 MEGA说明书Word文档格式.docx
MEGA说明书Word文档格式.docx
- 文档编号:17571882
- 上传时间:2022-12-07
- 格式:DOCX
- 页数:13
- 大小:1.06MB
MEGA说明书Word文档格式.docx
《MEGA说明书Word文档格式.docx》由会员分享,可在线阅读,更多相关《MEGA说明书Word文档格式.docx(13页珍藏版)》请在冰豆网上搜索。
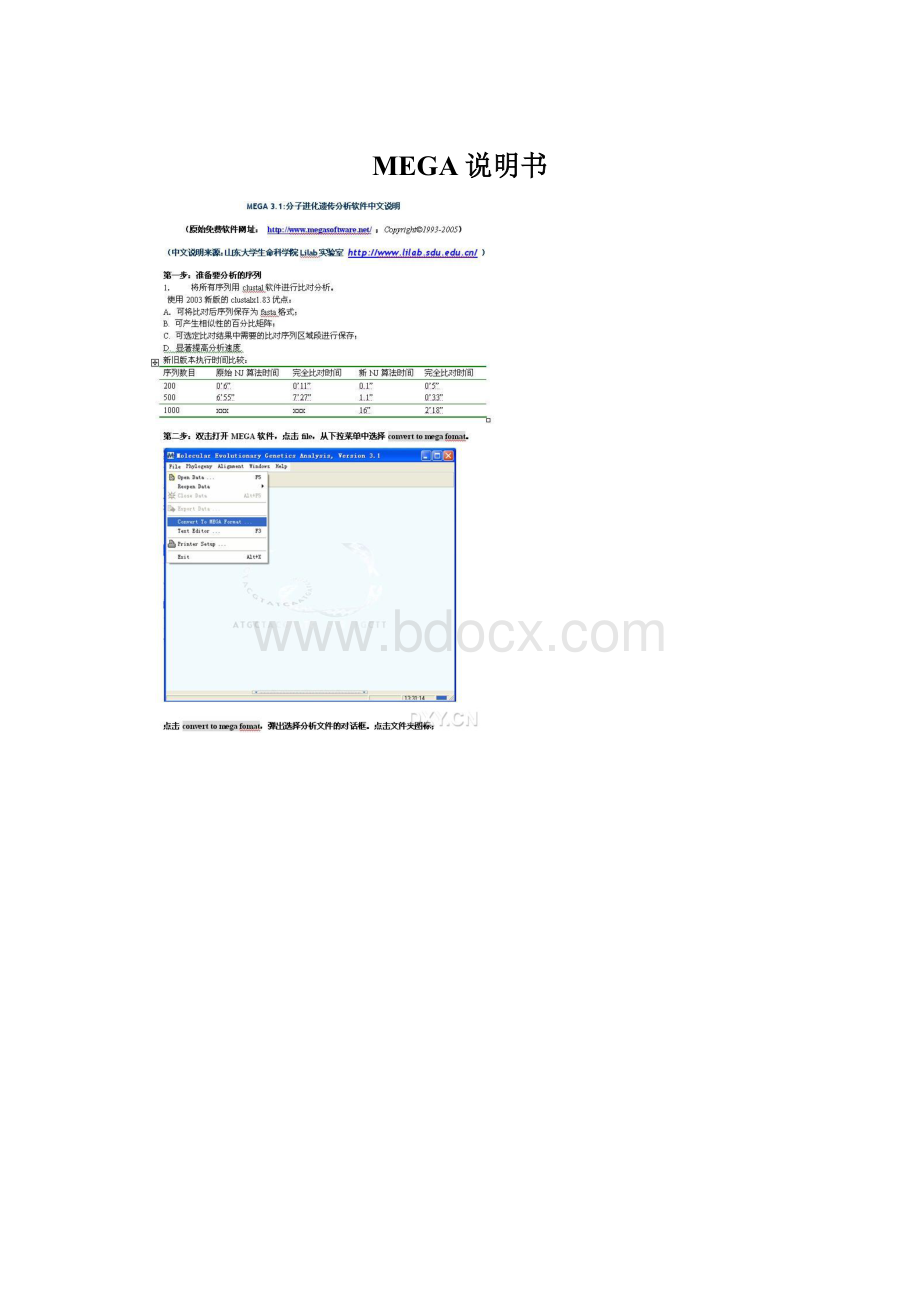
用boostraptest中的ME法得到的是XXX树,请问与上个树比,哪个更好”,等等。
3.关于软件的选择。
例如,“想做一个进化树,不知道什么软件能更好的使用且可以说明问题,并且有没有说明如何做”,“拿到了16srRNA数据,打算做一个系统进化树分析,可是原来没有做过这方面的工作啊,都要什么软件”,“请问各位高手用clustalx做出来的进化树与phylip做的有什么区别”,“请问有做过进化树分析的朋友,能不能提供一下,做树的时候参数的设置,以及代表的意思。
还有各个分支等数值的意思,说明的问题等”,等等。
4.蛋白家族的分类问题。
例如,“搜集所有的关于一个特定domain的序列,共141条,做的进化树不知具体怎么分析”,等等。
5.新基因功能的推断。
例如,“根据一个新基因A氨基酸序列构建的系统发生树,这个进化树能否说明这个新基因A和B同源,属于同一基因家族”,等等。
6.计算基因分化的年代。
例如,“想在基因组水平比较两个或三个比较接近物种之间的进化年代的远近,具体推算出他们之间的分歧时间”,“如何估计病毒进化中变异所需时间”,等等。
7.进化树的编辑。
例如生成的进化树图片,如何进行后续的编辑,比如希望在图片上标注某些特定的内容,等等。
由于相关的帖子太多,作者在这里对无法阅读全部的相关内容而致以歉意。
同时,作者归纳的这七个问题也并不完全代表所有的提问。
对于问题1所涉及到的基本的概念,作者推荐读者可参考由MasatoshiNei与SudhirKumar所撰写的《分子进化与系统发育》(MolecularEvolutionandPhylogenetics)一书,以及相关的分子进化方面的最新文献。
对于问题7,作者之一lylover一般使用Powerpoint进行编辑,而Photoshop、Illustrator及Windows自带的画图工具等都可以使用。
这里,作者在这里对问题2-6进行简要地解释和讨论,并希望能够初步地解答初学者的一些疑问。
二、方法的选择
首先是方法的选择。
基于距离的方法有UPGMA、ME(MinimumEvolution,最小进化法)和NJ(Neighbor-Joining,邻接法)等。
其他的几种方法包括MP(Maximumparsimony,最大简约法)、ML(Maximumlikelihood,最大似然法)以及贝叶斯(Bayesian)推断等方法。
其中UPGMA法已经较少使用。
一般来讲,如果模型合适,ML的效果较好。
对近缘序列,有人喜欢MP,因为用的假设最少。
MP一般不用在远缘序列上,这时一般用NJ或ML。
对相似度很低的序列,NJ往往出现Long-branchattraction(LBA,长枝吸引现象),有时严重干扰进化树的构建。
贝叶斯的方法则太慢。
对于各种方法构建分子进化树的准确性,一篇综述(HallBG.MolBiolEvol2005,22(3):
792-802)认为贝叶斯的方法最好,其次是ML,然后是MP。
其实如果序列的相似性较高,各种方法都会得到不错的结果,模型间的差别也不大。
对于NJ和ML,是需要选择模型的。
对于各种模型之间的理论上的区别,这里不作深入的探讨,可以参看Nei的书。
对于蛋白质序列以及DNA序列,两者模型的选择是不同的。
以作者的经验来说,对于蛋白质的序列,一般选择PoissonCorrection(泊松修正)这一模型。
而对于核酸序列,一般选择Kimura2-parameter(Kimura-2参数)模型。
如果对各种模型的理解并不深入,作者并不推荐初学者使用其他复杂的模型。
Bootstrap几乎是一个必须的选项。
一般Bootstrap的值>
70,则认为构建的进化树较为可靠。
如果Bootstrap的值太低,则有可能进化树的拓扑结构有错误,进化树是不可靠的。
对于进化树的构建,如果对理论的了解并不深入,作者推荐使用缺省的参数。
需要选择模型的时候(例如用NJ或者ML建树),对于蛋白序列使用PoissonCorrection模型,对于核酸序列使用Kimura-2参数模型。
另外需要做Bootstrap检验,当Bootstrap值过低时,所构建的进化树其拓扑结构可能存在问题。
并且,一般推荐用两种不同的方法构建进化树,如果所得到的进化树类似,则结果较为可靠。
三、软件的选择
表1中列出了一些与构建分子进化树相关的软件。
构建NJ树,可以用PHYLIP(写得有点问题,例如比较慢,并且Bootstrap检验不方便)或者MEGA。
MEGA是Nei开发的方法并设计的图形化的软件,使用非常方便。
作者推荐MEGA软件为初学者的首选。
虽然多雪列比对工具ClustalW/X自带了一个NJ的建树程序,但是该程序只有p-distance模型,而且构建的树不够准确,一般不用来构建进化树。
构建MP树,最好的工具是PAUP,但该程序属于商业软件,并不对学术免费。
因此,作者并不建议使用PAUP。
而MEGA和PHYLIP也可以用来构建进化树。
这里,作者推荐使用MEGA来构建MP树。
理由是,MEGA是图形化的软件,使用方便,而PHYLIP则是命令行格式的软件,使用较为繁琐。
对于近缘序列的进化树构建,MP方法几乎是最好的。
构建ML树可以使用PHYML,速度最快。
或者使用Tree-puzzle,速度也较快,并且该程序做蛋白质序列的进化树效果比较好。
而PAML则并不适合构建进化树。
ML的模型选择是看构出的树的likelihood值,从参数少,简单的模型试起,到likelihood值最大为止。
ML也可以使用PAUP或者PHYLIP来构建。
这里作者推荐的工具是BioEdit。
BioEdit集成了一些PHYLIP的程序,用来构建进化树。
Tree-puzzle是另外一个不错的选择,不过该程序是命令行格式的,需要学习DOS命令。
PHYML的不足之处是没有win32的版本,只有适用于64位的版本,因此不推荐使用。
值得注意的是,构建ML树,不需要事先的多序列比对,而直接使用FASTA格式的序列即可。
贝叶斯的算法以MrBayes为代表,不过速度较慢。
一般的进化树分析中较少应用。
由于该方法需要很多背景的知识,这里不作介绍。
表1构建分子进化树相关的软件
软件网址说明
ClustalXhttp:
//bips.u-strasbg.fr/fr/Documentation/ClustalX/图形化的多序列比对工具
ClustalWhttp:
//www.cf.ac.uk/biosi/research/biosoft/Downloads/clustalw.html命令行格式的多序列比对工具
GeneDochttp:
//www.psc.edu/biomed/genedoc/多序列比对结果的美化工具
BioEdithttp:
//www.mbio.ncsu.edu/BioEdit/bioedit.html序列分析的综合工具
MEGA图形化、集成的进化分析工具,不包括ML
PAUPhttp:
//paup.csit.fsu.edu/商业软件,集成的进化分析工具
PHYLIPhttp:
//evolution.genetics.washington.edu/phylip.html免费的、集成的进化分析工具
PHYMLhttp:
//atgc.lirmm.fr/phyml/最快的ML建树工具
PAMLhttp:
//abacus.gene.ucl.ac.uk/software/paml.htmlML建树工具
Tree-puzzlehttp:
//www.tree-puzzle.de/较快的ML建树工具
MrBayeshttp:
//mrbayes.csit.fsu.edu/基于贝叶斯方法的建树工具
MAC5基于贝叶斯方法的建树工具
TreeViewhttp:
//taxonomy.zoology.gla.ac.uk/rod/treeview.html进化树显示工具
需要注意的几个问题是,其一,如果对核酸序列进行分析,并且是CDS编码区的核酸序列,一般需要将核酸序列分别先翻译成氨基酸序列,进行比对,然后再对应到核酸序列上。
这一流程可以通过MEGA3.0以后的版本实现。
MEGA3现在允许两条核苷酸,先翻成蛋白序列比对之后再倒回去,做后续计算。
其二,无论是核酸序列还是蛋白序列,一般应当先做成FASTA格式。
FASTA格式的序列,第一行由符号“>
”开头,后面跟着序列的名称,可以自定义,例如user1,protein1等等。
将所有的FASTA格式的序列存放在同一个文件中。
文件的编辑可用Windows自带的记事本工具,或者EditPlus(google搜索可得)来操作。
文件格式如图1所示:
图1FASTA格式的序列
另外,构建NJ或者MP树需要先将序列做多序列比对的处理。
作者推荐使用ClustalX进行多序列比对的分析。
多序列比对的结果有时需要后续处理并应用于文章中,这里作者推荐使用GeneDoc工具。
而构建ML树则不需要预先的多序列比对。
因此,作者推荐的软件组合为:
MEGA3.1+ClustalX+GeneDoc+BioEdit。
四、数据分析及结果推断
一般碰到的几类问题是,
(1)推断基因/蛋白的功能;
(2)基因/蛋白家族分类;
(3)计算基因分化的年代。
关于这方面的文献非常多,这里作者仅做简要的介绍。
推断基因/蛋白的功能,一般先用BLAST工具搜索同一物种中与不同物种的同源序列,这包括直向同源物(ortholog)和旁系同源物(paralog)。
如何界定这两种同源物,网上有很多详细的介绍,这里不作讨论。
然后得到这些同源物的序列,做成FASTA格式的文件。
一般通过NJ构建进化树,并且进行Bootstrap分析所得到的结果已足够。
如果序列近缘,可以再使用MP构建进化树,进行比较。
如果序列较远源,则可以做ML树比较。
使用两种方法得到的树,如果差别不大,并且Bootstrap总体较高,则得到的进化树较为可靠。
基因/蛋白家族分类。
这方面可以细分为两个问题。
一是对一个大的家族进行分类,另一个就是将特定的一个或多个基因/蛋白定位到已知的大的家族上,看看属于哪个亚家族。
例如,对驱动蛋白(kinesin)超家族进行分类,属于第一个问题。
而假如得到一个新的驱动蛋白的序列,想分析该序列究竟属于驱动蛋白超家族的14个亚家族中的哪一个,则属于后一个问题。
这里,一般不推荐使用MP的方法。
大多数的基因/蛋白家族起源较早,序列分化程度较大,相互之间较为远源。
这里一般使用NJ、ME或者ML的方法。
计算基因分化的年代。
这个一般需要知道物种的核苷酸替代率。
常见物种的核苷酸替代率需要查找相关的文献。
这里不作过多的介绍。
一般对于这样的问题,序列多数是近缘的,选择NJ或者MP即可。
如果使用MEGA进行分析,选项中有一项是“Gaps/MissingData”,一般选择“PairwiseDeletion”。
其他多数的选项保持缺省的参数。
五、总结
在实用中,只要方法、模型合理,建出的树都有意义,可以任意选择自己认为好一个。
最重要的问题是:
你需要解决什么样的问题?
如果分析的结果能够解决你现有的问题,那么,这样的分析足够了。
因此,在做进化分析前,可能需要很好的考虑一下自己的问题所在,这样所作的分析才有针对性。
六、致谢
本文由mediocrebeing在2005年9月8日所发起的讨论《关于建树的经验》扩充、修改而来。
文章的作者按原贴ID出现先后排名,由lylover执笔。
作者同时感谢所有参与讨论的战友。
作者lylover感谢中国科大细胞动力学实验室的金长江博士所给的一些有益的建议。


- 配套讲稿:
如PPT文件的首页显示word图标,表示该PPT已包含配套word讲稿。双击word图标可打开word文档。
- 特殊限制:
部分文档作品中含有的国旗、国徽等图片,仅作为作品整体效果示例展示,禁止商用。设计者仅对作品中独创性部分享有著作权。
- 关 键 词:
- MEGA 说明书
 冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 如何打造酒店企业文化2刘田江doc.docx
如何打造酒店企业文化2刘田江doc.docx
-
律师提供著作权法律服务业务操作指引.docx
-
18秋福建师范大学《经济法》在线作业一.docx
-
施工现场危险源.docx
-
山东省潍坊市昌乐县学年七年级地理下学期期中学业质量评估试题.docx
-
新视野大学英语视听说教程第二版第一册完整答案.docx
-
精校版重庆市 初中毕业水平暨高中招生考试中考英语试题AB卷Word版含答案解析.docx
-
新视野大学英语视听说教程第二版第一册完整答案.docx
-
江苏省刘国钧中学1112学年高二语文上学期期末考前辅导试题卷苏教版会员独享.docx
-
山东省潍坊市昌乐县学年七年级地理下学期期中学业质量评估试题.docx
-
西安交通大学18年课程考试《管理会计》作业考核试题.docx
-
施工安全保证体系.docx
-
南开17秋学期《科学启蒙尔雅》在线作业2.docx
-
秋福师《大学英语1》在线作业二.docx
-
231695 北交《运输物流管理》在线作业2 15秋答案.docx
-
梁原学区安全管理工作实施方案.docx
-
环保管理台帐明细.docx
-
我国三大翻译证书考试概览.docx
-
东大17秋学期《大学英语二》在线作业31.docx
-
静态分析指标.docx
-
山东金瀚控股金瀚置业绩效考核指标库.docx
-
B0301A国际贸易.docx
-
人教版八年级数学上册同步练习试题及答案第11章《三角形》 同步练习及答案111.docx
-
秋福师《概率论》在线作业二.docx
-
17秋福师《高级英语阅读二》在线作业一.docx
-
西南大学17秋0764《工程建设监理》在线作业参考资料.docx
-
生活宝典之社会大转盘一.docx
-
专卖店管理.docx
-
100个CFO的八年之资金管理篇.docx
-
东北师范古代汉语三16秋在线作业2.docx
-
专业技术人员公共危机管理考试.docx
-
东大17秋学期《大学英语二》在线作业31.docx
-
寒假大学生服装店社会实践报告Word文件下载.docx
-
反渗透水处理设备制作原理以及工作原理0Word文档格式.docx
-
小学演讲与主持的教案Word文档格式.docx
-
财务报告分析Word格式.docx
-
高中化学复习知识点过氧化钠与水的反应Word格式文档下载.docx
-
部编版版高中地理第一章区域地理环境与人类活动第3节区域发展差异学案湘教版必修2Word文件下载.docx
-
四川某污水处理厂及配套管网工程施工组织设计方案Word文件下载.docx
-
if虚拟语气之欧阳文创编Word格式.docx
-
四字成语寓言故事大全经典四字成语故事Word格式文档下载.docx
-
出差管理制度及标准Word格式文档下载.docx
-
软件开发文档说明完整流程Word文档格式.docx
-
新测量方案Word文档格式.docx
-
并联电路中的电阻关系Word格式.docx
-
下半年疫情过后幼儿园个人计划幼儿园周计划Word文件下载.docx
-
选修31第2章直流电路 同步练习题学生打印版Word格式文档下载.docx
-
高三文科基础测试Word下载.docx
-
推荐精品互联网医疗商业模式分析报告Word文档下载推荐.docx
-
队伍队名大全Word文档格式.docx
-
人教版七年级英语上册StarterUnits13测试题及答案Word格式.docx
