 时间序列计量经济学模型案例Word格式.docx
时间序列计量经济学模型案例Word格式.docx
- 文档编号:13450152
- 上传时间:2022-10-10
- 格式:DOCX
- 页数:35
- 大小:821.08KB
时间序列计量经济学模型案例Word格式.docx
《时间序列计量经济学模型案例Word格式.docx》由会员分享,可在线阅读,更多相关《时间序列计量经济学模型案例Word格式.docx(35页珍藏版)》请在冰豆网上搜索。
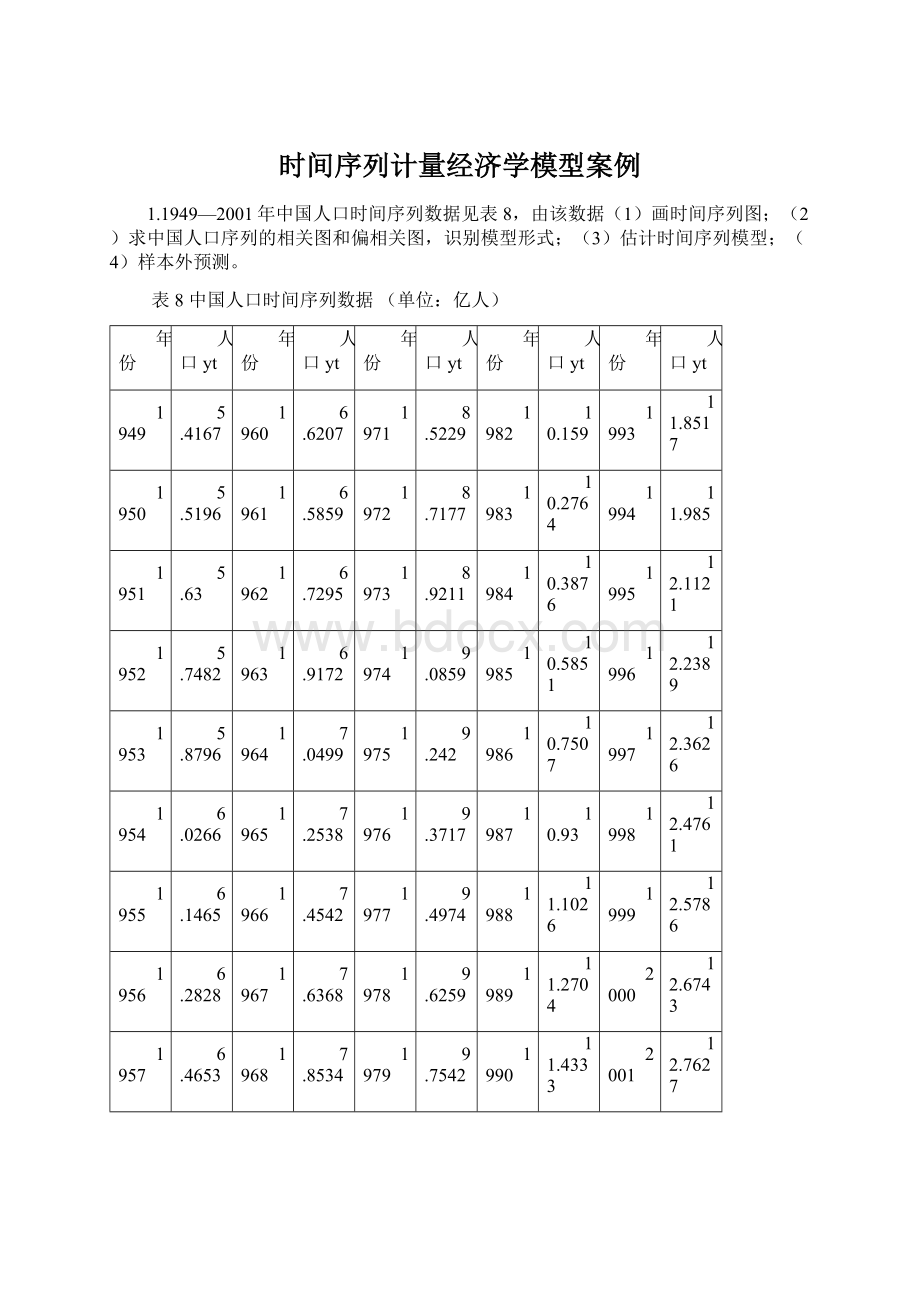
10.3876
1995
12.1121
1952
5.7482
1963
6.9172
1974
9.0859
1985
10.5851
1996
12.2389
1953
5.8796
1964
7.0499
1975
9.242
1986
10.7507
1997
12.3626
1954
6.0266
1965
7.2538
1976
9.3717
1987
10.93
1998
12.4761
1955
6.1465
1966
7.4542
1977
9.4974
1988
11.1026
1999
12.5786
1956
6.2828
1967
7.6368
1978
9.6259
1989
11.2704
2000
12.6743
1957
6.4653
1968
7.8534
1979
9.7542
1990
11.4333
2001
12.7627
1958
6.5994
1969
8.0671
1980
9.8705
1991
11.5823
1959
6.7207
1970
8.2992
1981
10.0072
1992
11.7171
(1)画时间序列图
打开的数据窗口
得到中国人口序列图
求中国人口差分图:
中国人口差分图如下:
从人口序列图和人口差分序列图可以看出我国人口总水平除在1960年和1961年两年出现回落外,其余年份基本上保持线性增长趋势。
52年间平均每年增加人口1412.6923万人,年平均增长率为1.66%。
由于总人口数逐年增加,实际上的年人口增长率是逐渐下降的。
把52年分为两个时期,即改革开放以前时期(1949—1978年)和改革开放以后时期(1979—2001年),则前一个时期的人口年平均增长率为2%,后一个时期的年平均增长率为1.23%。
从人口序列的变化特征看,这是一个非平稳序列。
(2)求中国人口序列的相关图和偏相关图,识别模型形式
打开数据窗口,过程如下:
Level表示选择对画相关图、偏相关图。
滞后期为10。
结果如下:
由相关图衰减缓慢可以知道,中国人口序列是非平稳序列。
做的相关图和偏相关图如下:
由上图可以看出,自相关函数呈指数衰减,偏自相关函数1阶或2阶截尾。
所以是一个1阶或2阶自回归过程。
(3)时间序列模型估计
模型估计命令如下,同时将样本改为1949—2000年,留下2001年的值用于计算预测精度。
输出结果如下:
从上面的输出结果可以看出,AR
(2)的系数没有显著性,因此需要从模型中将其剔除继续估计。
得到重新的估计结果如下:
对应的模型表达式为:
(8.7)
(5.4)
直接写为:
输出结果中的0.1429是
的均值,表示年平均人口增量是0.1429亿人。
整理上述输出结果,得:
0.0547表示线性趋势的增长速度。
从输出结果的最后一行可以知道,特征根是1/0.62=1.61,满足平稳性要求。
检验模型的误差项:
选滞后期为10
得到如下输出结果:
从对应的概率值可以看出,所有的Q值都小于检验水平为0.05的分布,所以模型的随机误差项是一个白噪声序列。
(4)样本外预测
过程如下:
预测方法选择静态预测。
已知2001年中国人口实际数是12.7627亿人,预测值为12.788亿人,误差为0.2%。
2.1967—1998年天津市保费收入(,万元)和人口(,万人)数据见表9。
表9天津市保费收入()和人口()数据
Yt(万元)
Xt(万人)
259
649.72
5357
785.28
304
655.04
6743
795.52
313
650.75
8919
804.8
315
652.7
14223
814.97
322
663.41
19007
828.73
438
674.65
23540
839.21
706
683.31
29264
852.35
624
692.47
34327
866.25
632
702.86
39474
872.63
591
706.5
49624
878.97
622
712.87
67412
885.89
806
724.27
100561
890.55
1172
739.42
123655
894.67
2865
748.91
171768
898.45
4223
760.32
243377
899.8
5112
774.92
271654
905.09
对数的天津保费收入
和人口的散点图如下图:
所以可以建立半对数模型。
相应表达式为:
(-20.9)(37.2)
因为DW=0.36,说明模型误差项存在严重自相关。
观察残差序列的自相关结构。
得到如下结果:
由上图可以看出自相关函数拖尾,偏自相关函数2阶截尾,残差序列是一个明显的AR
(2)过程。
重新进行回归分析,得如下结果:
相应表达式是:
(-8.6)(15.3)(6.5)(-2.2)
这种模型称作回归于时间序列组合模型。
通过对回归模型残差序列建立时间序列模型提高回归参数估计量的有效性,所以组合模型估计的回归参数0.0259要比OLS估计结果0.0254的品质要好。
拟合度也有所提高,并且消除了残差的自相关性。
3.做663天的深证成指(SZ)序列:
从SZ的序列走势可以看出,SZ序列既不是确定性趋势非平稳序列,也不是随机趋势序列。
所以先按随机趋势序列设定检验式。
打开SZ的数据文件
对SZ原序列进行ADF检验,检验式不包括趋势项,包括截距项。
得到ADF的检验结果如下:
带有截距项的DF检验式的估计结果如下:
(1.9)(-1.8)
从
的系数的t检验可以看出,SZ序列存在单位根。
但是常数项也没有通过t检验,所以从检验式中去掉截距项,继续进行单位根检验。
则DF检验式的估计结果如下:
(0.4)
DF=0.4,大于临界值。
SZ序列是一个随机游走过程,并不含有随机趋势。
对
的差分序列
继续做单位根检验。
得到的结果如下:
所以:
(-25.7)
ADF=-25.7,所以
是平稳序列,
。
4.利用表9.1的数据
(1)做出时间序列
与
的样本相关图,并通过图形判断该两时间序列的平稳性。
(2)对
序列进行单位检验,以进一步明确它们的平稳性。
(3)如果不进行进一步的检验,直接估计以下简单的回归模型,是否认为此回归是虚假回归:
表9.1中国GDP与消费支出单位:
亿元
CONS
GDP
1759.100
3605.600
9113.200
18319.50
2005.400
4074.000
10315.90
21280.40
2317.100
4551.300
12459.80
25863.70
2604.100
4901.400
15682.40
34500.70
2867.900
5489.200
20809.80
46690.70
3182.500
6076.300
26944.50
58510.50
3674.500
7164.400
32152.30
68330.40
4589.000
8792.100
34854.60
74894.20
5175.000
10132.80
36921.10
79003.30
5961.200
11784.70
39334.40
82673.10
7633.100
14704.00
42911.90
89112.50
8523.500
16466.00
(1)首先做
的样本相关图,过程如下:
做
的样本相关图。
由于是做
的水平序列,所以选择level,并包括12期滞后。
得到
的样本相关图如下:
从样本的自相关函数图可以看出,函数并没有迅速趋向于零,并在零附近波动,说明
序列是非平稳的。
用同样的方法,做
序列的自相关函数图如下:
从上面的样本自相关函数图可以看出,
的自相关函数并没有迅速趋于零,并在零附近波动,说明
序列也是非平稳的。
(2)首先对
进行单位根检验,过程如下:
先从模型3进行检验,包括截距项,时间趋势及一阶滞后项的模型。
从上面的伴随概率值可以知道,在5%的显著性水平下,不拒绝存在单位根的假设,表明
是非平稳的。
对模型2进行检验,即不包括时间趋势的模型,结果如下:
从伴随概率值可以看出,在5%的显著性水平下,不拒绝存在单位根的假设,
对模型1进行检验,即不包括截距项和时间趋势。
从伴随概率值可以看出,在5%的显著性水平下,不拒绝存在单位根的检验,
综上所述,
序列是非平稳序列。
用同样的方法对
序列进行检验,可以知道,在5%的显著性水平下,
(2)由于时间序列
和
是非平稳的,如果没有进行协整性检验,直接对两者做OLS回归,此回归很可能是虚假回归。
5.以上题的数据为基础,利用
的数据。
(1)检验
单整性。
(2)尝试建立
的ARMA模型。
单整性的检验仍然通过单位根检验进行。
但此时,针对的时间序列不是原序列的水平序列,而是一阶差分、二阶差分


- 配套讲稿:
如PPT文件的首页显示word图标,表示该PPT已包含配套word讲稿。双击word图标可打开word文档。
- 特殊限制:
部分文档作品中含有的国旗、国徽等图片,仅作为作品整体效果示例展示,禁止商用。设计者仅对作品中独创性部分享有著作权。
- 关 键 词:
- 时间 序列 计量 经济学 模型 案例
 冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 (完整word版)信息论与编码期末考试题----学生复习用.doc
(完整word版)信息论与编码期末考试题----学生复习用.doc
-
(完整)六年级上册几何图形题.docx
-
(完整)储罐防腐施工方案.doc
-
(完整word版)公务员录用体检表.doc
-
(完整)八年级上册几何证明题专项练习.doc
-
(决策管理)投资决策委员会实施细则.doc
-
(完整)四年级上册口算、竖式计算、脱式计算.doc
-
(压轴题)初中物理八年级上册第一章《机械运动》检测(含答案解析)(2).doc
-
(完整)小学三年级心理健康教案.doc
-
(完整)初中文言文翻译技巧.doc
-
(名师整理)语文中考《骆驼祥子》名著导读优秀教案.docx
-
(完整word版)偏旁部首名称大全.doc
-
(人教PEP)五年级英语竞赛试题及答案.doc
-
(完整)山东省普通高中学生综合素质评价信息管理系统操作手册学生用户手册.doc
-
(完整word版)体育课教案模板.doc
-
(住宅楼方案)房屋建筑学课程设计说明书.doc
-
(完整word版)《分数的意义》优秀教学设计(公开课).doc
-
(完整word版)安全生产标准化实施方案.doc
-
(完整)初中生人物形象分析常用词汇.doc
-
(完整版)借用公司资质协议.doc
-
(完整word版)仙剑奇侠传三图文攻略(最详细版).doc
-
(完整word版)历年陕西省专升本英语真题(答案解析超全).doc
-
(完整)四年级四则混合运算训练题100道.doc
-
(完整word版)学校团总支部换届选举方案.doc
-
(完整word版)安全标准化绩效评定计划.doc
-
(完整)分布式光伏发电项目施工组织设计.doc
-
(完整版)埋地塑料管结构环刚度计算.doc
-
(完整版)国家农业产业强镇示范建设实施方案.doc
-
(完整版)八年级数学上几何典型试题及答案.doc
-
(完整版)六年级音乐下册人音版理论知识梳理.doc
-
(完整版)囚徒健身图文教程和计划表(完美打印版).doc
 (完整版)固定资产盘点表.xls
(完整版)固定资产盘点表.xls
-
注册测绘师案例分析.docx
-
中考英语调研测试试题3.docx
-
祝福语结婚大全.docx
-
中考语文一轮复习专题10文言文阅读知识点练习.docx
-
转正工作总结模板汇总.docx
-
中秋活动策划方案4篇与中秋游园晚会策划书汇编.docx
-
中小学生安全知识竞赛题参考答案.docx
-
桌游策划书.docx
-
中学为体西学为用.docx
-
中药材种植及加工项目可行性研究报告.docx
-
中医医院新入职护士培训大纲.docx
-
英国人吃什么的作文.docx
-
英语辩论大学生选择专业适应社会需要比个人喜好更重要.docx
-
英语判断题.docx
-
英语数词的用法.docx
-
英语专业学生适合的证书考试.docx
-
营养学名词解释.docx
-
应急预案综合预案.docx
-
永宁中学八年级信息技术Flash教案.docx
