 SPSS统计软件期末作业.docx
SPSS统计软件期末作业.docx
- 文档编号:11963464
- 上传时间:2023-04-16
- 格式:DOCX
- 页数:23
- 大小:956.83KB
SPSS统计软件期末作业.docx
《SPSS统计软件期末作业.docx》由会员分享,可在线阅读,更多相关《SPSS统计软件期末作业.docx(23页珍藏版)》请在冰豆网上搜索。
SPSS统计软件期末作业
统计软件及应用期末作业
完成作业:
3、5、11、12题
第3题:
根本统计分析3
利用居民储蓄调查数据,从中随机选取85%的样本,进行分析,实现以下目标:
1、分析不同职业储户的储蓄目的
(一),只输出图形并进行分析即可,不需要输出频数表格;
2、分析城镇和农村储户对“未来收入状况的变化趋势〞是否持相同的态度;
3.分析储户一次存款金额的分布,并对不同年龄段的储户进行比拟。
根本思路:
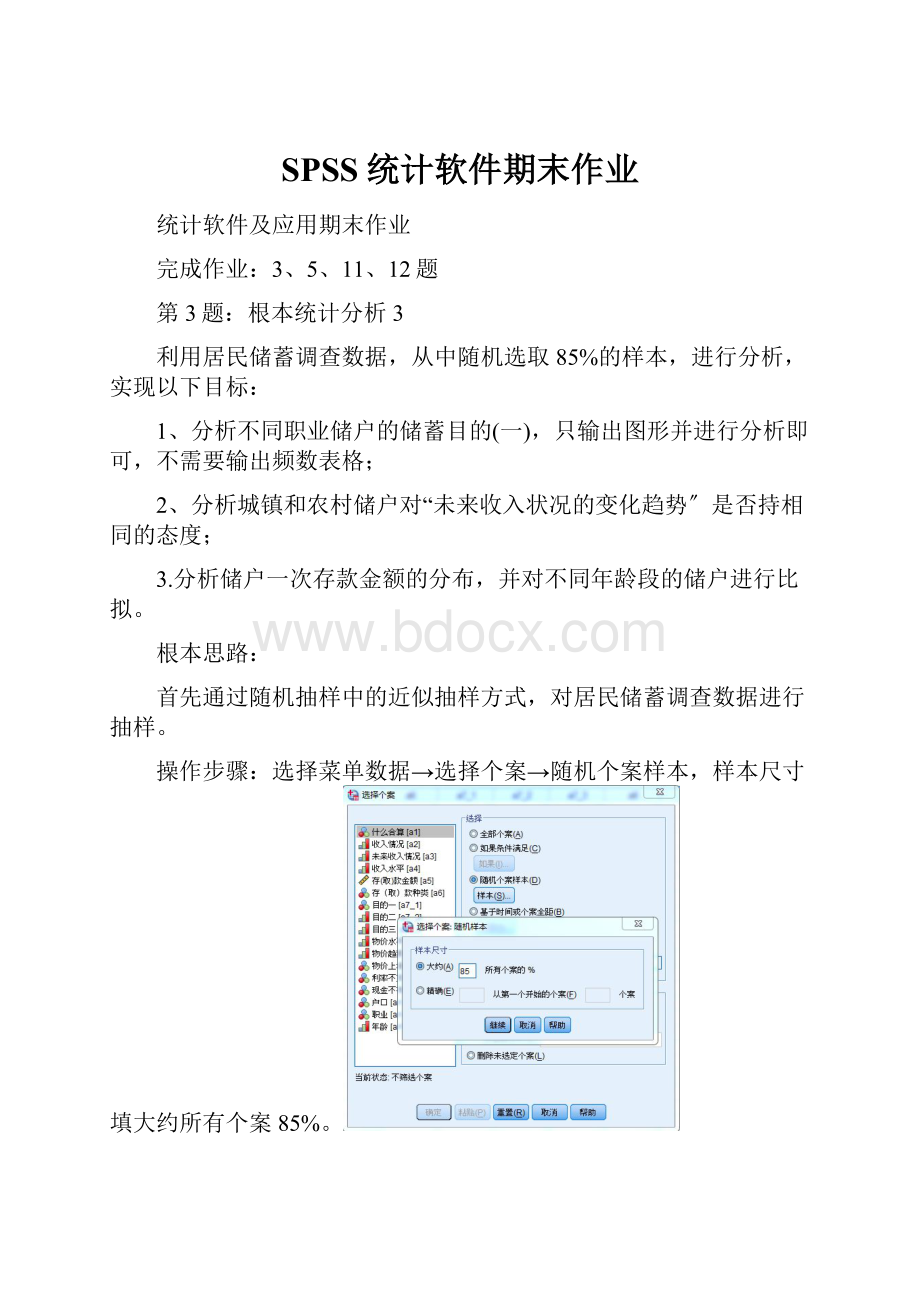
首先通过随机抽样中的近似抽样方式,对居民储蓄调查数据进行抽样。
操作步骤:
选择菜单数据→选择个案→随机个案样本,样本尺寸填大约所有个案85%。
1、题目:
分析不同职业储户的储蓄目的
(一),只输出图形并进行分析即可,不需要输出频数表格。
根本思路:
首先进行多项选择项分析,定义名为X的多项选择项变量集,其中包括a7_1、a7_2、a7_3三个变量,然后对多项选择项变量集进行频数分析;对不同职业储户储蓄目的进行分析,采用多项选择项交叉分组下的频数分析。
操作步骤:
分析:
从折线图看出,储户中商业效劳业的人数最多,总体上所有职业储户的正常生活零用所占的百分比最大,买证券及单位集资的人较少,说明大局部人群还没有这方面的意识。
2、分析城镇和农村储户对“未来收入状况的变化趋势〞是否持相同的态度。
根本思路:
该问题列联表的行变量为户口,列变量为未来收入状况,在列联表中输出各种百分比、期望频数、剩余、标准化剩余,显示各交叉分组下频数分布柱形图,并利用卡方检验方法,对城镇和农村储户对该问题的态度是否一致进行分析。
操作步骤:
分析→描述统计→交叉表,显示复式条形图前打勾,行选择户口,列选择未来收入情况,统计量选择卡方,点击单元格,在观察值、期望值、行、列、总计、四舍五入单元格计数前打勾,最后确认。
输出以下表格和图形:
户口*未来收入情况交叉制表
未来收入情况
合计
增加
根本不变
减少
户口
城镇户口
计数
38
111
20
169
期望的计数
户口中的%
22.5%
65.7%
11.8%
100.0%
未来收入情况中的%
73.1%
77.6%
51.3%
72.2%
总数的%
16.2%
47.4%
8.5%
72.2%
农村户口
计数
14
32
19
65
期望的计数
户口中的%
21.5%
49.2%
29.2%
100.0%
未来收入情况中的%
26.9%
22.4%
48.7%
27.8%
总数的%
6.0%
13.7%
8.1%
27.8%
合计
计数
52
143
39
234
期望的计数
户口中的%
22.2%
61.1%
16.7%
100.0%
未来收入情况中的%
100.0%
100.0%
100.0%
100.0%
总数的%
22.2%
61.1%
16.7%
100.0%
卡方检验
值
df
渐进Sig.(双侧)
Pearson卡方
a
2
.005
似然比
2
.007
线性和线性组合
1
.043
有效案例中的N
234
a.0单元格(0.0%)的期望计数少于5。
最小期望计数为10.83。
分析:
因为卡方值小于0.05拒绝原假设,认为行列变量之间相关,户口对未来收入看法有影响,说明城镇和农村储户对“未来收入状况的变化趋势〞持不同的态度。
3、分析储户一次存款金额的分布,并对不同年龄段的储户进行比拟。
根本思路:
由于存款金额数据为定距型变量,直接采用频数分析不利于对其分布形态的把握,因此考虑依据第三章中的数据分组功能对数据分组后再编制频数分布表。
操作步骤:
转换→重新编码为不同变量→选择存〔取〕款金额,输出变量名称填存款金额分组,单击旧值和新值,对数据进行分组,分为0-500、501-2000、2001-3500、3501-5000、5000以上五个组。
最后点击确定。
再分析→描述统计→频率→变量:
存款金额分组,图表选择直方图,选择显示正态曲线。
最后输出以下图表:
存款金额分组
频率
百分比
有效百分比
累积百分比
有效
85
77
12
23
49
合计
246
根本思路:
进行数据拆分,并计算不同年龄段储户的一次存款金额的四分位数,并通过四分位数比拟分布上的差异。
步骤:
数据→拆分文件→分组方式:
年龄→确定。
分析→描述统计→频率→统计量→四分位数前打勾→确定。
输出如以下图表:
统计量
存款金额分组
20岁以下
N
有效
2
缺失
0
百分位数
25
50
75
.
20~35岁
N
有效
133
缺失
0
百分位数
25
50
75
35~50岁
N
有效
78
缺失
0
百分位数
25
50
75
50岁以上
N
有效
33
缺失
0
百分位数
25
50
75
分析:
分析储户一次存款金额的分布,并对不同年龄段的储户进行比拟。
存款在500以下所占百分比最大,有34.6%,其次是500-1000的人数。
而存款在5000以上的也有19.9%,说明存款数额悬殊较大。
从输出图表中看出20-35年龄段的储户最多,其次是35-50岁年龄段,这两局部的人群存款意识比拟强,20岁以下的储户只有2人,人数特别少,因为这一年龄段的人群大局部是学生,而50岁以上的老人可能更愿意把钱藏在家里而不是拿到银行去存。
第5题:
方差分析2
:
(1)给出SPSS数据集的格式(列举前4个样本即可);
(2)浓度对收率有无显著影响,并进行多重比拟检验(只选用第1个检验指标);
(3)浓度、温度以及它们间的交互作用对收率有无显著影响。
根本思路:
本道题重点考察我们对于在SPSS应用过程中对于方差分析的应用情况。
先将这组数据输入SPSS,然后进行两个方面的计算:
单因素方差分析和多因素方差分析。
利用SPSS的非必须功能,从而得出它们的方差数据,进而进行分析和结果的得出。
多重比拟检验的方法:
LSD方法适用于各总体方差相等的情况,特点是比拟灵敏;Tukey方法和S-N-K方法适用于各水平下观测变量个数相等的情况;Scheffe方法比Tukey方法不灵敏。
(1)给出SPSS数据集的格式(列举前4个样本即可);
操作步骤:
分别定义分组变量A、X、B,在变量视图与数据视图中输入表格数据
(2)浓度对收率有无显著影响,并进行多重比拟检验(只选用第1个检验指标);
操作步骤:
分析-比拟均值-单因素ANOVA-因变量列表:
收率,因子列表:
浓度-确定。
输出如以下图表:
单因素方差分析
收率
平方和
df
均方
F
显著性
组间
2
.041
组内
21
总数
23
显著性=0.41小于0.05说明拒绝原假设〔浓度对收益无显著影响〕,证明浓度对收益有显著影响。
操作步骤:
分析-比拟均值-单因素ANOVA-两两比拟:
LSD-选项:
描述性-确定
输出:
描述
收率
N
均值
标准差
标准误
均值的95%置信区间
极小值
极大值
下限
上限
1
8
.52610
2
8
.64780
3
8
总数
24
.49262
多重比拟
因变量:
收率
LSD
(I)浓度
(J)浓度
均值差(I-J)
标准误
显著性
95%置信区间
下限
上限
1
2
*
.032
.2438
3
.909
2
1
*
.032
3
*
.025
3
1
.12500
.909
2
*
.025
.3688
*.均值差的显著性水平为0.05。
上面有星号的说明有显著差异,即根据LCD算法,浓度1与浓度2具有显著差异,浓度3与浓度2有显著性差异,浓度1与浓度3差异性较小。
(3)浓度、温度以及它们间的交互作用对收率有无显著影响。
操作步骤:
分析-一般线性模型-单变量-因变量:
收率,固定因子:
浓度、温度,-模型选择全因子-确定。
输出:
主体间因子
N
浓度
1
8
2
8
3
8
温度
1
6
2
6
3
6
4
6
主体间效应的检验
因变量:
收率
源
III型平方和
df
均方
F
Sig.
校正模型
a
11
.391
截距
1
.000
A
2
.074
B
3
.917
.462
A*B
6
.607
.721
误差
12
总计
24
校正的总计
23
a.R方=.519〔调整R方=.077〕
分析:
结果说明,只有因子A〔浓度〕是显著的,即浓度不同将对收率产生显著影响,而温度及交互作用的影响都不显著,这说明要提高收率必须把浓度控制好。
方差分析可以很好的去区分两个事物之间存在联系的紧密性。
通过数据,我们可以分辨出浓度的影响更加显著,从而做出调整。
第11题:
曲线回归3
根据收集的1981年至2000年的数据,分析教育支出受年人均可支配收入的影响。
〔提示:
首先绘制两者的散点图。
再尝试选择二次、三次曲线、复合函数和幂函数模型,利用曲线估计进行本质线性模型分析。
〕
思路:
此题主要考察曲线回归的内容,先绘制两者散点图,再用二次、立方、复合、幂函数模型,进行分析。
操作步骤:
图形→旧对话框→散点/点状→简单分布→Y轴:
教育支出,X轴:
年人均可支配收入→确定。
得到散点图如下:
步骤:
分析→回归→曲线估计→因变量:
教育支出,自变量:
年人均可支配收入,个案标签:
年份,模型二次项、立方、幂、复合前打勾→确定。
得到以以下图表:
模型汇总和参数估计值
因变量:
教育支出
方程
模型汇总
参数估计值
R方
F
df1
df2
Sig.
常数
b1
b2
b3
二次
.963
2
8
.000
三次
.964
3
7
.000
复合
.985
1
9
.000
幂
.946
1
9
.000
.000
自变量为年人均可支配收入。
分析:
在二次、三次、复合、幂函数的模型中复合函数的R方是最大、最接近1的。
所以应用复合函数来表示年人均可支配收入与教育支出的函数关系。
根据函数图象看出,教育支出是随年人均可支配收入增长而增长的,说明随着人们可支配收入增加,对教育的关注更多,投入更多。
第12题:
聚类分析1
9个学生的数学、物理、化学、语文、历史、英语的成绩如下表。
要求做K-Means聚类分析,分成3类,初始类中心点由SPSS自行确定。
思路:
此题考察K聚类〔快速聚类〕的内容,根据题目只要指定聚类数目K和确定K个初始类中心即可。
操作步骤:
先把表格数据输入数据编辑器中。
分析→分类→K-均值聚类→变量中把数学、物理、化学、语文、历史、英语选进,聚类数为3→选项→初始聚类中心和ANOVA表前打勾→确定。
初始聚类中心
聚类
1
2
3
数学
65
83
67
物理
61
100
63
化学
72
79
49
语文
84
41
65
历史
81
67
67
英语
79
50
57
迭代历史记录a
迭代
聚类中心内的更改
1
2
3
1
2
.000
.000
.000
a.由于聚类中心内没有改动或改动较小而到达收敛。
任何中心的最大绝对坐标更改为.000。
当前迭代为2。
初始中心间的最小距离为39.724。
最终聚类中心
聚类
1
2
3
数学
74
81
70
物理
68
92
70
化学
71
77
64
语文
79
52
60
历史
81
69
67
英语
72
57
56
ANOVA
聚类
误差
F
Sig.
均方
df
均方
df
数学
2
6
.234
物理
2
6
.017
化学
2
6
.926
.446
语文
2
6
.022
历史
2
6
.009
英语
2
6
.031
F检验应仅用于描述性目的,因为选中的聚类将被用来最大化不同聚类中的案例间的差异。
观测到的显著性水平并未据此进行更正,因此无法将其解释为是对聚类均值相等这一假设的检验。
每个聚类中的案例数
聚类
1
2
3
有效
缺失
.000


- 配套讲稿:
如PPT文件的首页显示word图标,表示该PPT已包含配套word讲稿。双击word图标可打开word文档。
- 特殊限制:
部分文档作品中含有的国旗、国徽等图片,仅作为作品整体效果示例展示,禁止商用。设计者仅对作品中独创性部分享有著作权。
- 关 键 词:
- SPSS 统计 软件 期末 作业
 冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 铝散热器项目年度预算报告.docx
铝散热器项目年度预算报告.docx
-
牛津上海版通用小学英语三年级上册Unit 12同步练习2II 卷.docx
-
论我国私营企业员工激励机制.docx
-
人教版五年级品德与社会上册全册教案.docx
-
开学啦国旗下讲话稿三分钟.docx
-
露天采矿学复习题.docx
-
六年级英语教师年度考核个人总结.docx
-
某路站综合体项PC吊装施工方案.docx
-
人教版九年级历史上册期末考试试题一套.docx
-
隆昌妇幼保健院.docx
-
芦二矿抽采达标中长期规划.docx
-
看拼音写词语.docx
-
模拟磁盘调度算法系统的设计毕业设计.docx
-
每周一条名言警句或一首诗词.docx
-
棉花膜下滴灌示范工程设计总结报告.docx
-
九年级化学教案第十单元酸和碱教案新人教版.docx
-
宁波市水资源公报.docx
-
农业实用技术培训工作意见与农业局上半年工作总结范例两篇汇编.docx
-
平行线的判定.docx
-
内部会计管理制度11成本核算制度.docx
-
盘扣式脚手架支撑方案.docx
-
旅游规划模板.docx
-
煤矿大本大专毕业设计大采高综采工作面作业规程.docx
-
美学选择题整理课件资料.docx
-
名家论腹泻慢性肠炎.docx
-
宁夏银川市第一中学学年高一上学期期中考试地理试题解析解析版.docx
-
年产吨精密纤维纸项目建设建议书.docx
-
农技推广中心工作总结.docx
-
彭宇案的法逻辑批判.docx
-
宁夏仕奇房产网发布份房地产交易情况.docx
-
项目推荐书智能温控节能系统.docx
-
区县节日期间加强消防安全讲话稿与区发改委领导班子述职述廉报告汇编.docx
-
电工年度工作总结范文五篇.docx
-
单亲家庭低保申请条件.docx
-
的会计专业毕业自我鉴定五篇分享.docx
-
电压教学方案.docx
-
电脑广场国庆节企划方案.docx
-
党校培训心得18篇.docx
-
电子商务实习自我鉴定范文(精选4篇).docx
-
第二学期小学三年级班主任班级工作计划.docx
-
德育工作计划.docx
-
董事长元旦致辞元旦演讲稿.docx
-
第一学期三年级语文工作教学总结(精选3篇).docx
-
的名著水浒传的读后有感600字.docx
-
读《鲁滨逊漂流记》有感范文400字5篇.docx
-
第七条猎狗读书心得体会范文五篇.docx
-
读了一千零一夜的心得范文5篇.docx
-
第一学期小学数学教研组工作计划.docx
-
电工实习心得.docx
-
电气技术员年度工作总结.docx
-
电影《雷锋》观后感范文(精选7篇).docx
