 STATA入门5函数与运算符Word文档下载推荐.docx
STATA入门5函数与运算符Word文档下载推荐.docx
- 文档编号:17278404
- 上传时间:2022-11-30
- 格式:DOCX
- 页数:13
- 大小:22.51KB
STATA入门5函数与运算符Word文档下载推荐.docx
《STATA入门5函数与运算符Word文档下载推荐.docx》由会员分享,可在线阅读,更多相关《STATA入门5函数与运算符Word文档下载推荐.docx(13页珍藏版)》请在冰豆网上搜索。
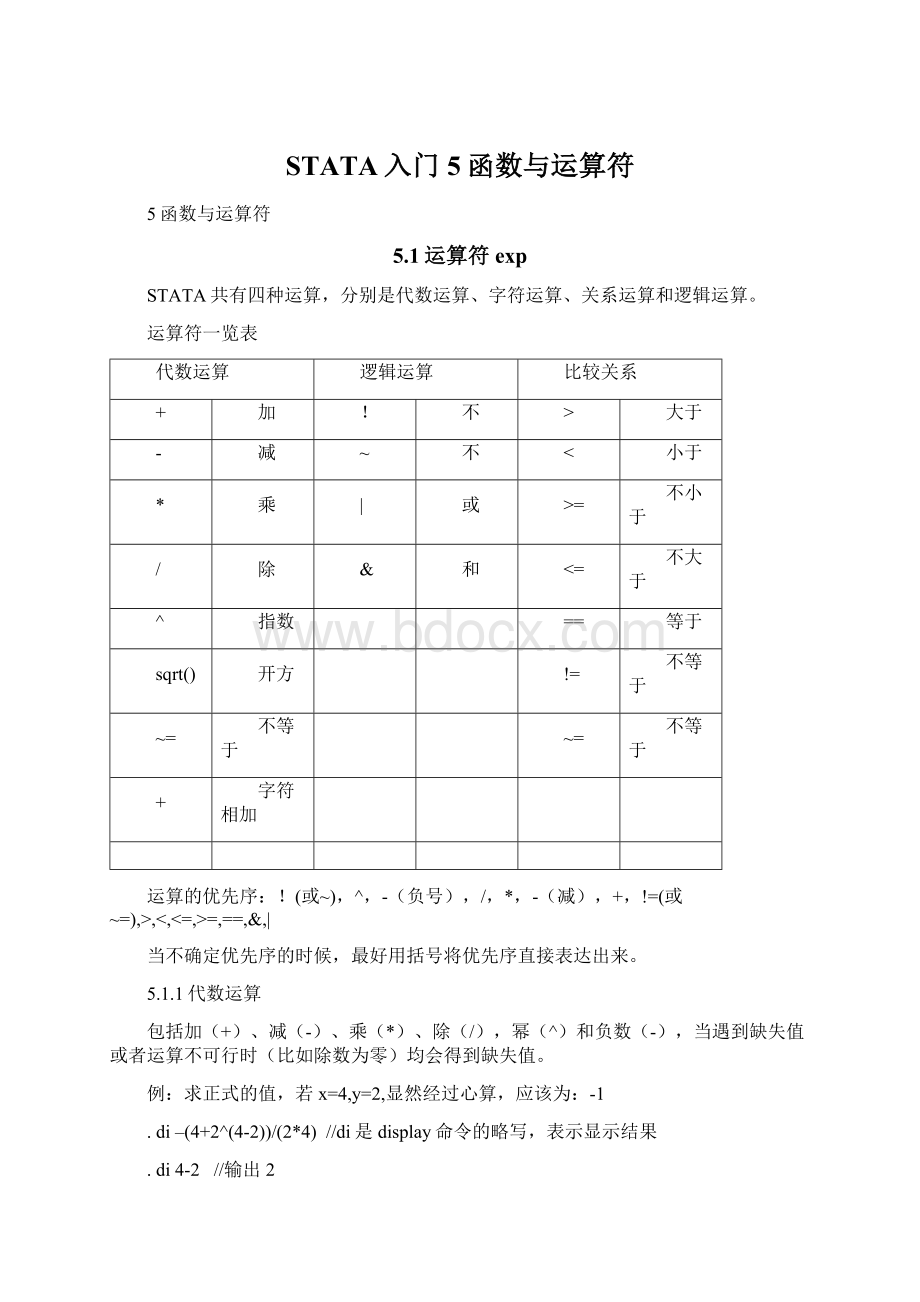
,<
=,>
=,==,&
|
当不确定优先序的时候,最好用括号将优先序直接表达出来。
5.1.1代数运算
包括加(+)、减(-)、乘(*)、除(/),幂(^)和负数(-),当遇到缺失值或者运算不可行时(比如除数为零)均会得到缺失值。
例:
求正式的值,若x=4,y=2,显然经过心算,应该为:
-1
.di–(4+2^(4-2))/(2*4)//di是display命令的略写,表示显示结果
.di4-2//输出2
.di3*5//输出15
.di8/2//8除以2,输出4
.di2^3//2的立方,输出8
.di–(2+3^(2-3))/sqrt(2*3)//括号运算优先,想一想,结果应为多少?
实际上,更多的情形是两个或多个变量的直接运算。
比如,将进口车的价格都增加100元(可能是关税),而国产车不变。
.sysuseauto,clear
.gennprice=price+foreign*100
.listnpricepriceforeign
5.1.2字符运算
加(+)号同样可用于字符运算,当加号出现在两个字符之间时,两个字符将被连成一个字符。
比如把”我爱”“STATA”合并在一起,命令为:
.scalara=”我爱”+“STATA”//要特别注意,引号必须是半角和英文模式
.scalarlista//scalar命令将两个字符运算后的结果赋于a,然后显示a
.scalara=2+“3”//注意到:
字符与数值不能直接相加,显示类型不匹配
typemismatch
r(109);
5.1.3关系运算
关系运算包括大于、小于、等于;
不等于、不小于、不大于等多种比较关系。
特别要注意到STATA中的等于符号为“==”,是两个等号连写在一起,不同于赋值时用的单个等号“=”。
.di3<
5//输出结果为1,意味着3小于5为真
.di3>
5//输出的结果为0,意味着3大于5为假。
当数据中含有缺失值的时候需要特别小心,因为系统缺失值大于任何一个数据,利用这一点,我们可以使用条件语句排除缺失值。
任务:
将年龄分组为65岁以下和65岁及以上两组,缺失值显然不能包括在任何一组中。
age
38
.
65
42
18
80
.clear
.edit
将上述数据复制到STATA中,然后退出数据编辑器。
.genagegrp1=(age>
=65)
生成的数据中,将缺失值视为65岁以上分在了高龄组,这是错误的
.genagegrp2=(age>
=65)ifage<
生成的数据中,将缺失值排除在外,正确!
这一命令常被用于生成虚拟变量。
.genagegrp3=(age==65)ifage<
.//仅判断是否恰好为65岁
.list//比较agegrp1、agegrp2和agegrp3的差异,体会ifage<
.的作用。
Agegrp1
Agegrp2
Agegrp3
1
5.1.4逻辑运算
逻辑运算包括非(!
),和(&
)、或(|)三种,主要用于条件语句中。
列示出价格大于10000元的任何车,或者小于4000元的国产车。
.listpriceforeignifprice>
10000|price<
4000&
forei==0
在STATA中,和(&
)优先于或(|),因此上述命令与下面的命令等价:
10000|(price<
forei==0)
试一试下面的命令,这里列示的是国产车中价格高于10000元或者低于4000元的车。
.listpriceforeignif(price>
4000)&
5.2函数概览function
函数只不过是一些编号的小程序,它会按一定的规则进行处理,之后报告结果。
实际上,谁也记不住这么多函数,因此,首先要学会查找函数的帮助,当记不住的时候,随时去查寻帮助。
记住下面的命令才是最关键的。
.helpfunction
TypeoffunctionSeehelp
--------------------------------------+-------------------------
Mathematicalfunctionsmathfunctions
Probabilitydistributionsand
densityfunctionsdensityfunctions
Random-numberfunctionsrandom-numberfunctions
Stringfunctionsstringfunctions
Programmingfunctionsprogrammingfunctions
Datefunctionsdatefunctions
Time-seriesfunctionstime-seriesfunctions
Matrixfunctionsmatrixfunctions
弹出来的对话框告诉我们,STATA包括八类函数,分别是数学函数,分布函数,随机数函数,字符函数,程序函数,日期函数,时间序列函数和矩阵函数。
本章主要介绍数学函数和字符函数,其他函数将在后面相应的章节介绍。
常用函数一览表
函数
含义
举例
数值型函数
abs(x)
绝对值
abs(-9)=9
comb(n,k)
从n中取k个的组合
comb(10,2)=45
exp(x)
exp(0)=1
fill()
自动填充数据
int(x)
取整
int(5.6)=5,int(-5.2)=-5.
ln(x)
对数
ln
(1)=0
log10(x)
以10为底的对数
log10(1000)=3
mod(x,y)
=x-y*int(x/y)
mod(9,2)=1
round(x)
四舍五入
round(5.6)=6
sqrt(x)
sqrt(16)=4
sum(x)
求和
随机函数
uniform()
均匀分布随机数
第10讲将介绍
invnormal(uniform())
标准正态分布随机数
第11讲将介绍
字符函数
real(s)
字符型转化为数值型
string(n)
数值型转化为字符型
substr(s,n1,n2)
从S的第n1个字符开始,截取n2个字符
Substr(“this”,2,2)=is
word(s,n)
返回s的第n个字符
Work(“this”,3)=i
系统变量
_n
当前观察值的序号
_N
共有多少观察值
_pi
π
5.3数学函数mathfunctions
5.3.1三角函数,指数和对数函数
数学函数可以直接对数据进行运算,也可以对变量进行运算。
.disqrt(4)//开方,输出2
.disqrt(6+3)//先相加,再开方,输出3
.diabs(-100)//求绝对值,输出100
.diexp
(1)//表示e1,输出2.7182818
.diln(exp
(2))//先求e2,再取对数,得到2
.di_pi//_pi为圆周率,得到3.1415927
.dicos(_pi)//_pi的余弦值,得到-1
对变量的操作:
clear
setobs5
genx=_n//生成新变量x,取值为1,2,3,4,5
geny1=exp(x)//取指数
geny2=ln(x)//取对数
geny3=sin(exp(x))+cos(ln(x))//取对数
l
5.3.2取整和四舍五入
.diint(3.49)//int()取整,不论后面的小数是什么,只取小数点前的数值
.diint(3.51)//输出3
.diint(-3.49)//输出-3
.diint(-3.51)//输出-3
.diround(3.49)//round()取整,四舍五入,结果为3
.diround(3.51)//四舍五入,结果为4
.diround(-3.49)//四舍五入,结果为-3
.diround(-3.51)//四舍五入到个位数,结果为-4
.diround(3.345,.1)//四舍五入到十分位,结果为3.3
.diround(3.351,.1)//四舍五入到十分位,结果为3.4
.diround(3.345,.01)//四舍五入到百分位,结果为3.35
.diround(3.351,.01)//四舍五入到百分位,结果为3.35
.diround(335.1,10)//四舍五入到十位,结果为330
对变量的操作
.gennprice=price/10000//将价格变到以万为单位
.gennprice2=round(nprice,0.01)//四舍五入到百分位
.listnprice*//比较结果
5.3.3求和及求均值gen和egen
clear
setobs5
genx=_n//生成新变量x,x的取值从1到5
geny=sum(x)//求列累积和
egenz=sum(x)//求列总和
egenr=rsum(xyz)//求x+y+z总和
egenhsum=rowtotal(xyz)//求hsum=a+b+c
egenhavg=rowmean(xyz)//求havg=(a+b+c)/3
egenhsd=rowsd(xyz)//求a、b和c的方差
egenrmin=rowmin(xyz)//求xyz)三个变量的最小值
egenrmax=rowmax(xyz)//求xyz)三个变量的最大值
list//注意比较y和z的不同。
egenavgx=mean(x)//求列均值
egenmedx=median(x)//求列中值
egenstdx=std(x)//求列标准差
replacey=3in3
egenbytedxy=diff(xy)//当x与y相等时,differ取0,若不相等为1
更多关于egen命令的用法将参考帮助:
helpegen
5.3.4其他
sysuseauto,clear
egenrmpg=rank(mpg)//求mpg的次序
sortrmpg
listmpgrank//列示结果
egenhighrep78=anyvalue(rep78),v(3/5)/*若rep78不为3、4或5,
则为缺失值*/
listrep78highrep78
inputab
10
00
11
01
1.
.0
end
egenab=group(ab)
egenab2=group(ab),missing
ababab2
------------------
1.1033
2.0011
3.1144
4.0122
5.0011
6.1..5
7..0.6
5.4字符函数stringfunctions
将美国汽车数据中汽车商标变量值简化为取前三个字母,得到一个新的变量make3
sysuseauto,clear
genstr3make3=substr(make,1,3)
listmake*
下表的数据是一个多选题,请把这道多选题转化为四个单选题
a
2
2、1、3
1、2、4
4、2、1
1、2
genna1=strpos(a,"
1"
)!
=0//strops(s1,s2)返回字符s2在s1中的位置
genna2=strpos(a,"
2"
=0
genna3=strpos(a,"
3"
genna4=strpos(a,"
4"
list
ana1na2na3na4
1.20100
2.20100
3.1、2、31110
4.1、2、41101
5.1、2、41101
6.1、21100
7.20100
8.1、21100
webusegenxmpl2,clear
genname2=word(name,2)//新变量name2,取值为name的第二个字母
listn*
5.5分类操作by
edit
*将下表复制粘贴到STATA数据编辑器中,注意粘贴时把光标停在第一格。
x
y
1.1
1.2
1.3
2.1
2.2
genn=_n//生成一个新变量n=1,2,3,4,5
genN=_N//生成一个新变量N=5,5,5,5,5
genz=y[1]//生成一个新变量z=y的第一个观察值
l
xynNz
-----------------------
1.11.1151.1
2.11.2251.1
3.11.3351.1
4.22.1451.1
5.22.2551.1
byx,sort:
genn1=_n//注意到n1与n的不同,n1按x分类进行操作
genN1=_N
genz1=y[1]
list
xynNzn1N1z1
1.11.1151.1131.1
2.11.2251.1231.1
3.11.3351.1331.1
4.22.1451.1122.1
5.22.2551.1222.1
下列数据为家庭成员数据family.dta,其中hhid为家庭编码,age为家庭成员的年龄。
将下表数据复制到STATA,然后另存为family.dta
hhid
86
36
57
28
5
40
要求:
(1)生成一个新变量hhsize,该变量表示共有多少个家庭成员。
(2)给每个家庭成员一个编码id。
如第一个家庭的第一个成员编码为11;
(3)按家庭生成一个全家成员平均年龄值mage。
(4)对每个家庭,分别按年龄大小排序,然后生成一个家庭成员代码,即家庭内年龄最小的成员代码为1,年龄最大的家庭成员,代码为nid。
最后需要生成的数据集如下:
hhsize
id
mage
nid
15
49.8
13
12
3
14
4
11
22
29
23
21
请自己先思考,再参考如下操作:
将上表数据复制粘贴到STATA数据编辑器,然后执行下面的命令
usefamily,clear
byhhid,sort:
genhhsize=_N//得到家庭规模hhsize
genid=_n+hhid*10//为家庭成员编码
byhhid,sort:
egenmage=mean(age)//求平均年龄
sorthhidage//按户排序,在每个户内按年龄大小排序
byhhid:
gennid=_n//在户内按年龄大小为家庭成员编码
+---------------------------------------+
|hhidagehhsizeidmagenid|
|---------------------------------------|
1.|12851149.81|
2.|13651249.82|
3.|14251349.83|
4.|15751449.84|
5.|18651549.85|
6.|25321291|
7.|240322292|
8.|242323293|
另一个例子:
bysorthhid(age):
gennid1=_n//括号中的变量age只排序,不参于分组。
bysorthhidage:
gennid2=_n//hhid和age都既用来参与排序也分组
list//比较上面两个命令得到的不同结果
hhidagenid1nid2
--------------------------
1.12811
2.13621
3.14231
4.15741
5.18651
6.2511
7.24021
8.24231
webusestan2,clear
expand2iftransplant//将transplant==1的观察值再复制一个
sortid
byid:
generatebyteposttran=(_n==2)/*生成一个新变量posttran,使得
对同一个人,第一个观察值取0,第
二个观察值取1*/
generatet1=stimeif_n==_N/*生成新变量t1,使得在同一个id下,
对第二期取值为stime,否则为“.”


- 配套讲稿:
如PPT文件的首页显示word图标,表示该PPT已包含配套word讲稿。双击word图标可打开word文档。
- 特殊限制:
部分文档作品中含有的国旗、国徽等图片,仅作为作品整体效果示例展示,禁止商用。设计者仅对作品中独创性部分享有著作权。
- 关 键 词:
- STATA 入门 函数 运算
 冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 广东省普通高中学业水平考试数学科考试大纲Word文档下载推荐.docx
广东省普通高中学业水平考试数学科考试大纲Word文档下载推荐.docx
-
计算题测试文档格式.docx
-
会计年终总结范文精选10篇Word文件下载.docx
-
基坑支护及降排水方案Word格式文档下载.docx
-
古代诗歌鉴赏一剪梅学案Word文档格式.docx
-
国标舞考级Word文件下载.docx
-
机电工程质量验收规范是什么Word文档下载推荐.docx
-
技术员工作自我评价文档格式.docx
-
交警支队车棚改造工程施工合同文档格式.docx
-
护士变更注册申请审核表与示范文本Word文档下载推荐.docx
-
最新学校新冠肺炎疫情防控应急预案Word文件下载.docx
-
GB50204钢筋规范之欧阳总创编Word格式文档下载.docx
-
《半期整改措施》Word格式.docx
-
诊断 症状学腰背痛关节痛汇总.docx
-
英美文学欣赏The Analysis of Shelleys Ode to the West Wind.docx
-
增值税营改增所得税消费税车购税测试题.docx
-
整理二级建造师管理真题.docx
-
英语三级重点高频词汇导入背单词APP使用.docx
-
浙教版学年九年级数学上册第2章测试题及答案.docx
-
证件照教学设计方案.docx
-
优品课件之《从锁国走向开国的日本》教案.docx
-
整理北京交通大学万用表组装实验报告.docx
-
质量管理计划.docx
-
有机化学鉴别.docx
-
整理照明灯饰灯具行业分类英语词汇.docx
-
濉溪县城市总体规划公示.docx
-
智能化工程质量验收记录表.docx
-
学生会纪检部工作总结.docx
-
幼儿园保教主任发言稿.docx
-
跆拳道协会工作总结.docx
-
中国茶叶店连锁市场竞争分析与竞争战略研究报告.docx
-
学宪法讲宪法主题演讲稿800字精选5篇弘扬宪法精神演讲稿5篇.docx
-
《芈月传》穿帮与虚构有多少.docx
-
甘肃省西北师大附中届高三月考数学理试题扫描版含答案.docx
-
分析化学教学中的应用研究大学论文.docx
-
5年级信息技术教案版教案第12课.docx
-
风力发电机组液压冷却润滑防腐产品生产项目可行性研究报告.docx
-
服装制作工艺基础知识.docx
-
福建省届高三语文质量检查测试试题.docx
-
《中国古代诗歌散文欣赏》散文之部单元教学设计及.docx
-
0吨农产品贮藏保鲜扩建项目可行性研究报告.docx
-
妇女节文艺晚会活动方案.docx
-
北师大版小学数学四年级上册全册教案修改版.docx
-
2级vb.docx
-
本科生工作管理办法 西北政法大学党政办公室.docx
-
甘肃省会宁县第四中学学年高二语文上学期期中试题.docx
-
编辑学前教育50篇幼儿故事或片段题库新颖完整版doc.docx
-
宾阳职校实验学校项目研究总结报告.docx
-
不严不实问题具体表现原因及整改措施 精品.docx
-
部编版小学一年级语文上册第七单元教案分析1.docx
-
材料范文之安全生产会议汇报材料.docx
