 福州大学人工智能作业.docx
福州大学人工智能作业.docx
- 文档编号:10606329
- 上传时间:2023-02-21
- 格式:DOCX
- 页数:37
- 大小:905.09KB
福州大学人工智能作业.docx
《福州大学人工智能作业.docx》由会员分享,可在线阅读,更多相关《福州大学人工智能作业.docx(37页珍藏版)》请在冰豆网上搜索。
福州大学人工智能作业
人工智能
姓名:
陈超学号:
150120001专业:
电机与电器
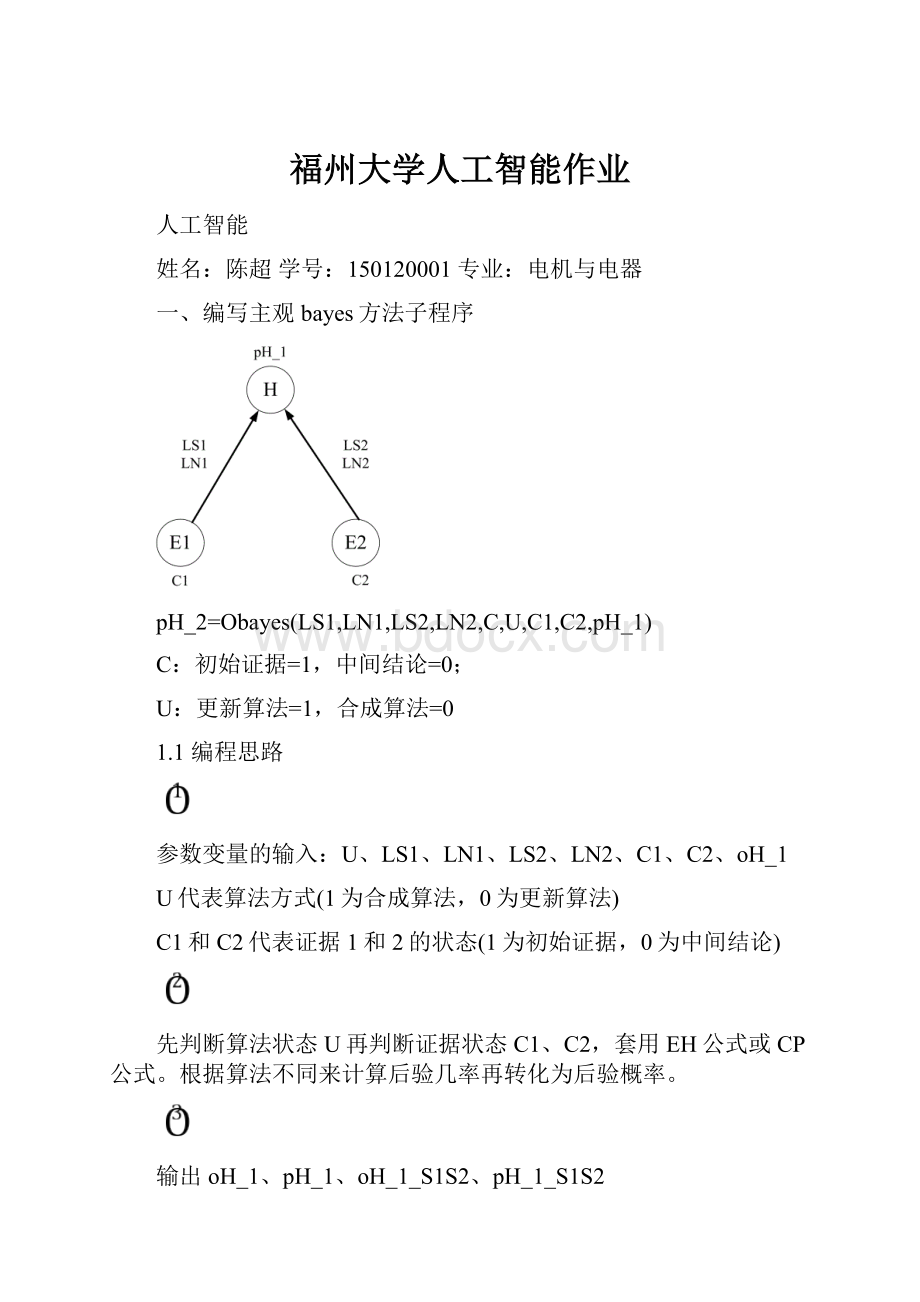
一、编写主观bayes方法子程序
pH_2=Obayes(LS1,LN1,LS2,LN2,C,U,C1,C2,pH_1)
C:
初始证据=1,中间结论=0;
U:
更新算法=1,合成算法=0
1.1编程思路
参数变量的输入:
U、LS1、LN1、LS2、LN2、C1、C2、oH_1
U代表算法方式(1为合成算法,0为更新算法)
C1和C2代表证据1和2的状态(1为初始证据,0为中间结论)
先判断算法状态U再判断证据状态C1、C2,套用EH公式或CP公式。
根据算法不同来计算后验几率再转化为后验概率。
输出oH_1、pH_1、oH_1_S1S2、pH_1_S1S2
1.2计算结果(以ppt上例题为例)
把题目中的网络分成两步来计算。
合成算法的结果如下
更新算法的结果如下:
1.3算法程序:
function[]=Obayes
U=input('请选择算法(1为合成算法,0为更新算法):
');
LS1=input('请输入E1的充分性度量:
');
LN1=input('请输入E2的必要性度量:
');
LS2=input('请输入E2的充分性度量:
');
LN2=input('请输入E2的必要性度量:
');
C1=input('请输入证据E1的状态(1为初始证据,0为中间结论):
');
C2=input('请输入证据E2的状态(1为初始证据,0为中间结论):
');
oH_1=input('请输入H的先验几率:
');
pH_1=(oH_1/(1+oH_1));
ifU==1%合成算法
pH_1_E1=((LS1*oH_1)/(1+LS1*oH_1));
pH_1_FE1=((LN1*oH_1)/(1+LN1*oH_1));
pH_1_E2=((LS2*oH_1)/(1+LS2*oH_1));
pH_1_FE2=((LN2*oH_1)/(1+LN2*oH_1));
ifC1==1%初始证据CP公式
S1=input('请输入E1的可信度:
');
ifS1>0
pH_1_S1=(pH_1+(pH_1_E1-pH_1)/5*S1);
else
pH_1_S1=(pH_1_FE1+(pH_1-pH_1_FE1)*(S1/5+1));
end
else%中间结论EH公式
pE1=input('请输入E1的先验概率:
');
pE1_S1=input('请输入E1的后验概率:
');
ifpE1_S1>=pE1
pH_1_S1=(pH_1+(pH_1_E1-pH_1)/(1-pE1)*(pE1_S1-pE1));
else
pH_1_S1=(pH_1_FE1+(pH_1-pH_1_FE1)/(pE1)*(pE1_S1));
end
end
ifC2==1
S2=input('请输入E2的可信度:
');
ifS2>0
pH_1_S2=(pH_1+(pH_1_E2-pH_1)/5*S2);
else
pH_1_S2=(pH_1_FE2+(pH_1-pH_1_FE2)*(S2/5+1));
end
else
pE2=input('请输入E2的先验概率:
');
pE2_S2=input('请输入E2的后验概率:
');
ifpE2_S2>=pE2
pH_1_S2=(pH_1+(pH_1_E2-pH_1)/(1-pE2)*(pE2_S2-pE2));
else
pH_1_S2=(pH_1_FE2+(pH_1-pH_1_FE2)/(pE2)*(pE2_S2));
end
end
oH_1_S1=((pH_1_S1)/(1-pH_1_S1));
oH_1_S2=((pH_1_S2)/(1-pH_1_S2));
oH_2=((oH_1_S1/oH_1)*(oH_1_S2/oH_1)*oH_1);
pH_2=(oH_2/(1+oH_2));
fprintf('H的先验几率=%f\n',oH_1)
fprintf('H的先验概率=%f\n',pH_1)
fprintf('H的后验几率=%f\n',oH_2)
fprintf('H的后验概率=%f\n',pH_2)
elseifU==0%更新算法¨
pH_1_E1=((LS1*oH_1)/(1+LS1*oH_1));
pH_1_FE1=((LN1*oH_1)/(1+LN1*oH_1));
ifC1==1
S1=input('请输入E1的可信度:
');
ifS1>0
pH_1_S1=(pH_1+(pH_1_E1-pH_1)/5*S1);
else
pH_1_S1=(pH_1_FE1+(pH_1-pH_1_FE1)*(S1/5+1));
end
else
pE1=input('请输入E1的先验概率:
');
pE1_S1=input('请输入E1的后验概率:
');
ifpE1_S1>=pE1
pH_1_S1=(pH_1+(pH_1_E1-pH_1)/(1-pE1)*(pE1_S1-pE1));
else
pH_1_S1=(pH_1_FE1+(pH_1-pH_1_FE1)/(pE1)*(pE1_S1));
end
end
oH_1_S1=((pH_1_S1)/(1-pH_1_S1));
pH_1_S1_E2=((LS2*oH_1_S1)/(1+LS2*oH_1_S1));
pH_1_S1_FE2=((LN2*oH_1_S1)/(1+LN2*oH_1_S1));
ifC2==1
S2=input('请输入E2的可信度:
');
ifS2>0
pH_1_S1S2=(pH_1_S1+(pH_1_S1_E2-pH_1_S1)/5*S2);
else
pH_1_S1S2=(pH_1_S1_FE2+(pH_1_S1-pH_1_S1_FE2)*(S2/5+1));
end
else
pE2=input('请输入E2的先验概率:
');
pE2_S2=input('请输入E2的后验概率:
');
ifpE2_S2>=pE2
pH_1_S1S2=(pH_1_S1+(pH_1_S1_E2-pH_1_S1)/(1-pE2)*(pE2_S2-pE2));
else
pH_1_S1S2=(pH_1_S1_FE2+(pH_1_S1-pH_1_S1_FE2)/(pE2)*(pE2_S2));
end
end
oH_1_S1S2=((pH_1_S1S2)/(1-pH_1_S1S2));
fprintf('H的先验几率=%f\n',oH_1)
fprintf('H的先验概率=%f\n',pH_1)
fprintf('H的后验几率=%f\n',oH_1_S1S2)
fprintf('H的后验概率=%f\n',pH_1_S1S2)
end
end
二、分别编写遗传算法和粒子群算法程序完成Camel函数寻优
Camel函数描述为:
该函数有六个局部极小点,其中(-0.0898,0.7126)和(0.0898,0.7126)为全局最小点,最小值为-1.031628。
本题题目有误:
第一项
为
的偶次幂故取正负无影响,第三项
同理。
但是对于第二项
当
取-0.0898和0.0898时算出的
不可能一样。
故这题结论是错误的,全局最小点为(-0.0898,0.7126)。
A.遗传算法
A.2.1编程思路
对种群进行初始化,解码并且计算目标值和适应度。
比例运算,交叉运算,变异运算
生成新的种群并且输出目标值。
A.2.2计算结果
上图为一次计算结果,可以看出基本接近于题目中的结论。
算法测试结果:
由于时间有限,一共做了100次测试得出结果是:
最大与最小的差值仅仅只有0.003的差值,可见算法的精度还是比较高的。
A.2.3问题与思考
由于自己编写的GA算法一直在目标函数与适应度函数的转化上出现错误导致无法得出正常结果,故在参照同学的程序上进行了进一步的修改得到下面的算法程序。
但是同时也有一些问题无法得到理解与解决。
1、程序中并没有对适应度进行非负的转化
2、由于负数的适应度存在导致在比例选择中总的适应度降低,从而进一步导致正数的适应度间接增大,而负数的适应度丢失。
3、即使存在上述两点的问题,算法的结果依然是接近于正确,导致本人对此感到匪夷所思,然而时间和能力的有限使得本人并没有进一步研究与探讨。
A.2.4算法程序
function[]=GA
clearall
closeall
%参数
Size=150;
G=300;
L=10;
xmax=3;
xmin=-3;
ymax=2;
ymin=-2;
pc=0.60;
pm=0.01;
%初始化
E=round(rand(Size,2*L));
%主程序
fork=1:
1:
G
time(k)=k;
fors=1:
1:
Size
m=E(s,:
);
t1=0;
t2=0;
%解码
m1=m(1:
1:
L);
fori=1:
1:
L
t1=t1+m1(i)*2^(i-1);
end
x(s)=(xmax-xmin)*t1/(2^L-1)+xmin;
m2=m(L+1:
1:
2*L);
fori=1:
1:
L
t2=t2+m2(i)*2^(i-1);
end
y(s)=(ymax-ymin)*t2/(2^L-1)+ymin;
F(s)=(4-2.1*x(s)^2+x(s)^4/3)*x(s)^2+x(s)*y(s)+(-4+4*y(s)^2)*y(s)^2;
end
%从大到小排序
fi=F;
[Oderfi,Indexfi]=sort(fi,'descend');
Bestfi=Oderfi(Size);
BestS=E(Indexfi(Size),:
);
BestX=x(Indexfi(Size));
BestY=y(Indexfi(Size));
bfi(k)=Bestfi;
%比例选择法
fi_sum=sum(fi);
fi_Size=(Oderfi/fi_sum)*Size;
fi_S=floor(fi_Size);
kk=1;
fori=1:
1:
Size
forj=1:
1:
fi_S(i)
TempE(kk,:
)=E(Indexfi(i),:
);
kk=kk+1;
end
end
%交叉运算
n=ceil(20*rand);
fori=1:
2:
(Size-1)
temp=rand;
ifpc>=temp
forj=n:
1:
20
TempE(i,j)=E(i+1,j);
TempE(i+1,j)=E(i,j);
end
end
end
TempE(Size,:
)=BestS;%保留优秀个体
E=TempE;
%变异运算
fori=1:
1:
Size
forj=1:
1:
2*L
temp=rand;
ifpm>=temp
ifTempE(i,j)==0
TempE(i,j)=1;
else
TempE(i,j)=0;
end
end
end
end
%新种群
TempE(Size,:
)=BestS;
E=TempE;
end
Min_Value=Bestfi;
fprintf('最小值=%f\n',Min_Value)
fprintf('X=%f\n',BestX)
fprintf('Y=%f\n',BestY)
figure
(1);
plot(time,bfi);
xlabel('times');ylabel('BestF');
end
B.粒子群算法
B.2.1编程思路
参数、种群初始化
计算各个粒子的适应度,初始化全局最优跟个体最优。
学习因子更新、速度更新、种群更新、适应度更新、最优更新
输出结果
B.2.2计算结果
函数最小值=-1.030325
x=-0.085016;y=0.700078
B.2.3算法测试
上图为200次粒子群算法测试,可以看出最大最小之间误差大约为0.03,并且出现最大误差的次数大约为3%,可见算法可靠性还算可以。
B.2.4算法程序
function[]=Pso
%输入变量
N=2;%('解空间的维度=');
M=20;
G=300;
c1max=2.5;
c1min=0.5;
c2max=2.5;
c2min=0.5;
%初始化种群
fori=1:
M
pop(i,1)=3*rands(1,1);%1行一列[-33]的随机数
pop(i,2)=2*rands(1,1);
V(i,:
)=rand(1,2);
end
%计算各个粒子的适应度,并初始化pbest跟gbest
fori=1:
M
fitness(i)=((4-2.1*(pop(i,1)^2)+(pop(i,1)^4)/3)*((pop(i,1)^2)))+((pop(i,1)*pop(i,2)))+((-4+4*(pop(i,2)^2))*(pop(i,2)^2));
end
[bestfitnessbestindex]=min(fitness);%min返回两个值第一个为最小值,第二个为最小值位置
zbest=pop(bestindex,:
);%全局最佳
gbest=pop;%个体最佳
fitnessgbest=fitness;%个体最佳适应度值
fitnesszbest=bestfitness;%全局最佳适应度值
%迭代寻优
fori=1:
1:
G
%学习因子更新
c1=c1max-(c1max-c1min)*i/G;
c2=c2min+(c2max-c2min)*i/G;
forj=1:
1:
M
V(j,:
)=V(j,:
)+c1*rand*(gbest(j,:
)-pop(j,:
))+c2*rand*(zbest-pop(j,:
));%速度更新
pop(j,:
)=pop(j,:
)+V(j,:
);%种群更新
fitness(j)=((4-2.1*(pop(j,1)^2)+(pop(j,1)^4)/3)*((pop(j,1)^2)))+((pop(j,1)*pop(j,2)))+((-4+4*(pop(j,2)^2))*(pop(j,2)^2));%适应度更新
end
forj=1:
1:
M
iffitness(j) gbest(j,: )=pop(j,: ); fitnessgbest(j)=fitness(j); end iffitness(j) zbest=pop(j,: ); fitnesszbest=fitness(j); end end G_best(i)=fitnesszbest; end fprintf('函数最小值=%f\n',fitnesszbest) fprintf('x=%f\n',zbest (1)) fprintf('y=%f\n',zbest (2)) end 三、编写蚁群算法程序完成31个城市的TSP问题寻优 31个城市 坐标为: [13042312;36391315;41772244;37121399;34881535;33261556;32381229;41961004;4312790;4386570;30071970;25621756;27881491;23811676;1332695;37151678;39182179;40612370;37802212;36762578;40292838;42632931;34291908;35072367;33942643;34393201;29353240;31403550;25452357;27782826;23702975] 3.1编程思路 初始化: 计算距离矩阵,蚂蚁位置初始化 选择城市: 计算选择概率,转盘选择,更新禁忌表 计算路径长度,记录本次迭代最佳路线 更新信息素,禁忌表清空 输出结果,绘制路线图 3.2计算结果 最短距离=16038.794579 最佳路径为: 15-14-12-13-11-23-16-5-6-7-2-4-8-9-10-17-3-18-21-22-19 -24-20-25-26-28-27-30-31-29-1-15 3.3算法程序 function[]=Aco clearall %输入变量 C=[1304,2312;3639,1315;4177,2244;3712,1399;3488,1535;3326,1556;3238,1229;4196,1004;4312,790;4386,570;3007,1970;2562,1756;2788,1491;2381,1676;1332,695;3715,1678;3918,2179;4061,2370;3780,2212;3676,2578;4029,2838;4263,2931;3429,1908;3507,2367;3394,2643;3439,3201;2935,3240;3140,3550;2545,2357;2778,2826;2370,2975];%C为坐标,n乘2矩阵 m=20;%蚂蚁个数约等于(城市个数/1.5) NC_max=200;%最大迭代次数 A=1;%信息素重要程度 B=5;%启发因子重要程度 Q=10;%信息素增强强度系数 R=0.7;%信息素蒸发系数 %初始化变量 n=size(C,1);%n为城市的数量1表示行数 D=zeros(n,n);%D为邻接矩阵 fori=1: n forj=1: n ifi~=j D(i,j)=(((C(i,1)-C(j,1))^2+(C(i,2)-C(j,2))^2)^0.5);%两两城市间的距离 else D(i,j)=eps;%防止启发因子分母为0 end D(j,i)=D(i,j); end end E=1./D;%E为启发因子,距离的倒数 T=ones(n,n);%T为信息素矩阵 Tabu=zeros(m,n);%Tabu为禁忌表 NC=1;%迭代计数器 road_best=zeros(NC_max,n); length_best=inf.*ones(NC_max,1); length_avg=zeros(NC_max,1); whileNC<=NC_max %把m只蚂蚁放在n个城市上 Randpos=[]; i_c=ceil(m/n); ifi_c==1 Randpos=[Randpos,randsample(randperm(n),m)]; else fori=1: 1: (i_c-1) Randpos=[Randpos,randperm(n)]; end Randpos=[Randpos,randsample(randperm(n),(n-(n*(i_c-1))))]; end Tabu(: 1)=(Randpos(1,1: m))';%将蚂蚁的起始城市加入禁忌表的第一列 %m只蚂蚁选择城市 forj=2: n%旅游次数 fori=1: m%蚂蚁数量 visited=Tabu(i,1: (j-1));%记录已访问的城市 J=zeros(1,(n-j+1));%待访问的城市 P=J;%待访问城市的选择概率 Jc=1; sum_p=0; fork=1: n iflength(find(visited==k))==0%开始时置0 J(Jc)=k; Jc=Jc+1; end end fork=1: length(J) p(k)=((T(visited(end),J(k))^A)*(E(visited(end),J(k))^B)); sum_p=(sum_p+p(k)); end fork=1: length(J) P(k)=p(k)/sum_p; end Pcum=cumsum(P);%元素累加求和 select=find(Pcum>=rand); to_visit=J(select (1)); Tabu(i,j)=to_visit; end end ifNC>=2 Tabu(1,: )=road_best(NC-1,: ); end %记录本次迭代最佳路线 L=zeros(m,1); fori=1: m road=Tabu(i,: ); forj=1: (n-1) L(i)=L(i)+D(road(j),road(j+1)); end L(i)=L(i)+D(road (1),road(n)); end length_best(NC)=min(L); pos=find(L==length_best(NC)); road_best(NC,: )=Tabu(pos (1),: ); length_avg(NC)=mean(L);%mean为求数组平均值 NC=NC+1; %更新信息素 Delta_T=zeros(n,n);%信息素变化量 fori=1: m forj=1: (n-1) Delta_T(Tabu(i,j),Tabu(i,j+1))=Delta_T(Tabu(i,j),Tabu(i,j+1))+Q/L(i); end Delta_T(Tabu(i,n),Tabu(i,1))=Delta_T(Tabu(i,n),Tabu(i,1))+Q/L(i); end T=(1-R).*T+R.*Delta_T; %禁忌表清空 Tabu=zeros(m,n); end %输出结果 Pos=find(length_best==min(length_best)); R_best=road_best(Pos (1),: ); L_best=length_best(Pos (1)); fprintf('最短距离=%f\n',L_best) fprintf('最佳路径为') fori=1: n fprintf('%d-',R_best(i)) end fprintf('%d\n',R_best (1)) subplot(1,2,1) %路线图绘制 N=length(R_best); scatter(C(: 1),C(: 2)); holdon plot([C(R_best (1),1),C(R_best(N),1)],[C(R_best (1),2)


- 配套讲稿:
如PPT文件的首页显示word图标,表示该PPT已包含配套word讲稿。双击word图标可打开word文档。
- 特殊限制:
部分文档作品中含有的国旗、国徽等图片,仅作为作品整体效果示例展示,禁止商用。设计者仅对作品中独创性部分享有著作权。
- 关 键 词:
- 福州大学 人工智能 作业
 冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 1212中级汽车维修工考试试题三.docx
1212中级汽车维修工考试试题三.docx
-
333教育综合.docx
-
204届毕业生基础知识考试试题 混凝土结构设计 试题.docx
-
100以内加减运算练习题.docx
-
101软件开发工程师JAVA初级考试样卷课件word版本.docx
-
CNN代码理解.docx
-
CPA审计第4章审计抽样下载版讲解.docx
-
hr培训管理系统.docx
-
318安通科科长岗位责任制.docx
-
2044施工现场环境污染的防治措施.docx
-
12371党务平台操作手册.docx
-
Catia百格线生成宏复习过程.docx
-
725kV及以上电压等级支柱瓷绝缘子运行规范.docx
-
1144甑底链板机说明书.docx
-
100个著名初等数学问题.docx
-
201X中学寒假工作计划范文.docx
-
111 生物的特征 练习 人教版七年级上册生物.docx
-
110KV变电所设计变压器翻译.docx
-
9920第二学期学校工作总结.docx
-
0911二级技能解答.docx
-
33415设计说明书正文.docx
-
311教育学基础综合大纲.docx
-
201浙江普通高校招生选考科目考试地理试题和答案解析.docx
-
C语言程序的设计实验实验指导书及答案.docx
-
272相似三角形的性质和判定.docx
-
ACCAHA不稳定型心绞痛和非ST段抬高心肌梗死治疗指南修订版摘要.docx
-
baosteel标准对照 外标含量.docx
-
M1模拟练习题.docx
-
ARM体系课程设计实验报告.docx
-
Android面试题整理.docx
-
gaoer.docx
-
CPⅢ测设方案.docx
-
小学生个人先进事迹材料精选多篇.docx
-
小学生随地吐痰检讨书.docx
-
银行开门红表态发言稿.docx
-
银行支行经营绩效考核机制改进研究某市商业银行分行个案.docx
-
英克系统操作手册第一版.docx
-
小学四年级语文《秉笔直书》教案.docx
-
小学五年级数学工作总结6篇.docx
-
小学新标准英语三年级起点第五册.docx
-
小学一年级一周评语一年级小学生评语大全.docx
-
小学语文《猫》教学设计学情分析教材分析课后反思.docx
-
硬笔基本笔画教案.docx
-
用电信息采集装置安装工程指导.docx
-
优化方案版高中语文第一单元单元综合检测新人教版必修4.docx
-
校园活动策划书范文1.docx
-
优质文档市场策划书4篇word版本 17页.docx
-
油气输送管道与铁路交汇工程技术及管理规定 doc.docx
-
学年语文S版小学五年级语文第二学期全册教案.docx
-
学前教育专业个人实习总结多篇范文.docx
-
浙江高考各梯度作文选.docx
