 大数据技术之电商推荐系统.docx
大数据技术之电商推荐系统.docx
- 文档编号:12065980
- 上传时间:2023-04-16
- 格式:DOCX
- 页数:75
- 大小:875.50KB
大数据技术之电商推荐系统.docx
《大数据技术之电商推荐系统.docx》由会员分享,可在线阅读,更多相关《大数据技术之电商推荐系统.docx(75页珍藏版)》请在冰豆网上搜索。
大数据技术之电商推荐系统
尚硅谷大数据技术之电商推荐系统
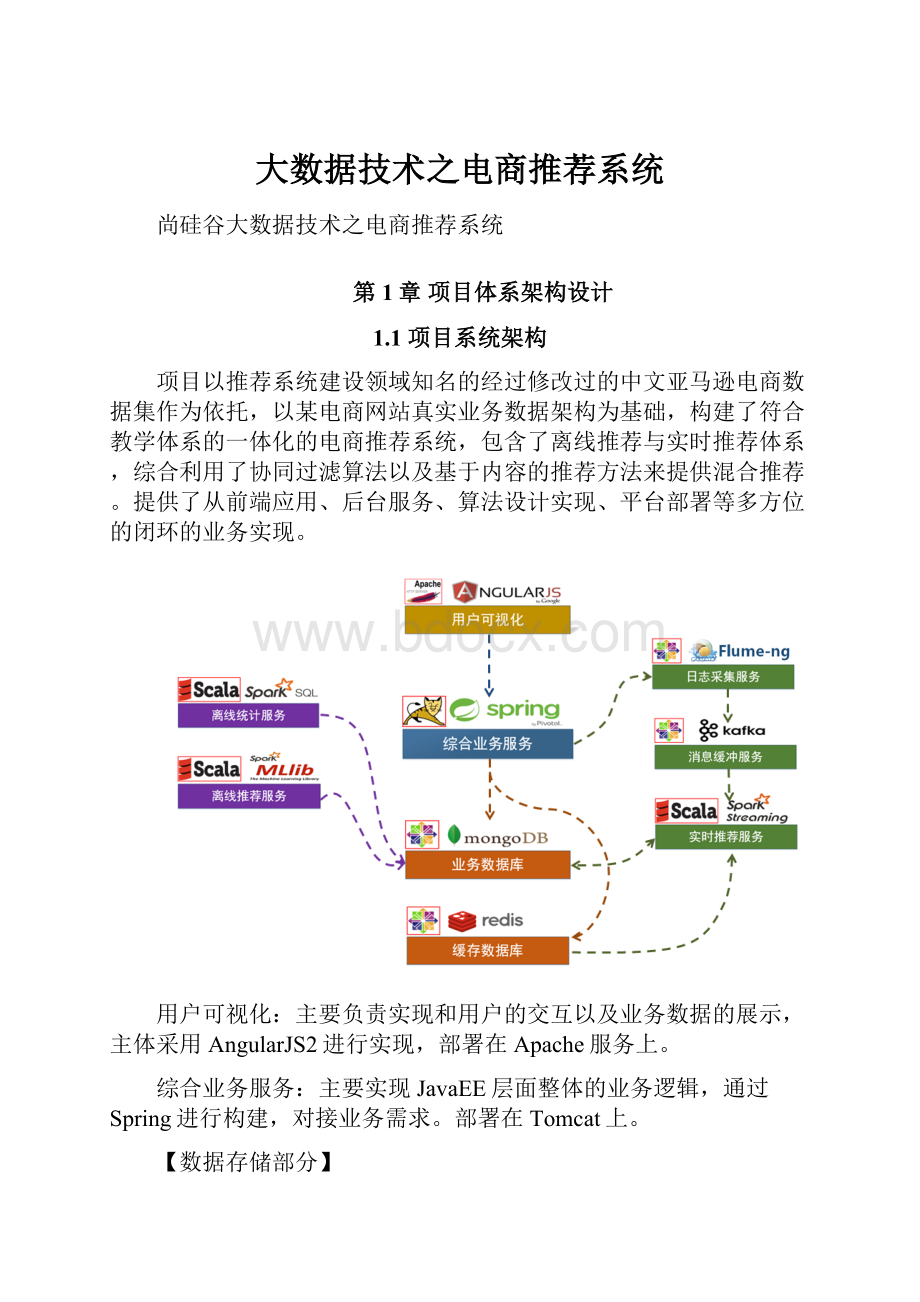
第1章项目体系架构设计
1.1项目系统架构
项目以推荐系统建设领域知名的经过修改过的中文亚马逊电商数据集作为依托,以某电商网站真实业务数据架构为基础,构建了符合教学体系的一体化的电商推荐系统,包含了离线推荐与实时推荐体系,综合利用了协同过滤算法以及基于内容的推荐方法来提供混合推荐。
提供了从前端应用、后台服务、算法设计实现、平台部署等多方位的闭环的业务实现。
用户可视化:
主要负责实现和用户的交互以及业务数据的展示,主体采用AngularJS2进行实现,部署在Apache服务上。
综合业务服务:
主要实现JavaEE层面整体的业务逻辑,通过Spring进行构建,对接业务需求。
部署在Tomcat上。
【数据存储部分】
业务数据库:
项目采用广泛应用的文档数据库MongDB作为主数据库,主要负责平台业务逻辑数据的存储。
缓存数据库:
项目采用Redis作为缓存数据库,主要用来支撑实时推荐系统部分对于数据的高速获取需求。
【离线推荐部分】
离线统计服务:
批处理统计性业务采用SparkCore+SparkSQL进行实现,实现对指标类数据的统计任务。
离线推荐服务:
离线推荐业务采用SparkCore+SparkMLlib进行实现,采用ALS算法进行实现。
【实时推荐部分】
日志采集服务:
通过利用Flume-ng对业务平台中用户对于商品的一次评分行为进行采集,实时发送到Kafka集群。
消息缓冲服务:
项目采用Kafka作为流式数据的缓存组件,接受来自Flume的数据采集请求。
并将数据推送到项目的实时推荐系统部分。
实时推荐服务:
项目采用SparkStreaming作为实时推荐系统,通过接收Kafka中缓存的数据,通过设计的推荐算法实现对实时推荐的数据处理,并将结构合并更新到MongoDB数据库。
1.2项目数据流程
【系统初始化部分】
1.通过SparkSQL将系统初始化数据加载到MongoDB中。
【离线推荐部分】
2.可以通过Azkaban实现对于离线统计服务以离线推荐服务的调度,通过设定的运行时间完成对任务的触发执行。
3.离线统计服务从MongoDB中加载数据,将【商品平均评分统计】、【商品评分个数统计】、【最近商品评分个数统计】三个统计算法进行运行实现,并将计算结果回写到MongoDB中;离线推荐服务从MongoDB中加载数据,通过ALS算法分别将【用户推荐结果矩阵】、【影片相似度矩阵】回写到MongoDB中。
【实时推荐部分】
4.Flume从综合业务服务的运行日志中读取日志更新,并将更新的日志实时推送到Kafka中;Kafka在收到这些日志之后,通过kafkaStream程序对获取的日志信息进行过滤处理,获取用户评分数据流【UID|MID|SCORE|TIMESTAMP】,并发送到另外一个Kafka队列;SparkStreaming监听Kafka队列,实时获取Kafka过滤出来的用户评分数据流,融合存储在Redis中的用户最近评分队列数据,提交给实时推荐算法,完成对用户新的推荐结果计算;计算完成之后,将新的推荐结构和MongDB数据库中的推荐结果进行合并。
【业务系统部分】
5.推荐结果展示部分,从MongoDB中将离线推荐结果、实时推荐结果、内容推荐结果进行混合,综合给出相对应的数据。
6.商品信息查询服务通过对接MongoDB实现对商品信息的查询操作。
7.商品评分部分,获取用户通过UI给出的评分动作,后台服务进行数据库记录后,一方面将数据推动到Redis群中,另一方面,通过预设的日志框架输出到Tomcat中的日志中。
8.商品标签部分,项目提供用户对商品打标签服务。
1.3数据模型
1.Product【商品数据表】
字段名
字段类型
字段描述
字段备注
productId
Int
商品的ID
name
String
商品的名称
categories
String
商品所属类别
每一项用“|”分割
imageUrl
String
商品图片的URL
tags
String
商品的UGC标签
每一项用“|”分割
2.Rating【用户评分表】
字段名
字段类型
字段描述
字段备注
userId
Int
用户的ID
productId
Int
商品的ID
score
Double
商品的分值
timestamp
Long
评分的时间
3.Tag【商品标签表】
字段名
字段类型
字段描述
字段备注
userId
Int
用户的ID
productId
Int
商品的ID
tag
String
商品的标签
timestamp
Long
评分的时间
4.User【用户表】
字段名
字段类型
字段描述
字段备注
userId
Int
用户的ID
username
String
用户名
password
String
用户密码
timestamp
Lon0067
用户创建的时间
5.RateMoreProductsRecently【最近商品评分个数统计表】
字段名
字段类型
字段描述
字段备注
productId
Int
商品的ID
count
Int
商品的评分数
yearmonth
String
评分的时段
yyyymm
6.RateMoreProducts【商品评分个数统计表】
字段名
字段类型
字段描述
字段备注
productId
Int
商品的ID
count
Int
商品的评分数
7.AverageProductsScore【商品平均评分表】
字段名
字段类型
字段描述
字段备注
productId
Int
商品的ID
avg
Double
商品的平均评分
8.ProductRecs【商品相似性矩阵】
字段名
字段类型
字段描述
字段备注
productId
Int
商品的ID
recs
Array[(productId:
Int,score:
Double)]
该商品最相似的商品集合
9.UserRecs【用户商品推荐矩阵】
字段名
字段类型
字段描述
字段备注
userId
Int
用户的ID
recs
Array[(productId:
Int,score:
Double)]
推荐给该用户的商品集合
10.StreamRecs【用户实时商品推荐矩阵】
字段名
字段类型
字段描述
字段备注
userId
Int
用户的ID
recs
Array[(productId:
Int,score:
Double)]
实时推荐给该用户的商品集合
第2章工具环境搭建
我们的项目中用到了多种工具进行数据的存储、计算、采集和传输,本章主要简单介绍设计的工具环境搭建。
如果机器的配置不足,推荐只采用一台虚拟机进行配置,而非完全分布式,将该虚拟机CPU的内存设置的尽可能大,推荐为CPU>4、MEM>4GB。
2.1MongoDB(单节点)环境配置
//通过WGET下载Linux版本的MongoDB
[bigdata@linux~]$wgethttps:
//fastdl.mongodb.org/linux/mongodb-linux-x86_64-rhel62-3.4.3.tgz
//将压缩包解压到指定目录
[bigdata@linuxbackup]$tar-xfmongodb-linux-x86_64-rhel62-3.4.3.tgz-C~/
//将解压后的文件移动到最终的安装目录
[bigdata@linux~]$mvmongodb-linux-x86_64-rhel62-3.4.3//usr/local/mongodb
//在安装目录下创建data文件夹用于存放数据和日志
[bigdata@linuxmongodb]$mkdir/usr/local/mongodb/data/
//在data文件夹下创建db文件夹,用于存放数据
[bigdata@linuxmongodb]$mkdir/usr/local/mongodb/data/db/
//在data文件夹下创建logs文件夹,用于存放日志
[bigdata@linuxmongodb]$mkdir/usr/local/mongodb/data/logs/
//在logs文件夹下创建log文件
[bigdata@linuxmongodb]$touch/usr/local/mongodb/data/logs/mongodb.log
//在data文件夹下创建mongodb.conf配置文件
[bigdata@linuxmongodb]$touch/usr/local/mongodb/data/mongodb.conf
//在mongodb.conf文件中输入如下内容
[bigdata@linuxmongodb]$vim./data/mongodb.conf
#端口号port=27017
#数据目录
dbpath=/usr/local/mongodb/data/db
#日志目录
logpath=/usr/local/mongodb/data/logs/mongodb.log
#设置后台运行
fork=true
#日志输出方式
logappend=true
#开启认证
#auth=true
完成MongoDB的安装后,启动MongoDB服务器:
//启动MongoDB服务器
[bigdata@linuxmongodb]$sudo/usr/local/mongodb/bin/mongod-config/usr/local/mongodb/data/mongodb.conf
//访问MongoDB服务器
[bigdata@linuxmongodb]$/usr/local/mongodb/bin/mongo
//停止MongoDB服务器
[bigdata@linuxmongodb]$sudo/usr/local/mongodb/bin/mongod-shutdown-config/usr/local/mongodb/data/mongodb.conf
2.2Redis(单节点)环境配置
//通过WGET下载REDIS的源码
[bigdata@linux~]$wgethttp:
//download.redis.io/releases/redis-4.0.2.tar.gz
//将源代码解压到安装目录
[bigdata@linux~]$tar-xfredis-4.0.2.tar.gz-C~/
//进入Redis源代码目录,编译安装
[bigdata@linux~]$cdredis-4.0.2/
//安装GCC
[bigdata@linux~]$sudoyuminstallgcc
//编译源代码
[bigdata@linuxredis-4.0.2]$makeMALLOC=libc
//编译安装
[bigdata@linuxredis-4.0.2]$sudomakeinstall
//创建配置文件
[bigdata@linuxredis-4.0.2]$sudocp~/redis-4.0.2/redis.conf/etc/
//修改配置文件中以下内容
[bigdata@linuxredis-4.0.2]$sudovim/etc/redis.conf
daemonizeyes #37行 #是否以后台daemon方式运行,默认不是后台运行
pidfile/var/run/redis/redis.pid #41行 #redis的PID文件路径(可选)
bind0.0.0.0 #64行 #绑定主机IP,默认值为127.0.0.1,我们是跨机器运行,所以需要更改
logfile/var/log/redis/redis.log #104行 #定义log文件位置,模式log信息定向到stdout,输出到/dev/null(可选)
dir“/usr/local/rdbfile” #188行 #本地数据库存放路径,默认为./,编译安装默认存在在/usr/local/bin下(可选)
在安装完Redis之后,启动Redis
//启动Redis服务器
[bigdata@linuxredis-4.0.2]$redis-server/etc/redis.conf
//连接Redis服务器
[bigdata@linuxredis-4.0.2]$redis-cli
//停止Redis服务器
[bigdata@linuxredis-4.0.2]$redis-clishutdown
2.3Spark(单节点)环境配置
//通过wget下载zookeeper安装包
[bigdata@linux~]$wget
//将spark解压到安装目录
[bigdata@linux~]$tar–xfspark-2.1.1-bin-hadoop2.7.tgz–C./cluster
//进入spark安装目录
[bigdata@linuxcluster]$cdspark-2.1.1-bin-hadoop2.7/
//复制slave配置文件
[bigdata@linuxspark-2.1.1-bin-hadoop2.7]$cp./conf/slaves.template./conf/slaves
//修改slave配置文件
[bigdata@linuxspark-2.1.1-bin-hadoop2.7]$vim./conf/slaves
linux#在文件最后将本机主机名进行添加
//复制Spark-Env配置文件
[bigdata@linuxspark-2.1.1-bin-hadoop2.7]$cp./conf/spark-env.sh.template./conf/spark-env.sh
SPARK_MASTER_HOST=linux#添加sparkmaster的主机名
SPARK_MASTER_PORT=7077#添加sparkmaster的端口号
安装完成之后,启动Spark
//启动Spark集群
[bigdata@linuxspark-2.1.1-bin-hadoop2.7]$sbin/start-all.sh
//访问Spark集群,浏览器访问http:
//linux:
8080
//关闭Spark集群
[bigdata@linuxspark-2.1.1-bin-hadoop2.7]$sbin/stop-all.sh
2.4Zookeeper(单节点)环境配置
//通过wget下载zookeeper安装包
[bigdata@linux~]$wget
//将zookeeper解压到安装目录
[bigdata@linux~]$tar–xfzookeeper-3.4.10.tar.gz–C./cluster
//进入zookeeper安装目录
[bigdata@linuxcluster]$cdzookeeper-3.4.10/
//创建data数据目录
[bigdata@linuxzookeeper-3.4.10]$mkdirdata/
//复制zookeeper配置文件
[bigdata@linuxzookeeper-3.4.10]$cp./conf/zoo_sample.cfg./conf/zoo.cfg
//修改zookeeper配置文件
[bigdata@linuxzookeeper-3.4.10]$vimconf/zoo.cfg
dataDir=/home/bigdata/cluster/zookeeper-3.4.10/data#将数据目录地址修改为创建的目录
//启动Zookeeper服务
[bigdata@linuxzookeeper-3.4.10]$bin/zkServer.shstart
//查看Zookeeper服务状态
[bigdata@linuxzookeeper-3.4.10]$bin/zkServer.shstatus
ZooKeeperJMXenabledbydefault
Usingconfig:
/home/bigdata/cluster/zookeeper-3.4.10/bin/../conf/zoo.cfg
Mode:
standalone
//关闭Zookeeper服务
[bigdata@linuxzookeeper-3.4.10]$bin/zkServer.shstop
2.5Flume-ng(单节点)环境配置
//通过wget下载zookeeper安装包
[bigdata@linux~]$wgethttp:
//www.apache.org/dyn/closer.lua/flume/1.8.0/apache-flume-1.8.0-bin.tar.gz
//将zookeeper解压到安装目录
[bigdata@linux~]$tar–xfapache-flume-1.8.0-bin.tar.gz–C./cluster
//等待项目部署时使用
2.6Kafka(单节点)环境配置
//通过wget下载zookeeper安装包
[bigdata@linux~]$wget
//将kafka解压到安装目录
[bigdata@linux~]$tar–xfkafka_2.12-0.10.2.1.tgz–C./cluster
//进入kafka安装目录
[bigdata@linuxcluster]$cdkafka_2.12-0.10.2.1/
//修改kafka配置文件
[bigdata@linuxkafka_2.12-0.10.2.1]$vimconfig/server.properties
host.name=linux#修改主机名
port=9092#修改服务端口号
zookeeper.connect=linux:
2181#修改Zookeeper服务器地址
//启动kafka服务!
!
!
启动之前需要启动Zookeeper服务
[bigdata@linuxkafka_2.12-0.10.2.1]$bin/kafka-server-start.sh-daemon./config/server.properties
//关闭kafka服务
[bigdata@linuxkafka_2.12-0.10.2.1]$bin/kafka-server-stop.sh
//创建topic
[bigdata@linuxkafka_2.12-0.10.2.1]$bin/kafka-topics.sh--create--zookeeperlinux:
2181--replication-factor1--partitions1--topicrecommender
//kafka-console-producer
[bigdata@linuxkafka_2.12-0.10.2.1]$bin/kafka-console-producer.sh--broker-listlinux:
9092--topicrecommender
//kafka-console-consumer
[bigdata@linuxkafka_2.12-0.10.2.1]$bin/kafka-console-consumer.sh--bootstrap-serverlinux:
9092--topicrecommender
第3章创建项目并初始化业务数据
我们的项目主体用Scala编写,采用IDEA作为开发环境进行项目编写,采用maven作为项目构建和管理工具。
3.1在IDEA中创建maven项目
打开IDEA,创建一个maven项目,命名为ECommerceRecommendSystem。
为了方便后期的联调,我们会把业务系统的代码也添加进来,所以我们可以以ECommerceRecommendSystem作为父项目,并在其下建一个名为recommender的子项目,然后再在下面搭建多个子项目用于提供不同的推荐服务。
3.1.1项目框架搭建
在ECommerceRecommendSystem下新建一个mavenmodule作为子项目,命名为recommender。
同样的,再以recommender为父项目,新建一个mavenmodule作为子项目。
我们的第一步是初始化业务数据,所以子项目命名为DataLoader。
父项目只是为了规范化项目结构,方便依赖管理,本身是不需要代码实现的,所以ECommerceRecommendSystem和recommender下的src文件夹都可以删掉。
目前的整体项目框架如下:
3.1.2声明项目中工具的版本信息
我们整个项目需要用到多个工具,它们的不同版本可能会对程序运行造成影响,所以应该在最外层的ECommerceRecommendSystem中声明所有子项目共用的版本信息。
在pom.xml中加入以下配置:
ECommerceRecommendSystem/pom.xml


- 配套讲稿:
如PPT文件的首页显示word图标,表示该PPT已包含配套word讲稿。双击word图标可打开word文档。
- 特殊限制:
部分文档作品中含有的国旗、国徽等图片,仅作为作品整体效果示例展示,禁止商用。设计者仅对作品中独创性部分享有著作权。
- 关 键 词:
- 数据 技术 推荐 系统
 冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 铝散热器项目年度预算报告.docx
铝散热器项目年度预算报告.docx
-
牛津上海版通用小学英语三年级上册Unit 12同步练习2II 卷.docx
-
论我国私营企业员工激励机制.docx
-
人教版五年级品德与社会上册全册教案.docx
-
开学啦国旗下讲话稿三分钟.docx
-
露天采矿学复习题.docx
-
六年级英语教师年度考核个人总结.docx
-
某路站综合体项PC吊装施工方案.docx
-
人教版九年级历史上册期末考试试题一套.docx
-
隆昌妇幼保健院.docx
-
芦二矿抽采达标中长期规划.docx
-
看拼音写词语.docx
-
模拟磁盘调度算法系统的设计毕业设计.docx
-
每周一条名言警句或一首诗词.docx
-
棉花膜下滴灌示范工程设计总结报告.docx
-
九年级化学教案第十单元酸和碱教案新人教版.docx
-
宁波市水资源公报.docx
-
农业实用技术培训工作意见与农业局上半年工作总结范例两篇汇编.docx
-
平行线的判定.docx
-
内部会计管理制度11成本核算制度.docx
-
盘扣式脚手架支撑方案.docx
-
旅游规划模板.docx
-
煤矿大本大专毕业设计大采高综采工作面作业规程.docx
-
美学选择题整理课件资料.docx
-
名家论腹泻慢性肠炎.docx
-
宁夏银川市第一中学学年高一上学期期中考试地理试题解析解析版.docx
-
年产吨精密纤维纸项目建设建议书.docx
-
农技推广中心工作总结.docx
-
彭宇案的法逻辑批判.docx
-
宁夏仕奇房产网发布份房地产交易情况.docx
-
项目推荐书智能温控节能系统.docx
-
区县节日期间加强消防安全讲话稿与区发改委领导班子述职述廉报告汇编.docx
-
计算机专业实习报告总结.docx
-
跨国投资案例跨国经营DOC.docx
-
门板组合冲床项目可行性研究报告.docx
-
考研政治思想道德修养与法律基础复习提纲超强.docx
-
口腔正畸学考试试题二.docx
-
口腔修复学教学大纲.docx
-
小学一年级上书法教案.docx
-
小学一年级数学计算题100以内.docx
 CSCO食管癌指南解读.pptx
CSCO食管癌指南解读.pptx
-
迷雾拉片作业.docx
-
冀教版英语九年级上册第二单元教案.docx
-
民办非企业单位年度财务审计报告范本剖析.docx
-
新疆兵团农二师华山中学学年高一下学期期末考试数学试题 Word版含答案.docx
-
新环保法亮点解读.docx
-
某派出所办公楼工程.docx
-
新概念英语第一册课文版.docx
-
跨径12米贝雷钢便桥计算书.docx
-
跨文化交际问题.docx
-
CRISIS MANAGEMENT PLAN危机管理计划汇编.ppt
