a.切割值为.500
方程中的变量
S.E,
Wals
Exp(B)
步骤1a
品牌态度
1.274
.479
7.075
.008
3.575
产品态度
.186
.322
.335
.563
1.205
购物态度
.590
.491
1.442
.230
1.804
常量
-8.642
3.346
6.672
.010
a.在步骤1中输入的变量:
品牌态度,产品态度,购物态度.
结果显示:
品牌忠诚=1.274*品牌态度+0.186*产品态度+0.590*购物态度-8.462
其中品牌态度的sig小于0.05,所以品牌态度与品牌购买正向变化显著。
但是因为产品态度和购物态度的sig大于0.05,所以这两个变量与品牌购买的正向变化不显著
因子分析成绩:
掌握因子分析的SPSS操作方法
KMO和Barlett氏检验;
输出碎石图及旋转前后的因子矩阵;
各因子的特征值和解释的方差比例;
解释因子并命名;
计算因子得分。
步骤处理:
分析——降维——因子分析
将度量变量键入变量框,
选取描述,勾选KMO与bartlett球形度检验
选取抽取,勾选碎石图
选取旋转,勾选载荷图
选取得分,勾选保存变量和因子得分系数矩阵
KMO和Bartlett的检验
取样足够度的Kaiser-Meyer-Olkin度量。
.589
Bartlet
t的球形度检验
近似卡方
101.749
15
如图所示:
解释的总方差
成份
初始特征值
提取平方和载入
方差的%
累积%
2.569
42.821
2.272
37.868
80.690
.431
7.188
87.878
4
.345
5.743
93.621
.305
5.091
98.712
.077
1.288
100.000
提取方法:
主成份分析。
成份矩阵a
预防蛀牙
.940
.189
牙齿亮泽
-.241
.814
保护牙根
.930
.059
口气清新
-.311
.800
不预防坏牙
-.808
-.386
富有魅力
-.112
.884
提取方法:
主成分分析法。
a.已提取了2个成份。
旋转成份矩阵a
.957
-.047
-.034
.849
.916
-.171
-.105
.852
-.878
-.176
.108
旋转法:
具有Kaiser标准化的正交旋转法。
a.旋转在3次迭代后收敛。
成份得分系数矩阵
.366
.083
-.094
.358
.362
.026
-.121
.352
-.315
-.170
-.044
.389
构成得分。
KMO值为0.589,sig值为0.000,适合作因子分析
各因子的特征值和解释的方差比例可以在“解释的总方差”中看出,其中我们可以知道,特征值2.569和2.272可以解释方差比例分别是42.821%和37.868%。
因为因子1在预防蛀牙、保护牙根有很大载荷,所以将其命名为保健因子。
因子2在牙齿亮泽、口气清新、富有魅力有很大载荷,所以将其命名为社交因子。
计算因子得分,得
保健因子=0.366*预防蛀牙-0.094*牙齿亮泽+0.362*保护牙龈-0.121*口气清新-0.315*不预防坏牙-0.044*富有魅力
社交因子=0.083*预防蛀牙+0.358*牙齿亮泽+0.026*保护牙根+0.352*口气清新-0.170*不预防坏牙+0.389*富有魅力
聚类分析成绩:
掌握分层聚类和K-means聚类的SPSS操作方法
进行分层聚类和K-means聚类分析并输出结果。
分层聚类:
分析——分类——系统聚类
将度量变量键入变量框,勾选统计量中的聚类成员中的方案范围,并且设置为最小3最大5.
勾选绘制中的树状图
打开保存选项卡,勾选聚类成员中的方案范围,设置最小3最大5
结果如图所示:
聚类表
阶
群集组合
系数
首次出现阶群集
下一阶
群集1
群集2
14
16
2.000
10
3.000
13
11
9
4.000
4.333
4.500
5.000
7.250
20
7.333
8.250
10.750
18
11.300
14.000
20.200
38.611
48.292
群集成员
案例
5群集
4群集
3群集
*******************HIERARCHICALCLUSTERANALYSIS*******************
DendrogramusingAverageLinkage(BetweenGroups)
RescaledDistanceClusterCombine
CASE0510152025
LabelNum+---------+---------+---------+---------+---------+
14-+
16-+-+
10-++-+
4---++-------------+
19-----++-------------------+
18-------------------+|
2-+-------++---------+
13-+|||
5-+-++--


- 配套讲稿:
如PPT文件的首页显示word图标,表示该PPT已包含配套word讲稿。双击word图标可打开word文档。
- 特殊限制:
部分文档作品中含有的国旗、国徽等图片,仅作为作品整体效果示例展示,禁止商用。设计者仅对作品中独创性部分享有著作权。
- 关 键 词:
- SPSS 上机 实验 报告
 冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 铝散热器项目年度预算报告.docx
铝散热器项目年度预算报告.docx
-
牛津上海版通用小学英语三年级上册Unit 12同步练习2II 卷.docx
-
论我国私营企业员工激励机制.docx
-
人教版五年级品德与社会上册全册教案.docx
-
开学啦国旗下讲话稿三分钟.docx
-
露天采矿学复习题.docx
-
六年级英语教师年度考核个人总结.docx
-
某路站综合体项PC吊装施工方案.docx
-
人教版九年级历史上册期末考试试题一套.docx
-
隆昌妇幼保健院.docx
-
芦二矿抽采达标中长期规划.docx
-
看拼音写词语.docx
-
模拟磁盘调度算法系统的设计毕业设计.docx
-
每周一条名言警句或一首诗词.docx
-
棉花膜下滴灌示范工程设计总结报告.docx
-
九年级化学教案第十单元酸和碱教案新人教版.docx
-
宁波市水资源公报.docx
-
农业实用技术培训工作意见与农业局上半年工作总结范例两篇汇编.docx
-
平行线的判定.docx
-
内部会计管理制度11成本核算制度.docx
-
盘扣式脚手架支撑方案.docx
-
旅游规划模板.docx
-
煤矿大本大专毕业设计大采高综采工作面作业规程.docx
-
美学选择题整理课件资料.docx
-
名家论腹泻慢性肠炎.docx
-
宁夏银川市第一中学学年高一上学期期中考试地理试题解析解析版.docx
-
年产吨精密纤维纸项目建设建议书.docx
-
农技推广中心工作总结.docx
-
彭宇案的法逻辑批判.docx
-
宁夏仕奇房产网发布份房地产交易情况.docx
-
项目推荐书智能温控节能系统.docx
-
区县节日期间加强消防安全讲话稿与区发改委领导班子述职述廉报告汇编.docx
-
大学生面试经验心得大全.docx
-
初级经济师考试《建筑经济专业知识与实务》真题及答案.docx
-
电气专业英语.docx
-
初三化学试题精选九年级化学下册一课一测8金属和金属材料83金属资源的利用和保护试题附答案.docx
-
工程招标代理服务方案说明.docx
-
初三暑假学习计划表5篇.docx
-
工程合同付款方式范本.docx
-
高老头读书笔记.docx
-
吊篮相关计算书.docx
-
电梯安全管理制度2.docx
-
高三化学二轮复习 专题能力提升练十九 第一篇 专题通.docx
-
工商管理论文21780.docx
-
初中半命题作文给我的启示作文500字600字800字.docx
-
东莞市劳动合同范本版.docx
-
工程质量控制关键环节点.docx
-
初中滑轮组经典好题30道答案详尽.docx
-
东莞理工学院 工程实训中心安全考试试题.docx
-
工资管理系统设计开发实施可行性研究方案.docx
-
汉语拼音最全组合.docx
