 编译原理词法语法分析等实验1.docx
编译原理词法语法分析等实验1.docx
- 文档编号:11329431
- 上传时间:2023-02-27
- 格式:DOCX
- 页数:29
- 大小:167.03KB
编译原理词法语法分析等实验1.docx
《编译原理词法语法分析等实验1.docx》由会员分享,可在线阅读,更多相关《编译原理词法语法分析等实验1.docx(29页珍藏版)》请在冰豆网上搜索。
编译原理词法语法分析等实验1
实验一:
熟悉C语言的运行环境
1.实验目的
1.1、熟悉利用VisualC++6.0编辑运行C程序的方法和步骤。
1.2、运行调试简单的C语言程序。
2、实验方法及步骤
2.1、熟悉利用VisualC++6.0编辑运行C程序的方法和步骤:
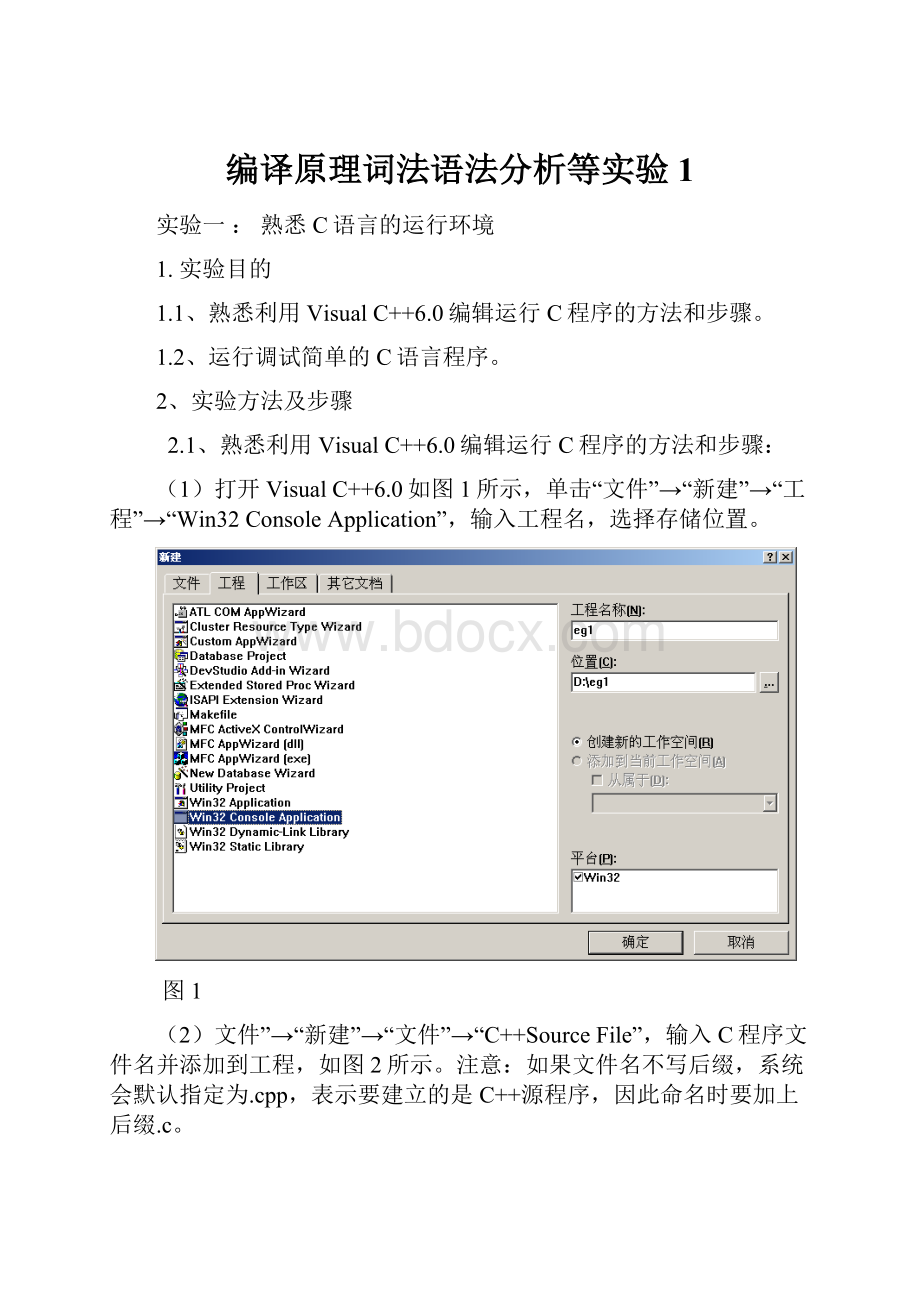
(1)打开VisualC++6.0如图1所示,单击“文件”→“新建”→“工程”→“Win32ConsoleApplication”,输入工程名,选择存储位置。
图1
(2)文件”→“新建”→“文件”→“C++SourceFile”,输入C程序文件名并添加到工程,如图2所示。
注意:
如果文件名不写后缀,系统会默认指定为.cpp,表示要建立的是C++源程序,因此命名时要加上后缀.c。
图2
(3)编写程序代码,如图3所示。
图3
(4)点击菜单栏中“组建”菜单下的“编译”、“组建”、“执行”按钮,运行程序。
如果在编译、组建、执行过程中出现错误,修改程序后重新运行“编译”、“组建”和“执行”过程。
(5)根据需要输入、输出数据。
(6)点击“文件”→“关闭”。
2.2、输入并调试下列程序,熟悉C语言程序的调试过程,程序如下:
#include
voidmain()
﹛doublea,b,area;
a=1.2;
b=3.6;
area=a*b;
printf(“a=%f,b=%f,area=%f\n”,a,b,area);
﹜
执行以上程序后的输出结果为:
a=1.200000,b=3.600000,area=4.320000
三、输入并调试下列程序,理解为什么会出现这样的结果。
#include
main()
{charch1,ch2,ch;
unsignedcharc;
inta;
ch1=78;
ch2=67;
ch=ch1+ch2;
c=ch1+ch2;
a=ch1+ch2;
printf(“ch1+ch2=%d\n”,ch1+ch2);
printf(“ch=%d\n”,ch);
printf(“c=%d\n”,c);
printf(“a=%d\n”,a);
}
运行结果:
结果分析:
运行结果中ch=-111原因是因为ch定义为char型,所以其值不能大于128,而ch1+ch2=145,145大于128,即ch=ch1+ch2溢出。
3.实验总结
由以上程序运行结果可知,在编写程序代码时,一定要定义函数类型和变量,变量类型的定义要确保在可执行的范围内。
实验二词法分析器
1.实验目的及要求
本次实验通过用C语言设计、编制、调试一个词法分析子程序,识别单词,实现一个C语言词法分析器,经过此过程可以加深对编译器解析单词流的过程的了解。
运行环境:
硬件:
windowsxp
软件:
visualc++6.0
2.实验步骤
1.查询资料,了解词法分析器的工作过程与原理。
2.分析题目,整理出基本设计思路。
3.实践编码,将设计思想转换用c语言编码实现,编译运行。
4.测试功能,多次设置包含不同字符,关键字的待解析文件,仔细察看运行结果,检测该分析器的分析结果是否正确。
通过最终的测试发现问题,逐渐完善代码中设置的分析对象与关键字表,拓宽分析范围提高分析能力。
3.实验内容
本实验中将c语言单词符号分成了四类:
关键字key(特别的将main说明为主函数)、普通标示符、常数和界符。
将关键字初始化在一个字符型指针数组*key[]中,将界符分别由程序中的case列出。
在词法分析过程中,关键字表和case列出的界符的内容是固定不变的(由程序中的初始化确定),因此,从源文件字符串中识别出现的关键字,界符只能从其中选取。
标识符、常数是在分析过程中不断形成的。
对于一个具体源程序而言,在扫描字符串时识别出一个单词,若这个单词的类型是关键字、普通标示符、常数或界符中之一,那么就将此单词以文字说明的形式输出.每次调用词法分析程序,它均能自动继续扫描下去,形成下一个单词,直到整个源程序全部扫描完毕,从而形成相应的单词串。
输出形式例如:
void$关键字
源程序代码:
#include
#include
#include
#include
//定义关键字
char*Key[10]={"main","void","int","char","printf","scanf","else","if","return"};
charWord[20],ch;//存储识别出的单词流
intIsAlpha(charc){//判断是否为字母
if(((c<='z')&&(c>='a'))||((c<='Z')&&(c>='A')))return1;
elsereturn0;
}
intIsNum(charc){//判断是否为数字
if(c>='0'&&c<='9')return1;
elsereturn0;
}
intIsKey(char*Word){//识别关键字函数
intm,i;
for(i=0;i<9;i++){
if((m=strcmp(Word,Key[i]))==0)
{
if(i==0)
return2;
return1;
}
}
return0;
}
voidscanner(FILE*fp){//扫描函数
charWord[20]={'\0'};
charch;
inti,c;
ch=fgetc(fp);//获取字符,指针fp并自动指向下一个字符
if(IsAlpha(ch)){//判断该字符是否是字母
Word[0]=ch;
ch=fgetc(fp);
i=1;
while(IsNum(ch)||IsAlpha(ch)){//判断该字符是否是字母或数字
Word[i]=ch;
i++;
ch=fgetc(fp);
}
Word[i]='\0';//'\0'代表字符结束(空格)
fseek(fp,-1,1);//回退一个字符
c=IsKey(Word);//判断是否是关键字
if(c==0)printf("%s\t$普通标识符\n\n",Word);//不是关键字
elseif(c==2)printf("%s\t$主函数\n\n",Word);
elseprintf("%s\t$关键字\n\n",Word);//输出关键字
}
else//开始判断的字符不是字母
if(IsNum(ch)){//判断是否是数字
Word[0]=ch;
ch=fgetc(fp);
i=1;
while(IsNum(ch)){
Word[i]=ch;
i++;
ch=fgetc(fp);
}
Word[i]='\0';
fseek(fp,-1,1);//回退
printf("%s\t$无符号实数\n\n",Word);
}
else//开始判断的字符不是字母也不是数字
{
Word[0]=ch;
switch(ch){
case'[':
case']':
case'(':
case')':
case'{':
case'}':
case',':
case'"':
case';':
printf("%s\t$界符\n\n",Word);break;
case'+':
ch=fgetc(fp);
Word[1]=ch;
if(ch=='='){
printf("%s\t$运算符\n\n",Word);//运算符“+=”
}
elseif(ch=='+'){
printf("%s\t$运算符\n\n",Word);//判断结果为“++”
}
else{
fseek(fp,-1,1);
printf("%s\t$运算符\n\n",Word);//判断结果为“+”
}
break;
case'-':
ch=fgetc(fp);
Word[1]=ch;
if(ch=='='){
printf("%s\t$运算符\n\n",Word);}
elseif(ch=='-'){
printf("%s\t$运算符\n\n",Word);//判断结果为“--”
}
else{
fseek(fp,-1,1);
printf("%s\t$运算符\n\n",Word);//判断结果为“-”
}
break;
case'*':
case'/':
case'!
':
case'=':
ch=fgetc(fp);
if(ch=='='){
printf("%s\t$运算符\n\n",Word);
}
else{
fseek(fp,-1,1);
printf("%s\t$运算符\n\n",Word);
}
break;
case'<':
ch=fgetc(fp);
Word[1]=ch;
if(ch=='='){
printf("%s\t$运算符\n\n",Word);//判断结果为运算符“<=”
}
elseif(ch=='<'){
printf("%s\t$运算符\n\n",Word);//判断结果为“<<”
}
else{
fseek(fp,-1,1);
printf("%s\t$运算符\n\n",Word);//判断结果为“<”
}
break;
case'>':
ch=fgetc(fp);
Word[1]=ch;
if(ch=='=')printf("%s\t$运算符\n\n",Word);
else{
fseek(fp,-1,1);
printf("%s\t$运算符\n\n",Word);
}
break;
case'%':
ch=fgetc(fp);
Word[1]=ch;
if(ch=='='){printf("%s\t$运算符\n\n",Word);}
if(IsAlpha(ch))printf("%s\t$类型标识符\n\n",Word);
else{
fseek(fp,-1,1);
printf("%s\t$取余运算符\n\n",Word);
}
break;
default:
printf("无法识别字符!
\n\n");break;
}
}
}
main()
{
charin_fn[30];//文件路径
FILE*fp;
printf("\n请输入源文件名(包括路径和后缀名):
");
while
(1){
gets(in_fn);
//scanf("%s",in_fn);
if((fp=fopen(in_fn,"r"))!
=NULL)break;//读取文件内容,并返回文件指针,该指针指向文件的第一个字符
elseprintf("文件路径错误!
请重新输入:
");
}
printf("\n*******************词法分析结果如下*******************\n");
do{
ch=fgetc(fp);
if(ch=='#')break;//文件以#结尾,作为扫描结束条件
elseif(ch==''||ch=='\t'||ch=='\n'){}//忽略空格,空白,和换行
else{
fseek(fp,-1,1);//回退一个字节开始识别单词流
scanner(fp);
}
}while(ch!
='#');
return(0);
}
4.实验结果
解析源文件:
voidmain()
{
inta=3;
a+=b;
printf("%d",a);
return;
}
#
解析结果:
5.实验总结:
通过本次实验,让我再次浏览了有关c语言的一些基本知识,特别是对文件,字符串进行基本操作的方法。
C语言中没有string类型,因此本实验中的对字符串提取与识别均借助#include
让我练习对字符串函数应用的同时也提高了自己的逻辑思维能力。
在本次实验中,我纠正了一个一直以来的概念错误:
main不是关键字,它定义为程序的入口,是主函数!
在本实验中,虽然我把main初始化在关键字表
(字符指针类型数组)*Key[10]中,当与该数组中字符串进行比较时,若与main匹配成功,则返回2,若为其他关键字则返回1,以此来把main从关键字中区别出来。
在本实验中的关键字表只初始化了几个常用的关键字,还可继续扩充(只需扩大数组,向其中补充要添加的关键字)。
如果要对本程序中未识别的c语言中的一些其他的字符进行扩充(目前处理为不可识别字符),可在程序代码中继续添加case选项,分别对相应要识别的特殊字符加以描述
实验三微小语言及其文法
一、实验目的
编制一个递归下降分析程序,实现对词法分析程序所提供的单词序列的语法检查和结构分析。
二实验内容
利用C语言编制递归下降分析程序,并对简单语言进行语法分析。
2.1待分析的简单语言的语法
用扩充的BNF表示如下:
⑴<程序>:
:
=begin<语句串>end
⑵<语句串>:
:
=<语句>{;<语句>}
⑶<语句>:
:
=<赋值语句>
⑷<赋值语句>:
:
=ID:
=<表达式>
⑸<表达式>:
:
=<项>{+<项>|-<项>}
⑹<项>:
:
=<因子>{*<因子>|/<因子>
⑺<因子>:
:
=ID|NUM|(<表达式>)
2.2实验要求说明
输入单词串,以“#”结束,如果是文法正确的句子,则输出成功信息,打印“success”,否则输出“error”。
例如:
输入begina:
=9;x:
=2*3;b:
=a+xend#
输出success!
输入x:
=a+b*cend#
输出error
2.3程序的C语言程序源代码:
#include
#include
charprog[100],token[8],ch;
char*rwtab[6]={"begin","if","then","while","do","end"};
intsyn,p,m,n,sum;
intkk;
factor();
expression();
yucu();
term();
statement();
lrparser();
scaner();
main()
{
p=kk=0;
printf("\npleaseinputastring(endwith'#'):
\n");
do
{scanf("%c",&ch);
prog[p++]=ch;
}while(ch!
='#');
p=0;
scaner();
lrparser();
getch();
}
lrparser()
{
if(syn==1)
{
scaner();/*读下一个单词符号*/
yucu();/*调用yucu()函数;*/
if(syn==6)
{scaner();
if((syn==0)&&(kk==0))
printf("success!
\n");
}
else{if(kk!
=1)printf("thestringhaven'tgota'end'!
\n");
kk=1;
}
}
else{printf("haven'tgota'begin'!
\n");
kk=1;
}
return;
}
yucu()
{
statement();/*调用函数statement();*/
while(syn==26)
{
scaner();/*读下一个单词符号*/
if(syn!
=6)
statement();/*调用函数statement();*/
}
return;
}
statement()
{if(syn==10)
{
scaner();/*读下一个单词符号*/
if(syn==18)
{scaner();/*读下一个单词符号*/
expression();/*调用函数statement();*/
}
else{printf("thesing':
='iswrong!
\n");
kk=1;
}
}
else{printf("wrongsentence!
\n");
kk=1;
}
return;
}
expression()
{term();
while((syn==13)||(syn==14))
{scaner();/*读下一个单词符号*/
term();/*调用函数term();*/
}
return;
}
term()
{factor();
while((syn==15)||(syn==16))
{scaner();/*读下一个单词符号*/
factor();/*调用函数factor();*/
}
return;
}
factor()
{if((syn==10)||(syn==11))scaner();
elseif(syn==27)
{scaner();/*读下一个单词符号*/
expression();/*调用函数statement();*/
if(syn==28)
scaner();/*读下一个单词符号*/
else{printf("theerroron'('\n");
kk=1;
}
}
else{printf("theexpressionerror!
\n");
kk=1;
}
return;
}
scaner()
{ sum=0;
for(m=0;m<8;m++)token[m++]=NULL;
m=0;
ch=prog[p++];
while(ch=='')ch=prog[p++];
if(((ch<='z')&&(ch>='a'))||((ch<='Z')&&(ch>='A')))
{while(((ch<='z')&&(ch>='a'))||((ch<='Z')&&(ch>='A'))||((ch>='0')&&(ch<='9')))
{token[m++]=ch;
ch=prog[p++];
}
p--;
syn=10;
token[m++]='\0';
for(n=0;n<6;n++)
if(strcmp(token,rwtab[n])==0)
{syn=n+1;
break;
}
}
elseif((ch>='0')&&(ch<='9'))
{while((ch>='0')&&(ch<='9'))
{sum=sum*10+ch-'0';
ch=prog[p++];
}
p--;
syn=11;
}
elseswitch(ch)
{case'<':
m=0;
ch=prog[p++];
if(ch=='>')
{ syn=21;
}
elseif(ch=='=')
{ syn=22;
}
else
{ syn=20;
p--;
}
break;
case'>':
m=0;
ch=prog[p++];
if(ch=='=')
{syn=24;
}
else
{syn=23;
p--;
}
break;
case':
':
m=0;
ch=prog[p++];
if(ch=='=')
{syn=18;
}
else
{syn=17;
p--;
}
break;
case'+':
syn=13;break;
case'-':
syn=14;break;
case'*':
syn=15;break;
case'/':
syn=16;break;
case'(':
syn=27;break;
case')':
syn=28;break;
case'=':
syn=25;break;
case';':
syn=26;break;
case'#':
syn=0;break;
default:
syn=-1;break;
}
}
结果分析:
输入begina:
=9;x:
=2*3;b:
=a+xend#后输出success!
如图1-1所示:
图1-1
输入x:
=a+b*cend#后输出error如图1-2所示:
图1-2
三、总结:
通过本次试验,了解了语法分析的运行过程,主程序大致流程为:
“置初值”调用scaner函数读下一个单词符


- 配套讲稿:
如PPT文件的首页显示word图标,表示该PPT已包含配套word讲稿。双击word图标可打开word文档。
- 特殊限制:
部分文档作品中含有的国旗、国徽等图片,仅作为作品整体效果示例展示,禁止商用。设计者仅对作品中独创性部分享有著作权。
- 关 键 词:
- 编译 原理 词法 语法分析 实验
 冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 《Java程序设计》考试大纲及样题试行.docx
《Java程序设计》考试大纲及样题试行.docx
-
《工业企业管理》自学任务书.docx
-
《短歌行》原文翻译及赏析.docx
-
《跳水》教案3.docx
-
《基于MATLAB的信号与系统实验指导》编程练习.docx
-
《你是最棒的》教学设计.docx
-
《选修4化学反应原理》知识点总结整理超全.docx
-
2环境应急监测试题资料.docx
-
《自动化仪表工程施工及验收规范》GB50093仪表安装检验批.docx
-
09年法律硕士民法预热辅导第2102讲完整篇doc.docx
-
6阅读能力阅读方法指什么.docx
-
《豆蔻镇的居民和强盗》读后感.docx
-
CMYK色值参考.docx
-
3121护理查对制度.docx
-
《草莓》课堂教学课件5篇.docx
-
CCNA完整知识点.docx
-
《合理安排时间》说课稿.docx
-
18我的伯父鲁迅先生.docx
-
3dmax授课计划doc.docx
-
《中共中央国务院关于加快推进生态文明建设的意见》.docx
-
《永生的眼睛》练习题附答案.docx
-
flow3d官方培训教程中的实例中文说明.docx
-
《宪法》《监察法》应知应会100题含答案.docx
-
EMS基础知识综合练习复习资料.docx
-
100以内退位减法500道带竖式空间可直接打印.docx
-
207声屏障施工组织设计.docx
-
30个科学小常识教学提纲.docx
-
JGJ59建筑施工安全检查标准评分表全套.docx
-
12幼儿园保育员培训活动记录表.docx
-
minecraft匠魂教程.docx
-
c语言课程设计学生成绩管理系统.docx
-
0503新闻传播学基本要求.docx
-
天津高考英语试题及答案.docx
-
文化生活思维导图.docx
-
调动学生学习积极性总帖.docx
-
我爱我的班级作文600字.docx
-
我身边的优秀党员演讲稿七篇.docx
-
停车场建设行业发展状况.docx
-
屋面风机设备吊装桅杆吊装专项施工方案要点.docx
-
五年级国旗下演讲稿.docx
-
五篇主管药师述职报告1000字范文.docx
-
物联网解决方案物联网在教育中的应用与思考.docx
-
西安交通大学电子线路设计实验报告.docx
-
西峡第一高级中学信息化建设改造清单中控室.docx
-
下班温馨问候语.docx
-
现代教育技术学考试重点概述.docx
-
乡医培训实施方案.docx
-
网络设备技术规范标准.docx
-
危险化学品生产企业安全生产许可证实施办法国家安监总局41号令.docx
-
微信小程序项目实施计划书.docx
-
未来的学校想象作文600字700字.docx
