 社会统计学公式汇总和要点.doc
社会统计学公式汇总和要点.doc
- 文档编号:10502257
- 上传时间:2023-02-15
- 格式:DOC
- 页数:4
- 大小:276.54KB
社会统计学公式汇总和要点.doc
《社会统计学公式汇总和要点.doc》由会员分享,可在线阅读,更多相关《社会统计学公式汇总和要点.doc(4页珍藏版)》请在冰豆网上搜索。
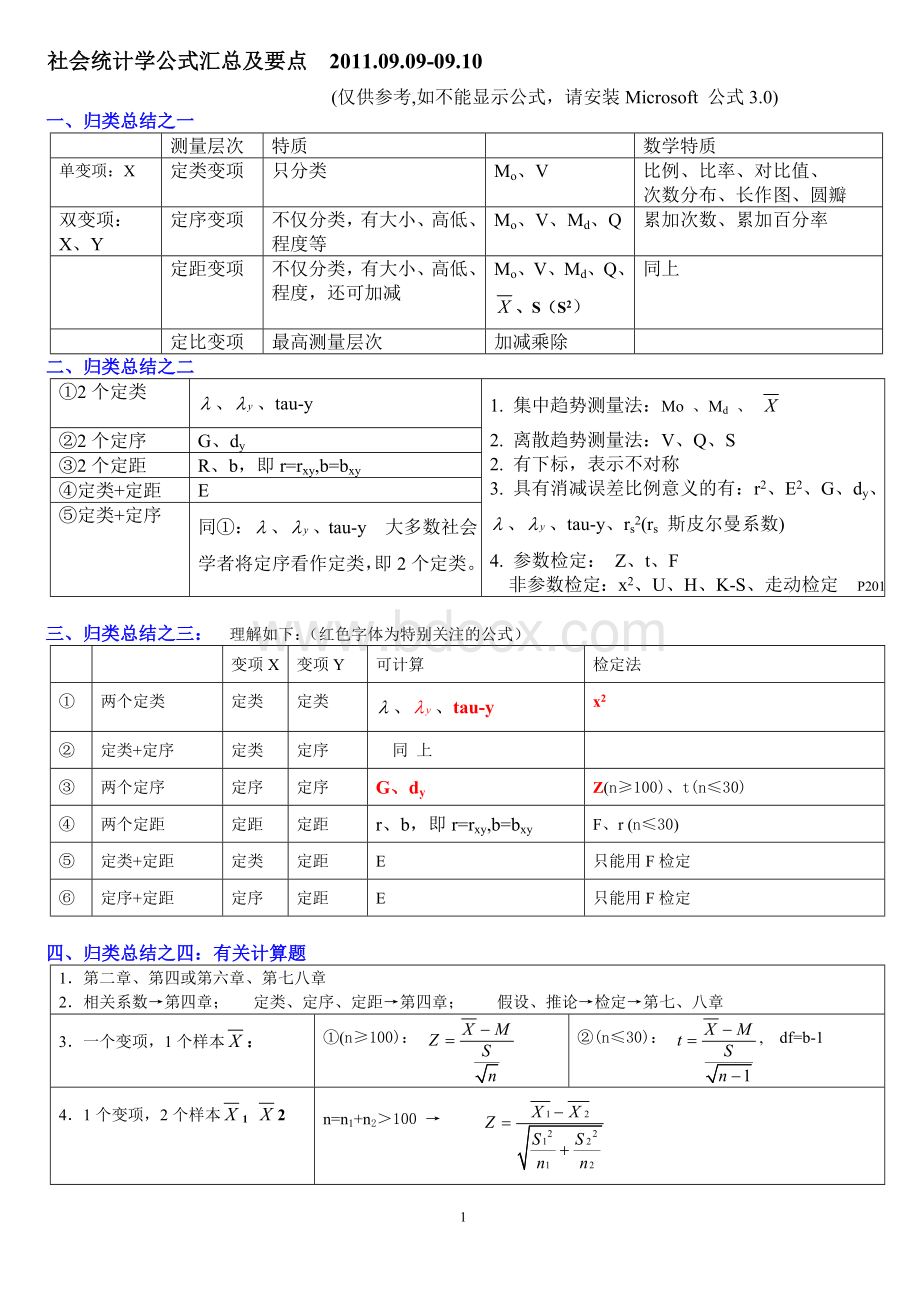
社会统计学公式汇总及要点2011.09.09-09.10
(仅供参考,如不能显示公式,请安装Microsoft公式3.0)
一、归类总结之一
测量层次
特质
数学特质
单变项:
X
定类变项
只分类
Mo、V
比例、比率、对比值、
次数分布、长作图、圆瓣
双变项:
X、Y
定序变项
不仅分类,有大小、高低、程度等
Mo、V、Md、Q
累加次数、累加百分率
定距变项
不仅分类,有大小、高低、程度,还可加减
Mo、V、Md、Q、、S(S2)
同上
定比变项
最高测量层次
加减乘除
二、归类总结之二
①2个定类
、、tau-y
1.集中趋势测量法:
Mo、Md、
2.离散趋势测量法:
V、Q、S
2.有下标,表示不对称
3.具有消减误差比例意义的有:
r2、E2、G、dy、、、tau-y、rs2(rs斯皮尔曼系数)
4.参数检定:
Z、t、F
非参数检定:
x2、U、H、K-S、走动检定P201
②2个定序
G、dy
③2个定距
R、b,即r=rxy,b=bxy
④定类+定距
E
⑤定类+定序
同①:
、、tau-y大多数社会学者将定序看作定类,即2个定类。
三、归类总结之三:
理解如下:
(红色字体为特别关注的公式)
变项X
变项Y
可计算
检定法
①
两个定类
定类
定类
、、tau-y
x2
②
定类+定序
定类
定序
同上
③
两个定序
定序
定序
G、dy
Z(n≥100)、t(n≤30)
④
两个定距
定距
定距
r、b,即r=rxy,b=bxy
F、r(n≤30)
⑤
定类+定距
定类
定距
E
只能用F检定
⑥
定序+定距
定序
定距
E
只能用F检定
四、归类总结之四:
有关计算题
1.第二章、第四或第六章、第七八章
2.相关系数→第四章;定类、定序、定距→第四章;假设、推论→检定→第七、八章
3.一个变项,1个样本:
①(n≥100):
②(n≤30):
df=b-1
4.1个变项,2个样本12
n=n1+n2>100→
五、归类总结之五:
有关消减误差比例
1.
有消减误差比例意义,且对称
、G、Q拉系数、rs2、r2、rxy.12、、Ry.122=Ry.x1x22
2.
有消减误差比例意义,且不对称
dy、、tau-y、E2、CR2(特征值)
3.
无消减误差比例意义,且对称
、V系数、C系数、tau-a、tau-b、tau-c、Vs、r
4.
无消减误差比例意义,且不对称
b、E
六、其他细节
1.显著度的表达
①两端检定:
;②一端检定:
;③;④F(df1,df2);⑤x2(df)
2.有无自由度的表达
G、r、F、x2结果解释加上“其显著度水平达到或没有达到……水平”
3.有关r净相关系数
(两个定距变项)
r=rxy.1——引入第三个变项时对X、Y变项产生共同影响。
rx(y-1)——引入第三个变项时,只对Y产生影响,无消减误差意义。
ry(x-1)——引入第三个变项时,只对X产生影响,无消减误差意义。
计算公式表
(一)⑥①②③④⑤⑥(红色字体为特别关注的公式)
1.众值
Mo=次数最多之值。
2.中位项
Md位置=,Md=L+W,Md=L+W
有三种情况:
单个数奇、偶、区间。
fm:
原始次数;cfm-1:
累加次数P48
3.均值
=P49
4.离异比率
V==P52
5.四分位差
由低到高排列,分四个等分计算Q1、Q3位置,Q1位置=,Q3位置=,
Q=Q3-Q1
有单个数(n为偶数时会出现偏离)、区间之分。
(有几种Q,就有几种S计算法)
当为区间表格时(n/4)
①计算向上累加数cf;②Q1位置=,Q3位置=;
③Q1=L1+W1,Q3=L3+W3;④Q=Q3-Q1P57
5.标准差
①单个数:
S=,②区间:
S=P60
对S的解释:
如以均值来估计各个个案的数值,所犯的错误平均是S。
用均值作估计变项数值时所犯错误的大小。
S2方差:
就是标准的平方值,其意义与标准差相同。
计算公式表
(二)二个变项
1.两个
定类变项
①
②
My=Y变项的众值次数,Mx=X变项的众值次数,n=全部个案数目。
my=X变项的每个值(类别)之下Y变项的众值次数,mx=Y变项的每个值之下X变项的众值次数,
③tau-y=(E1=,E2=)
n=全部个案数目,f=某条件次数,Fy=Y变项的某个边缘次数,Fx=X变项的某个边缘次数。
2.两个
定序变项
G=
Ns是同序对数,Nd是异序对数对G检定,只有两种检定法:
Z、t。
dy=
Ns是同序对数,Nd是异序对数,
Ty是只在依变项Y上同分的对数。
因为dy系数是以X预测Y,如果两个个案在X上有高低之分,就要预测或估计他们在Y上的相对等级。
因上分母要加上Ty。
rs=
斯皮尔曼rho系数。
常出现在填空选择,一般不考计算题。
3.两个
定距变项
Y’=bX+a,a=—b=简单线性回归分析
X是自变项数值,自变项数值,b是回归系数,表示回归张的斜率,a是截距,即回归线与Y轴的交点,Y’是根据回归方程式所预测的Y变项的值。
r=rxy=
积矩相关测量法
r系数与简单线性回归分析都是假定X与Y的关系具有直线的性质。
4.
定类+定项
,ni是每个自变项Xi的个案数目。
=每类的平均值,每个竖列平方的和。
E值无负值,因为是定类变项。
相关比率与非线性相关
又称为eta平方系数(E2),是以一个定类变项X为自变项,以一个定距变项Y为依变项。
是根据自变项的每一个值来预测或估计依变项的均值。
E是假定X是非线性关系。
E值从0-1,其E2具有消减误差的意义。
5.定类+定序
=两个定类,大部分的社会学研究都采用Lambda或tau-y系数来测量
6.定序+定距
因此社会学家常改用相关比率——即将定序变项看做是定类变项。
E
参数值的估计:
间距估计:
均值、百分率、积矩相关
求总体的均值M
①已知:
n,(样本的均值),可信度为95%,求M。
(S是样本的标准差)
③已知:
n,可信度95%,样本比率p,求总体比率P。
(百分率(或比例)的间距估计)
②已知:
,可信度,M或e,求n。
(决定样本的大小)
④已知:
可信度,p,
Pore,求n。
计算公式表(三)假设的检定:
两个变项之相关Z(5个)、t(4)、F(2个)
Z检定法(大样本)、t检定法(小样本):
定矩变项、随机抽样、总体正态分布。
1、Z检定法
2、t检定法
①(大样本)
n≥100(单均值)
①(小样本)n≤30
以t值来表示样本的均值在标准化抽样中分布中的位置。
②两个均值的
差异
n=n1+n2≥100
②两个小样本
n1+n2<100
,
df=(n1-1)+(n2-1)=(自由度)
③单百分率
(单均值)
③小样本n≤30
八:
P188
,df=Ns+Nd-2
④两个百分率的差异
一个变项两个样本的比率。
两个随机样本百分率之相差的抽样分布接近正态分布。
分母就是标准误差。
⑤Z对G的检定
八:
P188-189
3、F检定(方差分析)
4、x2检定(非参数检定法)
①F对E检定
df1=k-1,df2=n-k。
(df1=1,df2=n-2)
自由度df=(r-1)(c-1)
(r—横c—列)
都是定类变项,用来检定是否相关。
H1:
X与Y相关
H0:
X与Y不相关
(总体中)
X
12
A1A2
(A1、A2:
X的边续次数:
行)
(B1、B2:
Y的边续次数:
列)
②由E派生
③F对r检定
其中:
f是根据所抽取的样本而计算出来的实际次数,
e是与每个实际次数相应的预期次数,
A与B分别是X与Y两个变项的边缘次数,
n是样本大小,r与c分别是表的行数与列数。
4


- 配套讲稿:
如PPT文件的首页显示word图标,表示该PPT已包含配套word讲稿。双击word图标可打开word文档。
- 特殊限制:
部分文档作品中含有的国旗、国徽等图片,仅作为作品整体效果示例展示,禁止商用。设计者仅对作品中独创性部分享有著作权。
- 关 键 词:
- 社会 统计学 公式 汇总 要点
 冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
冰豆网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 党组织、党员联系服务师生工作制度.docx
党组织、党员联系服务师生工作制度.docx
 物流与供应链管理 第七章 供应链综合计划.pptx
物流与供应链管理 第七章 供应链综合计划.pptx
-
民族团结教案doc格式.docx
-
民族团结教案doc格式.docx
-
中国象棋ppt模板.pptx
-
设备质量保证措施.docx
-
电力公司招聘行政能力测试试题及解析.docx
 回弹仪检测多孔砖砖强度计算表.xls
回弹仪检测多孔砖砖强度计算表.xls
-
汽车理论1.3.doc
-
电动汽车充换电站项目商业计划书.doc
-
幼儿园指南试题及答案.doc
-
护理教案模板.doc
-
资料台账表格.xlsx
-
红军长征的历史叙述是怎样形成的.docx
-
冷库工程合同.docx
-
部编版五年级上册语文课堂作业本答案(全).docx
-
《网络综合布线》说课稿.doc
-
材料进场,见证取样及检验制度.docx
-
20章--瓦斯综合利用.doc
-
[原创]STP保温板屋面及外墙保温施工技术方案.doc
-
隧道开挖作业台车计算书.docx
-
《减法的初步认识》教学设计.doc
-
教导处工作计划.docx
-
电机学第五版课后答案汤蕴璆完整版.docx
-
同仁堂案例成功启示.docx
-
经典钣金结构设计规范.doc
-
计算机各种进制转换练习题(附答案).doc
-
市场营销教学案例分析.docx
-
服装厂质量管理制度.docx
-
中职试验教材应用文写作(高教版_王崇国编)电子教案【全】.doc
-
控烟考评奖惩制度、标准、记录表.doc
-
小学生“学宪法-讲宪法”活动知识竞赛题库(含答案).docx
-
复印社实习报告文档3篇.docx
-
时尚摄影师数码备.docx
-
软件正版化工作指南可编辑修改word版.docx
-
简明教案模板.docx
-
私人定制商业计划书.docx
-
人教版度中考二模化学试题A卷.docx
-
品牌厨房用品电子商务投资运营销售项目商业计划书.docx
-
农资监管与服务平台方案.docx
-
精通英语六上Unit 1英语教案.docx
-
生产企业员工手册范本.docx
-
危险废物污染环境防治责任规章制度样式.docx
-
计量管理制度全部.docx
-
更新国家开放大学电大《商法》机考9套真题题库及答案.docx
-
口才班演出主持词.docx
-
近现代史纲要实践报告游梁启超纪念馆.docx
-
激光原理名词解释.docx
-
第三章存货 习题答案.docx
-
江苏省南京市学年高三上学期期初调研地理试题解析版.docx
-
钢板桩支护方案化粪池支护.docx
