 SPSS作业.docx
SPSS作业.docx
- 文档编号:11463075
- 上传时间:2023-03-01
- 格式:DOCX
- 页数:31
- 大小:1.19MB
SPSS作业.docx
《SPSS作业.docx》由会员分享,可在线阅读,更多相关《SPSS作业.docx(31页珍藏版)》请在冰豆网上搜索。
SPSS作业
实验作业一
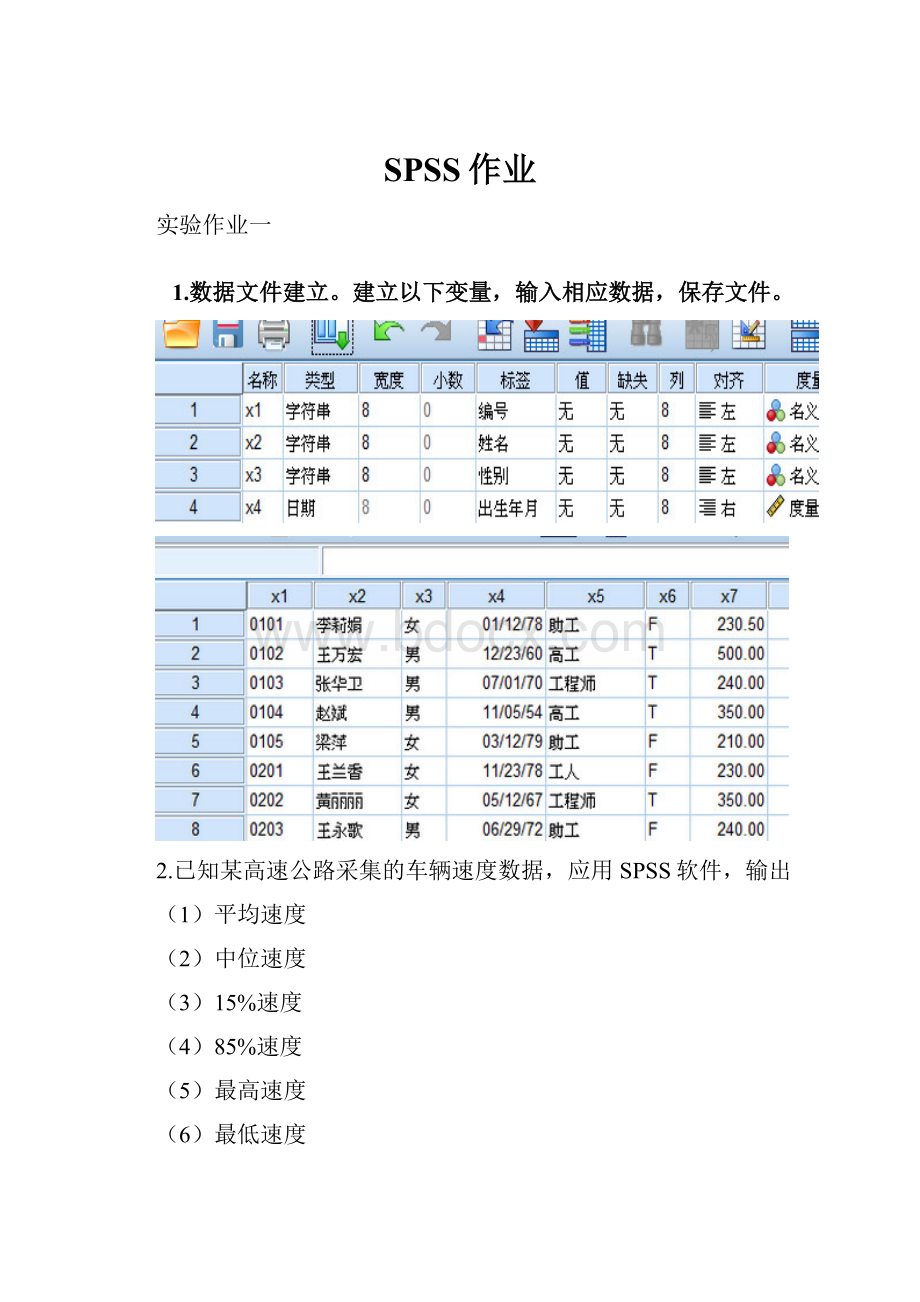
1.数据文件建立。
建立以下变量,输入相应数据,保存文件。
2.已知某高速公路采集的车辆速度数据,应用SPSS软件,输出
(1)平均速度
(2)中位速度
(3)15%速度
(4)85%速度
(5)最高速度
(6)最低速度
(7)标准差
(8)各速度频率及累计频率
过程:
输出:
统计量
VAR00001
N
有效
30
缺失
0
均值
103.50
中值
105.00
标准差
10.451
极小值
84
极大值
128
百分位数
15
91.00
85
113.45
VAR00001
频率
百分比
有效百分比
累积百分比
有效
84
1
3.3
3.3
3.3
85
1
3.3
3.3
6.7
88
1
3.3
3.3
10.0
91
2
6.7
6.7
16.7
94
1
3.3
3.3
20.0
95
1
3.3
3.3
23.3
96
1
3.3
3.3
26.7
97
1
3.3
3.3
30.0
99
1
3.3
3.3
33.3
101
2
6.7
6.7
40.0
103
1
3.3
3.3
43.3
105
3
10.0
10.0
53.3
106
4
13.3
13.3
66.7
107
2
6.7
6.7
73.3
109
1
3.3
3.3
76.7
110
1
3.3
3.3
80.0
111
2
6.7
6.7
86.7
118
1
3.3
3.3
90.0
119
1
3.3
3.3
93.3
121
1
3.3
3.3
96.7
128
1
3.3
3.3
100.0
合计
30
100.0
100.0
(9)以起点为80,组距为5,绘制各组频数直方图,并描绘正态曲线
(10)绘制茎叶图
(11)绘制箱型图
过程:
直方图:
茎叶图:
箱型图:
实验作业二
1.分别测得14名事故组驾驶员及11名非事故组驾驶员反应时数据。
试比较两组驾驶员平均反应时有无显著差别(取置信水平为0.1)
事故组驾驶员:
2.9;5.41;5.48;4.6;4.03;5.1;4.97;4.24;4.36;2.72;2.37;2.09;7.1;5.92
非事故组驾驶员:
5.18;8.79;3.14;6.46;3.72;6.64;5.6;4.57;7.71;4.99;4.01
步骤:
(1)、将数据整合为一列,用0表示事故组,1表示非事故组,如图所示:
(2)选择分析—比较均值—独立样本T检验,如图所示:
(3)在独立样本T检验窗口中将变量导入相关窗口,并定义组,在选项中设置置信区间百分比为90%。
如下:
(4)完成之后选择确定从而得到如下图的结果
组统计量
x1
N
均值
标准差
均值的标准误
x2
.00
14
4.3779
1.44989
.38750
1.00
11
5.5282
1.73540
.52324
独立样本检验
方差方程的Levene检验
均值方程的t检验
F
Sig.
t
df
Sig.(双侧)
均值差值
标准误差值
差分的90%置信区间
下限
上限
x2
假设方差相等
.440
.514
-1.807
23
.084
-1.15032
.63675
-2.24164
-.05901
假设方差不相等
-1.767
19.472
.093
-1.15032
.65111
-2.27478
-.02587
结果分析:
第一张表格给出的是一些统计结果,第二张表格是检验结果,样本在“方差方程的Levene检验”一栏指出,检验类型为F,检验统计量值F=0.440,对应水平值Sig.=0.516,说明在0.1的检验水平下,可以认为方差相等。
因此,进入“均值方程的t检验”一栏时,只需要看与“假设方差相等”对齐的一行(第一行),这一行指出:
检验类型为t,检验统计量值t=-1.807,自由度df=23,(双侧)水平值Sig.=0.084,所以在0.1的显著性水平下可以认为两者有显著差别。
2.某地区汽车拥有量Y和交通事故数X见下表,计算Y和X的相关系数,并进行显著性检验。
说明采用哪种相关系数进行计算,原因?
年份
汽车拥有量Y
交通事故数X
1990
280
9.43
1991
281.5
10.36
1992
337.4
14.5
1993
404.2
15.75
1994
402.1
16.78
1995
452
17.44
1996
431.7
19.77
1997
582.3
23.76
1998
596.6
31.61
1999
620.8
32.17
2000
513.6
35.09
2001
606.9
36.42
2002
629
36.58
2003
602.7
37.14
2004
656.7
41.3
2005
778.5
45.62
2006
877.6
47.38
步骤:
(1)将数据导入SPSS,如下:
(2)完成之后选择分析—相关性—双变量,如下图所示,之后弹出相关性分析主对话框,导入变量,并设置相关参数。
参数设置时,“相关系数”一栏有三个可以选择,区别如下:
Pearson:
皮尔逊相关,计算连续变量或是等间距测度的变量间的相关分析;
Kendall:
肯德尔相关,计算等级变量间的秩相关;
Spearman:
斯皮尔曼相关,计算斯皮尔曼秩相关。
注意一下几点:
a、对于非等间距测度的连续变量,因为分布不明,可以使用等级相关分析,也可以使用Pearson相关分析;
b、对于完全等级的离散变量,必须使用等级相关分析相关性,当数据资料不服从双变量正态分布或总体分布型未知,或原始数据是用等级表示时,宜用Spearman或Kendall相关分析。
本题目所给数据为等间距测度的变量,故选用Pearson。
对于显著性检验一栏,由于先不知道相关方向(正相关还是负相关),则可以选择双侧检验。
结果:
结果分析:
显著性(双侧)=.000,说明在0.01水平上Y与X显著相关。
Pearson相关系数为0.948。
实验作业三
一、以上为我国1952年-1995年国民收入情况,试依据上表建立国民收入预测方程。
(1)首先定义变量,将年份定义为变量X1,收入定义为变量X2,然后输入相关数据。
(2)建立预测方程之前先要进行回归分析,在回归分析之前,有必要绘制散点图,以便于帮助分析预测。
步骤:
a.将所有数据导入SPSS,如下图:
b.散点图,过程和结果如下:
结果可以看出,1952-1977年和1978-1995年两个阶段分别有一定的线性关系,所以分别对这两个阶段进行回归分析。
c.回归分析过程:
d.结果:
模型汇总
模型
R
R方
调整R方
标准估计的误差
1
.927a
.860
.854
214.31619
a.预测变量:
(常量),X。
Anovab
模型
平方和
df
均方
F
Sig.
1
回归
6747125.263
1
6747125.263
146.896
.000a
残差
1102354.324
24
45931.430
总计
7849479.587
25
a.预测变量:
(常量),X。
b.因变量:
Y
系数a
模型
非标准化系数
标准系数
t
Sig.
B
标准误差
试用版
1
(常量)
401.739
86.547
4.642
.000
X
67.922
5.604
.927
12.120
.000
a.因变量:
Y
结果分析:
回归方程:
通过参数显著性检验。
同样的方法得出1978-1995年的回归分析结果如下:
模型汇总
模型
R
R方
调整R方
标准估计的误差
1
.971a
.943
.940
1071.12838
a.预测变量:
(常量),X。
Anovab
模型
平方和
df
均方
F
Sig.
1
回归
3.054E8
1
3.054E8
266.170
.000a
残差
18357056.151
16
1147316.009
总计
3.237E8
17
a.预测变量:
(常量),X。
b.因变量:
Y
系数a
模型
非标准化系数
标准系数
t
Sig.
B
标准误差
试用版
1
(常量)
1190.017
526.740
2.259
.038
X
793.915
48.663
.971
16.315
.000
a.因变量:
Y
结果分析:
回归方程:
通过参数显著性检验。
二、以下为我国历年人均生活收入和生活支出情况。
建立两变量关系模型。
步骤:
(1)将数据输入SPSS,如下:
(2)做散点图,步骤见上题,结果如下:
从上面的散点图可以看出,人均生活费支出先是随着人均生活费收入的提高而快速提高,但当收入达到一定水平后。
生活费支出的增幅明显趋缓。
因此,用线性回归模型表示Y和X的关系是不恰当的。
(3)对Y和X取自然对数
和
,作出散点图,操作和结果如下(只写出转化变量步骤,作图步骤为给出):
结果:
可以看出,
和
在散点图上近似为线性关系。
于是把回归模型确定为幂函数模型:
并进行双对数变换,得:
分别令
,得到先行方程;
(4)回归分析,操作步骤见上题,结果如下:
模型汇总
模型
R
R方
调整R方
标准估计的误差
1
.987a
.973
.971
.09016
a.预测变量:
(常量),lnx。
Anovab
模型
平方和
df
均方
F
Sig.
1
回归
4.144
1
4.144
509.847
.000a
残差
.114
14
.008
总计
4.258
15
a.预测变量:
(常量),lnx。
b.因变量:
lny
系数a
模型
非标准化系数
标准系数
t
Sig.
B
标准误差
试用版
1
(常量)
2.006
.283
7.098
.000
lnx
.748
.033
.987
22.580
.000
a.因变量:
lny
结果如下:
回归方程:
模型通过参数显著性检验。
三、某种商品的需求量Y,价格X1和消费者收入X2的统计资料如下,建立Y和X1,X2变量之间的模型。
步骤:
(1)将数据导入SPSS,如下:
(2)按如下操作:
(3)结果及分析:
模型汇总
模型
R
R方
调整R方
标准估计的误差
1
.950a
.902
.874
1738.98462
a.预测变量:
(常量),X2,X1。
Anovab
模型
平方和
df
均方
F
Sig.
1
回归
1.953E8
2
97659468.712
32.294
.000a
残差
21168472.576
7
3024067.511
总计
2.165E8
9
a.预测变量:
(常量),X2,X1。
b.因变量:
Y
系数a
模型
非标准化系数
标准系数
t
Sig.
B
标准误差
试用版
1
(常量)
62650.928
4013.010
15.612
.000
X1
-979.057
319.784
-1.381
-3.062
.018
X2
.286
.058
2.211
4.902
.002
a.因变量:
Y
可得回归方程:
Sig.<0.05,模型通过参数显著性检验。
实验作业四
附表为国家统计局获取的2011年全国各省市各行业工资水平统计表。
试分析:
(1)应用描述统计分析方法,判断哪些行业平均工资水平较高。
(2)应用聚类分析方法,判断哪些地区平均工资水平较高。
一、1)首先根据要求定义变量,将2011年的各个行业分别定义为X1、X2…X19,然后输入相应的数据
2)数据输入完成之后,菜单选择分析—描述统计—描述,如下图所示
3)弹出描述统计对话框之后将定义的行业变量全部导入变量框中,如下图所示
4)单击选项,选择需要描述的选项,选择均值,并要求按均值降序排序,如下图所示,单击继续,然后点击确定,开始分析
5)得到分析结果如下表:
描述统计量
N
均值
金融业
31
63832.23
信息传输、计算机服务和软件业
31
50326.61
电力、燃气及水的生产和供应业
31
49008.81
科学研究、技术服务和地质勘查业
31
47485.29
采矿业
31
41663.35
教育
31
40532.19
公共管理和社会组织
31
39905.74
卫生、社会保障和社会福利业
31
39451.74
交通运输、仓储和邮政业
31
38884.26
文化、体育和娱乐业
31
37240.00
房地产业
31
31009.58
制造业
31
30516.26
批发和零售业
31
30239.29
租赁和商务服务业
31
29283.03
建筑业
31
28797.16
居民服务和其他服务业
31
27041.13
水利、环境和公共设施管理业
31
25516.94
住宿和餐饮业
31
20868.55
农、林、牧、渔业
31
20568.32
有效的N(列表状态)
31
从表中可以得到平均工资水平较高的行业,这些行业依次为金融业,信息传输、计算机服务和软件业,电力、燃气及水都生产和供应业,科学研究、技术服务业和地质勘查业等
二、聚类分析步骤:
(1)按以下所示进行操作:
(2)得出聚类分析树形图如下:
从上表可以看出聚类情况,可分为三类,则分类如下:
贵州、云南、广西、江西、湖南、吉林、安徽、河南、黑龙江、河北、山西、甘肃、内蒙古、青海、湖北、四川、陕西、辽宁、山东、新疆、福建、重庆、海南、宁夏
江苏、广东、西藏、浙江、天津
北京、上海
结合上图可知,北京、上海平均工资水平最高,其次是天津、浙江、西藏、广东、江苏,最后是其它的省市。


- 配套讲稿:
如PPT文件的首页显示word图标,表示该PPT已包含配套word讲稿。双击word图标可打开word文档。
- 特殊限制:
部分文档作品中含有的国旗、国徽等图片,仅作为作品整体效果示例展示,禁止商用。设计者仅对作品中独创性部分享有著作权。
- 关 键 词:
- SPSS 作业
 冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 《城市规划基本知识》深刻复习要点.docx
《城市规划基本知识》深刻复习要点.docx
-
《高电压技术》word版.docx
-
《安全带》gb6095.docx
-
BCP计划应急计划.docx
-
《计算机组成与工作原理》第一章复习题.docx
-
CANON LBP系列激光打印机使用方法指南.docx
-
C语言课程设计火车票系统源代码.docx
-
3热力管道沟槽开挖方法.docx
-
HR岗位职责.docx
-
1 脱硫脱硝cems维护技术规范.docx
-
O2O超市商业项目计划书.docx
-
SCI期刊呼吸胸外.docx
-
18岁生日祝福语短信.docx
-
ITMC物流企业经营沙盘比赛规则.docx
-
XX钢绳成本管理.docx
-
Matlab的第三方工具箱大全强烈推荐.docx
-
安全保卫工作先进个人.docx
-
安全生产工作日记.docx
-
windows 漏洞集合.docx
-
Φ160数控落地镗铣床技术规格.docx
-
安全施工组织设计.docx
-
安全检查和隐患排查治理制度及记录.docx
-
部编版小学二年级语文下册课外阅读专项.docx
-
变电站投运前质量监督检查汇报材料模版.docx
-
版 创新设计 高考总复习 历史 北师大版第一部分 必考内容第十五单元 第38讲.docx
-
本科毕业设计论文.docx
-
北京大学社会心理学串讲笔记1一10章加试题.docx
-
亳州市教坛新星骨干教师学科带头人特级教师年度考核细则知识分享.docx
-
超星尔雅《人生与人心》期末考试满分答案.docx
-
财经法规与会计职业道德案例分析题.docx
-
茶文化会发言稿.docx
-
财务会计核算实习总结.docx
-
届初三中考英语压轴题强化训练卷书面表达.docx
-
届高考政治一轮复习精品教案11文化与社会必修3.docx
-
届明德达材热身考试文综卷.docx
-
届一轮复习苏教版 有机化学基础 作业 1.docx
-
紧急避险制度新7.docx
-
经典宋词赏析大全.docx
-
精华平安年度工作总结4篇.docx
-
精品推荐完整版互联网+精品云计算众筹融资商业计划书云计算建设方案.docx
-
精通溶液1.docx
-
精选江苏省苏州市工业园区第十中学学年八年级物理上学期期中试题 新人教版物理知识点总结.docx
-
景区管理.docx
-
建设工程招投标教案.docx
-
建筑监理工程师考试试题含答案cad.docx
-
剑桥国际少儿英语笔记.docx
-
江苏马坝高级中学高三上学期期中考试英语试题含答案.docx
-
江苏省无锡市1415学年度高一上学期期末英语英语.docx
-
江西省宜春市高三第二次模拟考试地理试题 Word版含答案.docx
-
交通局局长述职述廉报告多篇范文.docx
-
教科版为什么一年有四季优秀教案3.docx
