 快速排序Word文件下载.docx
快速排序Word文件下载.docx
- 文档编号:16561242
- 上传时间:2022-11-24
- 格式:DOCX
- 页数:9
- 大小:68.59KB
快速排序Word文件下载.docx
《快速排序Word文件下载.docx》由会员分享,可在线阅读,更多相关《快速排序Word文件下载.docx(9页珍藏版)》请在冰豆网上搜索。
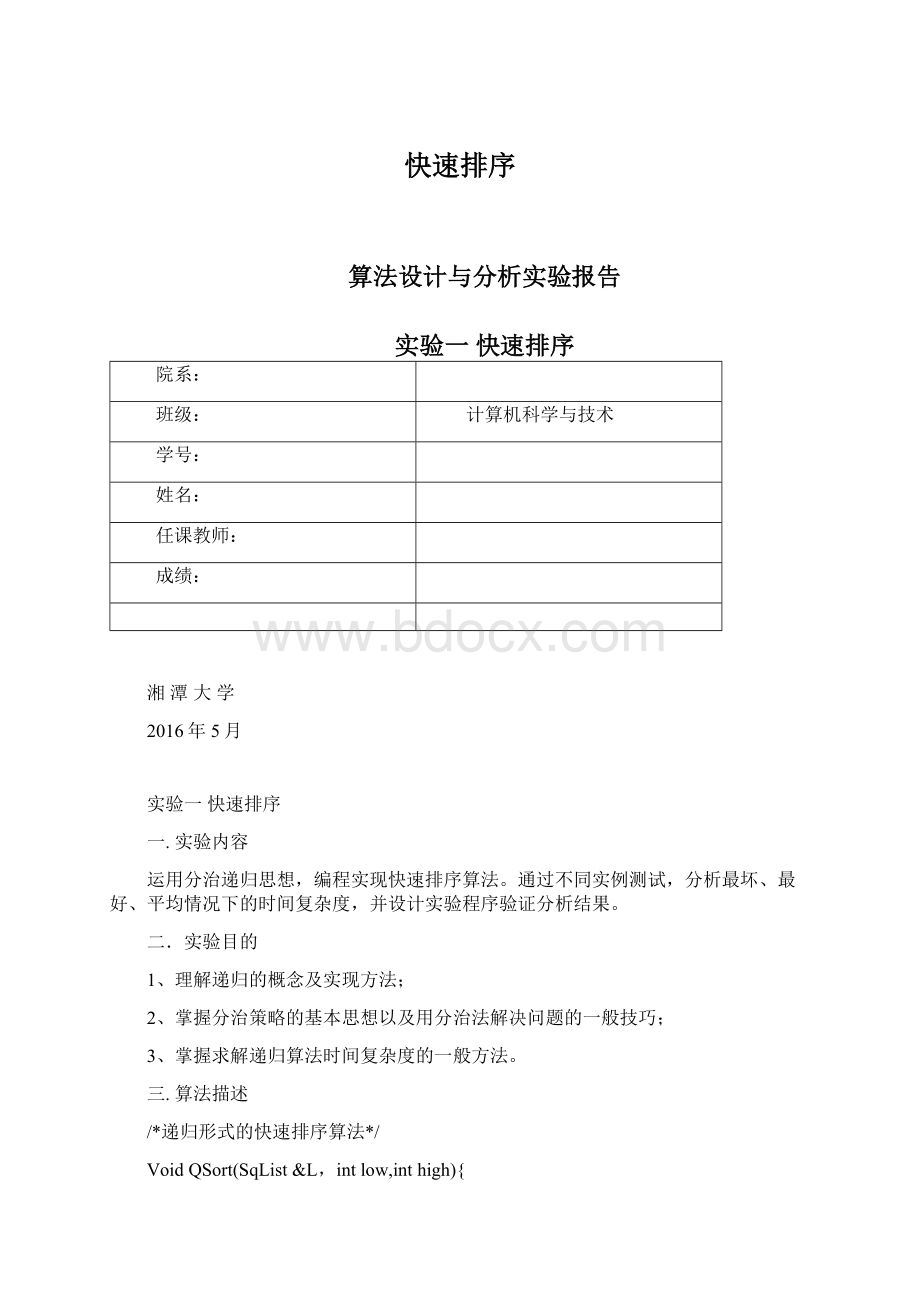
/*递归形式的快速排序算法*/
VoidQSort(SqList&
L,intlow,inthigh){
//对顺序表L中的子序列L.r[low..high]作快速排序
If(low<
high){
pivotloc=Partition(L,low,high);
//将L.r[low..high]一分为二
QSort(L,low,pivotloc-1);
//对低子表递归排序
QSort(L,pivotloc+1,high);
//对高子表递归排序
}
}//QSort
VoidQuickSort(SqList&
L){
//对顺序表L作快速排序
QSort(L,1,L.length);
}//QuickSort
四.算法实现
1.数据结构及函数说明
基本思想:
通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
intPartition(SqList&
L,intlow,inthigh){
//交换顺序表L中子表r[low..high]的记录,枢轴记录到位,并返回其所
//在位置,此时在它之前的记录均不大于它。
L.r[0]=L.r[low];
//用子表的第一个记录作枢轴记录
pivotkey=L.r[low].key;
枢轴记录关键字
while(low<
high){//从表的两端交替的向中间扫描
high&
&
L.r[high].key>
=pivotkey)--high;
L.r[low]=L.r[high];
//将比枢轴记录小的记录移到低端
L.r[high].key<
=pivotkey)++low;
L.r[high]=L.r[low];
//将比枢轴记录大的记录移到高端
L.r[low]=L.r[0];
//枢轴记录到位
returnlow;
//返回枢轴位置
函数说明:
intchoose_pivot(inti,intj)
{
return((i+j)/2);
//取中轴数
2.源程序代码
#include<
stdio.h>
stdlib.h>
time.h>
voidquicksort(intlist[],intm,intn)
intkey,i,j,k;
if(m<
n)
{
k=choose_pivot(m,n);
swap(&
list[m],&
list[k]);
key=list[m];
i=m+1;
j=n;
while(i<
=j)
while((i<
=n)&
(list[i]<
=key))
i++;
while((j>
=m)&
(list[j]>
key))
j--;
if(i<
j)
list[i],&
list[j]);
}
quicksort(list,m,j-1);
quicksort(list,j+1,n);
voidprintlist(intlist[],intn)
inti;
for(i=0;
i<
n;
i++)
printf("
%d\t"
list[i]);
voidmain()
clock_tstart,finish;
start=clock();
floatduration;
intn;
******************************************************************\n"
);
数组长度:
"
scanf("
%d"
&
n);
constintMAX_ELEMENTS=n;
intlist[MAX_ELEMENTS];
inti=0;
srand((unsigned)time(NULL));
for(i=0;
i<
MAX_ELEMENTS;
i++){
list[i]=rand()%100;
排序之前的序列:
\n"
printlist(list,MAX_ELEMENTS);
quicksort(list,0,MAX_ELEMENTS-1);
\n排序之后的序列:
finish=clock();
duration=(float)(finish-start);
\n所需时间:
%fms\n"
duration);
printf("
returnmain();
voidswap(int*x,int*y)
inttemp;
temp=*x;
*x=*y;
*y=temp;
五.程序运行结果
随机产生十组长度为10的数组,随机产生的数组和排序后以及排序所需时间的结果如截图所示:
六.实验结果分析
最好情况:
每次都能均匀的划分序列,时间复杂度为O(nlogn)和平均情款时间复杂度一样;
最坏情况:
枢轴元为最大或者最小数字,那么所有数字会划分到一个序列中,时间复杂度为O(n^2);
分析:
(由于是随机产生的数组不一定能产生最好或最坏情款就随便举例一组数据分析)
最好情款:
例如:
4,1,3,2,6,5,7,每次使用序列的第一个元素做枢轴.比较总次数为10次,交换3次,具体如下:
第一次枢轴为4,序列划分为{2,1,3},4,{6,5,7}
比较6次(4与每个元素比较一次),交换1次(4与2交换)
第二次的两个序列枢轴分别为2和6,此时划分序列得{1},2,{3},4,{5},6,{7}
比较4次(两个序列各比较两次),交换两次(1和2,6和5)
第三次由于各个序列的元素都为1,因此排序完成得1,2,3,4,5,6,7
最坏情款:
4,1,3,2,6,5,7,每次使用序列的第一个元素做枢轴,具体如下:
(每次选择最大的数为枢轴)
第一次枢轴为7,序列划分为{4,1,3,2,6,5},7
比较6次(7与每个元素比较一次),不交换
第二次的序列枢轴为6,此时划分序列得{4,1,3,2,5},6,{7}
比较5次(6与每个元素比较一次),不交换
第三次序列枢轴为5,此时划分序列得{4,1,3,2},5,{6,7}
比较4次(5与每个元素比较一次),不交换
第四次序列枢轴为4,此时划分序列得{1,3,2},4,{5,6,7}
比较3次(4与每个元素比较一次),不交换
第五次序列枢轴为3,此时划分序列得{1,2},3,{4,5,6,7}
比较2次(3与每个元素比较一次),不交换
第六次序列枢轴为2,此时划分序列得{1},2,{3,4,5,6,7}
比较1次(3与每个元素比较一次),不交换
最后排序完成得{1,2,3,4,5,6,7}
七.结论
影响算法时间复杂度的关键因素是每次枢轴元素的选择,选择基准数据时我们不再总是选择第一个划分的第一个元素,而是随机的从划分中选择一个。
假设我们排序一个数列,然后把它分为四个部份。
在中央的两个部份将会包含最好的基准值;
他们的每一个至少都会比25%的元素大,且至少比25%的元素小。
如果我们可以一致地从这两个中央的部份选出一个元素,在到达大小为1的数列前,我们可能最多仅需要把数列分区2log2
n次,产生一个
O(nlogn)算法。
不幸地,乱数选择只有一半的时间会从中间的部份选择。
出人意外的事实是这样就已经足够好了。
想像你正在翻转一枚硬币,一直翻转一直到有
k
次人头那面出现。
尽管这需要很长的时间,平均来说只需要
2k
次翻动。
且在
100k
次翻动中得不到
次人头那面的机会,是像天文数字一样的非常小。
借由同样的论证,快速排序的递归平均只要2(2log2
n)的调用深度就会终止。
但是如果它的平均调用深度是O(log
n)且每一阶的调用树状过程最多有
n
个元素,则全部完成的工作量平均上是乘积,也就是O(n
log
n)。
这样就不会出现上述中最坏的情况。
为了更加减少上面的概率一般可以随机三个数选择中间一个,这样就会大大减少最坏情况的发生。


- 配套讲稿:
如PPT文件的首页显示word图标,表示该PPT已包含配套word讲稿。双击word图标可打开word文档。
- 特殊限制:
部分文档作品中含有的国旗、国徽等图片,仅作为作品整体效果示例展示,禁止商用。设计者仅对作品中独创性部分享有著作权。
- 关 键 词:
- 快速 排序
 冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 广东省普通高中学业水平考试数学科考试大纲Word文档下载推荐.docx
广东省普通高中学业水平考试数学科考试大纲Word文档下载推荐.docx
-
计算题测试文档格式.docx
-
会计年终总结范文精选10篇Word文件下载.docx
-
基坑支护及降排水方案Word格式文档下载.docx
-
古代诗歌鉴赏一剪梅学案Word文档格式.docx
-
国标舞考级Word文件下载.docx
-
机电工程质量验收规范是什么Word文档下载推荐.docx
-
技术员工作自我评价文档格式.docx
-
交警支队车棚改造工程施工合同文档格式.docx
-
护士变更注册申请审核表与示范文本Word文档下载推荐.docx
-
最新学校新冠肺炎疫情防控应急预案Word文件下载.docx
-
GB50204钢筋规范之欧阳总创编Word格式文档下载.docx
-
《半期整改措施》Word格式.docx
-
诊断 症状学腰背痛关节痛汇总.docx
-
英美文学欣赏The Analysis of Shelleys Ode to the West Wind.docx
-
增值税营改增所得税消费税车购税测试题.docx
-
整理二级建造师管理真题.docx
-
英语三级重点高频词汇导入背单词APP使用.docx
-
浙教版学年九年级数学上册第2章测试题及答案.docx
-
证件照教学设计方案.docx
-
优品课件之《从锁国走向开国的日本》教案.docx
-
整理北京交通大学万用表组装实验报告.docx
-
质量管理计划.docx
-
有机化学鉴别.docx
-
整理照明灯饰灯具行业分类英语词汇.docx
-
濉溪县城市总体规划公示.docx
-
智能化工程质量验收记录表.docx
-
学生会纪检部工作总结.docx
-
幼儿园保教主任发言稿.docx
-
跆拳道协会工作总结.docx
-
中国茶叶店连锁市场竞争分析与竞争战略研究报告.docx
-
学宪法讲宪法主题演讲稿800字精选5篇弘扬宪法精神演讲稿5篇.docx
-
生物八年级上册中考试题汇编.docx
-
人教版八年级数学上册讲义12三角形全等之动点问题.docx
-
生鲜农产品网络配送服务企业创业项目商业计划书.docx
-
清明节的作文1200字7篇.docx
-
人教版高中语文选修一新课标同步导学 第二单元单元测试新课标版中国古代诗歌散文欣赏.docx
-
实习律师的月度个人总结.docx
-
人力资源管理控制程序教材.docx
-
秋综合练习.docx
-
人生态度演讲稿10篇.docx
-
三八妇女节活动策划案模板精选5篇.docx
-
三年级语文下册复习资料.docx
-
全国计算机等级考试一级试题5.docx
-
扫描仪驱动安装步骤.docx
-
林业工程施工组织方案.docx
-
庆祝五四青年节活动策划方案5篇.docx
-
山东省东营市中考生物试题含答案.docx
-
逻辑和批判性思维考试详解超星尔雅的.docx
-
全国高考文综试题及答案新课标2.docx
-
山东省潍坊市高三英语下学期三轮复习第四次单元测试三轮拉练四试题.docx
