 5哈夫曼编码和译码的算法设计与实现1Word文档下载推荐.docx
5哈夫曼编码和译码的算法设计与实现1Word文档下载推荐.docx
- 文档编号:18431143
- 上传时间:2022-12-16
- 格式:DOCX
- 页数:22
- 大小:20.11KB
5哈夫曼编码和译码的算法设计与实现1Word文档下载推荐.docx
《5哈夫曼编码和译码的算法设计与实现1Word文档下载推荐.docx》由会员分享,可在线阅读,更多相关《5哈夫曼编码和译码的算法设计与实现1Word文档下载推荐.docx(22页珍藏版)》请在冰豆网上搜索。
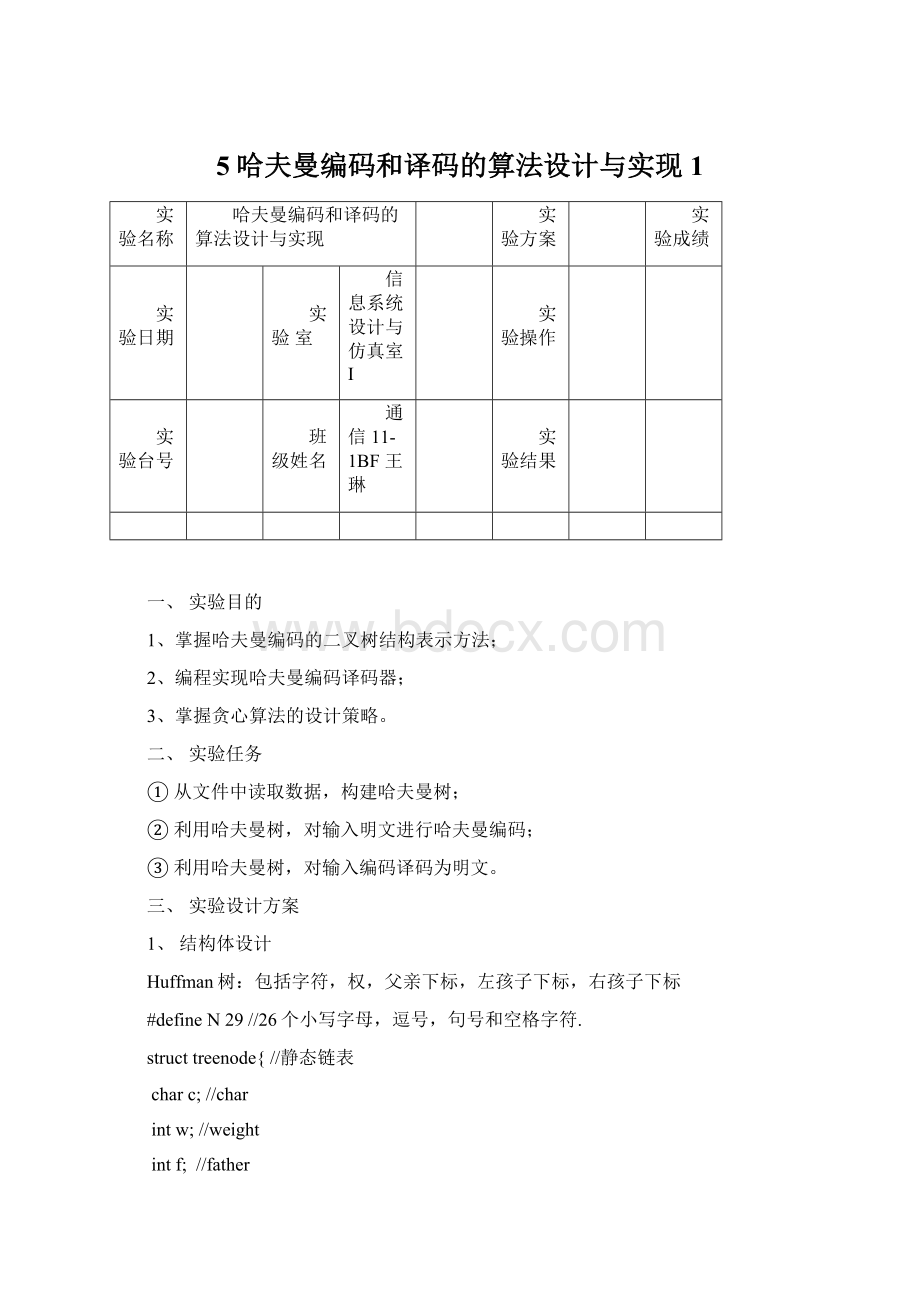
charc;
//char
intw;
//weight
intf;
//father
intl;
//leftchildindex
intr;
//rightchildindex
};
structtreenodehtree[2*N-1];
2、自定义函数设计
1函数原型声明
voidinput();
//读取文件字符、权值数据
voidhuffman();
//建立huffman树
voidgetcode(inti,char*str);
//得到单个字符的huffman编码
voidencode(charch);
//将明文进行huffman编码
voiddecode(char*str);
//将huffman编码译为明文
②读取文件字符、权值数据
voidinput()
{
inti;
freopen("
in.txt"
"
r"
stdin);
for(i=0;
i<
N;
i++)
{
c=getchar();
//接收字符
scanf("
%d"
&
f);
//接收权值
getchar();
//接收回车
ht[i].c=c;
ht[i].w=f;
ht[i].l=ht[i].f=ht[i].r=-1;
//初始化父亲、左右孩子下标
}
freopen("
CON"
"
stdin);
}
③建立huffman树
//使用贪心法建立huffman树,每次选择权值最小的根结点
voidhuffman()
intj,k,n;
input();
j=0;
k=N;
for(n=N;
n<
2*N-1;
n++){//建立huffman树,共合并N-1次
intr=0,s=0;
ht[n].l=ht[n].f=ht[n].r=-1;
while(r<
2){//选择两个最小的权值结点
if((ht[k].w==0||ht[k].w>
ht[j].w)&
&
j<
N){
s+=ht[j].w;
if(r==0)ht[n].l=j;
//修改父亲、孩子下标
elseht[n].r=j;
ht[j].f=n;
j++;
}
else{
s+=ht[k].w;
if(r==0)ht[n].l=k;
//修改父亲、孩子下标
elseht[n].r=k;
ht[k].f=n;
k++;
}
r++;
}
ht[n].w=s;
//修改权值
④根据字符下标找到字符的huffman编码
//根据字符所在的下标,从叶子结点往上搜索到根节点,然后逆置得到该字符的huffman编码
voidgetcode(inti,char*str){
intn,j,l=0;
for(n=i;
ht[n].f!
=-1;
n=ht[n].f){//沿着父亲往上搜索
intm=ht[n].f;
if(n==ht[m].l)
str[l++]='
0'
;
//左孩子记为0
else
1'
//右孩子记为1
for(j=0;
j<
=(l-1)/2;
j++){//将编码逆置
chart;
t=str[j];
str[j]=str[l-1-j];
str[l-1-j]=t;
str[l]=0;
//str存放huffman编码,字符串结束标记
⑤读入明文生成huffman编码
voidencode(charch)
charstr[N];
ht[i].c!
=0;
if(ht[i].c==ch)//找字符下标
break;
if(ht[i].c!
=0)
getcode(i,str);
//得到字符的huffman编码
printf("
%s"
str);
⑥将huffman编码串译码为明文
voiddecode(char*str){
while(*str!
='
\0'
){
inti;
for(i=2*N-2;
ht[i].l!
if(*str=='
)
i=ht[i].l;
else
i=ht[i].r;
str++;
%c"
ht[i].c);
}
3、主函数设计
思路:
主函数实现实验任务的基本流程。
voidmain()
charch;
charstr[100];
huffman();
printf("
请输入明文:
"
);
//输入明文
while((ch=getchar())!
\n'
encode(ch);
//得到huffman编码
\n"
\n请按字符编码对应表输入密文:
i++)//显示字符编码对应表
%c:
encode(ht[i].c);
\t"
scanf("
//输入编码串
decode(str);
//翻译成明文
}
四、测试
1、字符权值数据存放在in.txt文件中:
j217
z309
q343
x505
k1183
w1328
v1531
f1899
.2058
y2815
b2918
g3061
3069
h3724
d4186
m4241
p4283
u4910
5005
c6028
s6859
l6882
n7948
o8259
t8929
r9337
i9364
a10050
e11991
2、测试
输入明文:
you
输出编码:
111011*********
输入编码:
010*********
输入解码:
love
五、总结与讨论
1、问题与错误
对程序的思路不明确,算法也不是很懂。
2、经验与收获
了解了新算法,有所接触
3、改进与设想
六、源代码
#include<
stdio.h>
#include<
stdlib.h>
string.h>
#defineN29
structtreenodeht[2*N-1];
n++){
2){
n=ht[n].f){
j++){//inverse
if(ht[i].c==ch)//找到字符
=0)
通信11-1BF段思楠
一、实验目的
二、实验任务
三、实验设计方案
2函数原型声明
四、测试
五、总结与讨论
对算法思路不是很清晰
6、源代码
while(*st


- 配套讲稿:
如PPT文件的首页显示word图标,表示该PPT已包含配套word讲稿。双击word图标可打开word文档。
- 特殊限制:
部分文档作品中含有的国旗、国徽等图片,仅作为作品整体效果示例展示,禁止商用。设计者仅对作品中独创性部分享有著作权。
- 关 键 词:
- 哈夫曼 编码 译码 算法 设计 实现
 冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 转基因粮食的危害资料摘编Word下载.docx
转基因粮食的危害资料摘编Word下载.docx
-
高中英语词组大全Word文档下载推荐.docx
-
卫计局年工作总结及新年工作计划Word格式.docx
-
贵州省煤矿安全管理人员安全资格证A考试概况Word格式.docx
-
系统集成项目招标文件Word文件下载.docx
-
消防设计技术审查的要点Word文档格式.docx
-
第三章 习题课 带电粒子在磁场或复合场中的运动Word格式.docx
-
湖南岳阳中考英语模拟卷含答案Word文档格式.docx
-
电子商务考试题总汇打印版打印打印Word下载.docx
-
选调生考试备考言语理解与表达真题Word文档格式.docx
-
高考物理实验题专练 专练15Word文档格式.docx
-
加装奥迪A4L蓝牙电话功能Word文档下载推荐.docx
-
学年下学期好教育高三月考仿真卷A卷 语文 学生版后附详解Word文档下载推荐.docx
-
净化生产车间工程一般施工技术施工方案Word文档格式.docx
-
内蒙古呼和浩特市第六中学学年高一政治下学期期末考试试题Word下载.docx
-
证券行业客户经理电话营销技巧与实例Word文档下载推荐.docx
-
叶芝 苇间风文档格式.docx
-
最新中美贸易摩擦的原因及解决对策1论文Word文件下载.docx
-
意义的近义词Word格式文档下载.docx
-
上海市中考英语试题S.docx
-
专题12观点论证类设问.docx
-
附加安心重疾条款.docx
-
设计变更管理办法修改意见稿FINAL汇编.docx
-
毕业赠言毕业致词精选多篇.docx
-
银行新员工代表发言稿精选多篇.docx
-
北京市朝阳区届高三第一学期期末语文试题Word版含答案.docx
-
HL线切割使用说明书模板.docx
-
车工实训周记.docx
-
USBHID键盘扫描码.docx
-
Apmpoqu4调研报告.docx
-
最熟悉的陌生人作文八篇.docx
-
被动语态综合讲解.docx
-
商杭高速铁路上场质量培训.docx
-
a修kv电缆作业包.docx
-
七年级数学试题参考解答及评分意见.docx
-
项目部节能减排责任制考核表.docx
-
PANTONE专色色彩配方指南中英文对照.docx
-
人教版三年级数学下册除数是一位数的除法综合练习题197.docx
-
出口食品生产企业卫生注册登记管理规定精编WORD版.docx
-
大学食堂投标书样本模板经典版拟定样本.docx
-
放假安全承诺书.docx
-
珠算教案第一章.docx
-
钢丝绳卸荷计算实例完整版.docx
-
BanyanTree悦榕庄奢华酒店品牌研究.docx
-
人教版小学数学一年级下册教案第四单元100以内数的认识docx.docx
-
普通话考试命题说话技巧提纲以及.docx
-
Word操作题重点学习的知识点重点学习的汇总doc.docx
-
全科医疗大纲.docx
-
人教版七年级数学下册期末考试试题及答案.docx
-
人教版三年级下册品德与社会全套说课稿.docx
-
数控加工实训报告.docx
